爬虫入门 beautifulsoup库(一)
先贴一个beautifulsoup的官方文档,https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id12
requests库用来获取url的响应,但是获取到确实网页代码,为了拿到自己想要的东西,我们需要用一下beautifulsoup这个库,这个库能把想要的东西提取出来。
下载和安装在官方文档里都有,这里还要说一下解析器。beautifulsoup这个库除了支持python标准库中的HTML解析器,还支持其他类似,lxml和html5lib。

上面这张表来自官方文档,选择哪种解析器就因人而异了。
接下来进入正文,首先要构造一个对象,用soup = BeautifulSoup(html,'lxml'),这html可以是事先用requests库请求来的,也可以是自己写的,当然,也可以用soup = BeautifulSoup(open("index.html"))这种方法打开自己html。
然后就是去查看那个html,当html里有a标签时,用soup.a即可输出遇到的第一条a标签,同理,也可以soup.title输出html的title标签。
仅仅是第一个标签那么满足不了我们的需求,我们需要所有的标签里的数据就需要用到findAll这个方法啦,用all_a=soup.findAll('a'),即可获得所有的a标签,但是这时候的输出都是带着a标签的,想要只获得内容,有需要用到string方法,all_a.string,即可。
话不多说,先试着把小米官网中的h2标签,即小标题给爬取下来试试
from bs4 import BeautifulSoup
import lxml
import requests url = 'https://www.mi.com/'
try:
#模拟浏览器
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url , headers = kv)
#状态码检查,用于
r.raise_for_status()
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,'lxml')
for tag in soup.findAll('h2'):
print(tag.string)
except:
("爬取失败")
然后再讲讲string方法,在官方文档中的解释是这样的
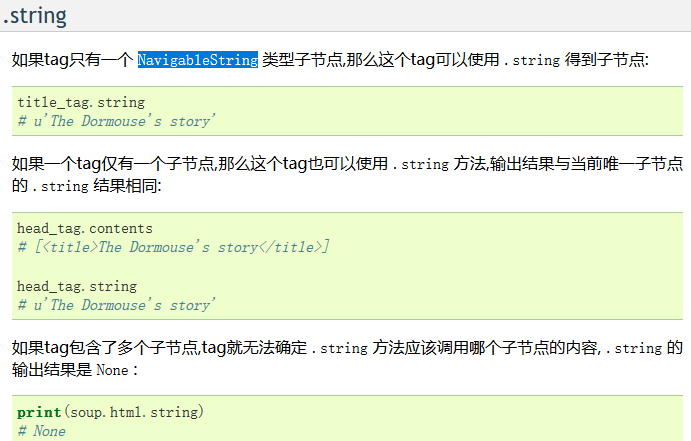
简单的说就是,当你获取的标签里没有别的标签了,你调用这个方法会输出这个标签里的内容,但这个标签里如果有其他的小标签和内容时,返回一个none值,比如说再爬取小米的a标签时、

这一条数据返回的就是none值
我们爬取数据的时候有时会把空白爬进去,但是又不想要空白的时候可以用.stripped_strings方法去除掉空白
然后讲一讲定位就比如说上面那条带着i标签的a标签,我们可以先找到i标签,在用他的父节点输出a标签,用。parent的方法,同理,通过 .next_siblings 和 .previous_siblings 属性可以找到当前节点的兄弟节点
爬虫入门 beautifulsoup库(一)的更多相关文章
- 爬虫之BeautifulSoup库
文档:https://beautifulsoup.readthedocs.io/zh_CN/latest/ 一.开始 解析库 # 安装解析库 pip3 install lxml pip3 instal ...
- python简单页面爬虫入门 BeautifulSoup实现
本文可快速搭建爬虫环境,并实现简单页面解析 1.安装 python 下载地址:https://www.python.org/downloads/ 选择对应版本,常用版本有2.7.3.4 安装后,将安装 ...
- Python爬虫之BeautifulSoup库
1. BeautifulSoup 1.1 解析库 1)Python标准库 # 使用方法 BeautifulSoup(markup, "html.parser") # 优势 Pyth ...
- Python爬虫入门 Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 2, from bs4 import Be ...
- python爬虫入门urllib库的使用
urllib库的使用,非常简单. import urllib2 response = urllib2.urlopen("http://www.baidu.com") print r ...
- 爬虫入门 requests库
写在最前的具体资料: https://2.python-requests.org//zh_CN/latest/user/quickstart.html https://www.liaoxuefeng. ...
- python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式. 我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
随机推荐
- 安装jupyter使用notebook
安装jupyter pip3 install jupyter --default-timeout=1000 -i https://pypi.tuna.tsinghua.edu.cn/simple 使用 ...
- H5-设置全屏背景图片样式
.bgimg{ width: 100%; height: 95vh; margin: 0; padding: 0 .32rem; background-image: url('../image/ld. ...
- String类型的日期怎么转化为Date类型
在一个SQL中,如果同时使用rownum和order by,会有一个先后顺序的问题. 比如select id1,id2 from t_tablename where rownum<3 order ...
- JavaScript 中的构造函数
典型的面向对象编程语言(比如C++和Java),存在“类”(class)这个概念.所谓“类”就是对象的模板,对象就是“类”的实例.但是,在JavaScript语言的对象体系,不是基于“类”的,而是基于 ...
- centos7上python3.6.5的安装及卸载
前言 最近开始安装配置公司给我的台式机,加上刚刚购买的ECS,处女座的我,环境前前后后大概装了有十来次吧,之前装总是临时网上找教程,但是装下来总是感觉有点别扭,当时服务器装的是3.6.5,虚拟机装的是 ...
- BZOJ 3280: 小R的烦恼
Description 小R最近遇上了大麻烦,他的程序设计挂科了.于是他只好找程设老师求情.善良的程设老师答应不挂他,但是要 求小R帮助他一起解决一个难题.问题是这样的,程设老师最近要进行一项邪恶的实 ...
- windows批量删除同名进程
这里以删除chromedriver.exe 黑窗口执行命令:taskkill /F /IM chromedriver.exe 任务管理器发现,内存使用迅速指数下降
- C语言 continue
C语言 continue 在循环语句中,如果希望立即终止本次循环,并执行下一次循环,此时就需要使用continue语句. 案例 #include<stdio.h> int main() { ...
- 【Python】表白程序
程序链接:https://www.lanzous.com/i8xj5mh # 打包操作 # 安装pyinstaller # cmd输入 pip install pyinstaller # shift ...
- 使用VSCode创建简单的Razor Webapp--1.入门
1.下载vscode,安装dotnet core sdk 在cmd中使用命令dotnet --version可以查看当前安装的版本 2.打开vscode,设置语言和扩展 在最左边的工具栏,点击最下面的 ...