爬虫入门 beautifulsoup库(一)
先贴一个beautifulsoup的官方文档,https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id12
requests库用来获取url的响应,但是获取到确实网页代码,为了拿到自己想要的东西,我们需要用一下beautifulsoup这个库,这个库能把想要的东西提取出来。
下载和安装在官方文档里都有,这里还要说一下解析器。beautifulsoup这个库除了支持python标准库中的HTML解析器,还支持其他类似,lxml和html5lib。

上面这张表来自官方文档,选择哪种解析器就因人而异了。
接下来进入正文,首先要构造一个对象,用soup = BeautifulSoup(html,'lxml'),这html可以是事先用requests库请求来的,也可以是自己写的,当然,也可以用soup = BeautifulSoup(open("index.html"))这种方法打开自己html。
然后就是去查看那个html,当html里有a标签时,用soup.a即可输出遇到的第一条a标签,同理,也可以soup.title输出html的title标签。
仅仅是第一个标签那么满足不了我们的需求,我们需要所有的标签里的数据就需要用到findAll这个方法啦,用all_a=soup.findAll('a'),即可获得所有的a标签,但是这时候的输出都是带着a标签的,想要只获得内容,有需要用到string方法,all_a.string,即可。
话不多说,先试着把小米官网中的h2标签,即小标题给爬取下来试试
from bs4 import BeautifulSoup
import lxml
import requests url = 'https://www.mi.com/'
try:
#模拟浏览器
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url , headers = kv)
#状态码检查,用于
r.raise_for_status()
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,'lxml')
for tag in soup.findAll('h2'):
print(tag.string)
except:
("爬取失败")
然后再讲讲string方法,在官方文档中的解释是这样的
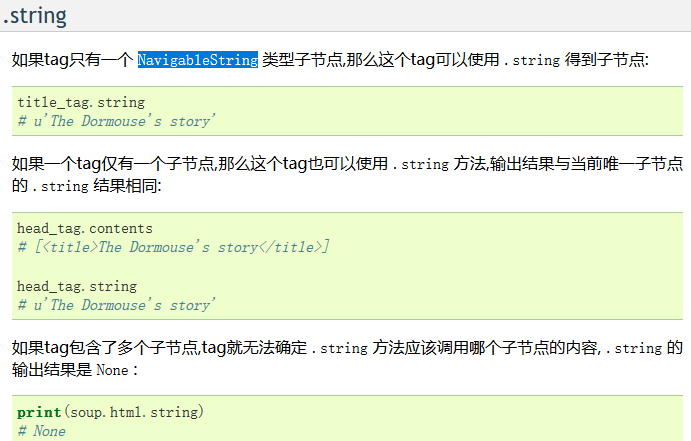
简单的说就是,当你获取的标签里没有别的标签了,你调用这个方法会输出这个标签里的内容,但这个标签里如果有其他的小标签和内容时,返回一个none值,比如说再爬取小米的a标签时、

这一条数据返回的就是none值
我们爬取数据的时候有时会把空白爬进去,但是又不想要空白的时候可以用.stripped_strings方法去除掉空白
然后讲一讲定位就比如说上面那条带着i标签的a标签,我们可以先找到i标签,在用他的父节点输出a标签,用。parent的方法,同理,通过 .next_siblings 和 .previous_siblings 属性可以找到当前节点的兄弟节点
爬虫入门 beautifulsoup库(一)的更多相关文章
- 爬虫之BeautifulSoup库
文档:https://beautifulsoup.readthedocs.io/zh_CN/latest/ 一.开始 解析库 # 安装解析库 pip3 install lxml pip3 instal ...
- python简单页面爬虫入门 BeautifulSoup实现
本文可快速搭建爬虫环境,并实现简单页面解析 1.安装 python 下载地址:https://www.python.org/downloads/ 选择对应版本,常用版本有2.7.3.4 安装后,将安装 ...
- Python爬虫之BeautifulSoup库
1. BeautifulSoup 1.1 解析库 1)Python标准库 # 使用方法 BeautifulSoup(markup, "html.parser") # 优势 Pyth ...
- Python爬虫入门 Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 2, from bs4 import Be ...
- python爬虫入门urllib库的使用
urllib库的使用,非常简单. import urllib2 response = urllib2.urlopen("http://www.baidu.com") print r ...
- 爬虫入门 requests库
写在最前的具体资料: https://2.python-requests.org//zh_CN/latest/user/quickstart.html https://www.liaoxuefeng. ...
- python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式. 我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
随机推荐
- Flask之RESTFul API前后端分离
Flask之RESTFul API前后端分离 一:虚拟环境搭建的两种方式 1 pipenv的使用 pip install --user pipenv安装pipenv在用户目录下 py -m site ...
- 【Python可视化】超详细Pyecharts 1.x教程,让你的图表动起来~
前言 pyecharts 是一个用于生成 Echarts 图表的Python库.Echarts是百度开源的一个数据可视化 JS 库,可以生成一些非常酷炫的图表. Pyecharts在1.x版本之后迎来 ...
- Jmeter-集合点与关联
1.集合点 添加同步定时器(Synchronizing Timer) 注意:集合点需要放在需要集合的元件前面 2.关联 预先使用Badboy录制WebTours登录脚本 在登录前插入一个监听器:察看结 ...
- Wannafly Camp 2020 Day 1C 染色图 - 组合数学,整除分块
定义一张无向图 G=⟨V,E⟩ 是 k 可染色的当且仅当存在函数 f:V↦{1,2,⋯,k} 满足对于 G 中的任何一条边 (u,v),都有 f(u)≠f(v). 定义函数 g(n,k) 的值为所有包 ...
- 解决Oracle ORA-01033: ORACLE initialization or shutdown in progress错误 和 ORA-01589错误 要打开数据库则必须使用 RESETLOGS 或 NORESETLOGS 选项
要打开数据库则必须使用 RESETLOGS 或 NORESETLOGS 选项 SQL> startupORACLE 例程已经启动. Total System Global Area 13533 ...
- java 学习(day1)
之前学java没好好听课,会一点又不熟练,于是准备重新开始学一些细节,记录每日所学新知识. a+b java的a+b很有意思,当你输出的是" "+a+b,先假设a=2,b=3.然后 ...
- Java 11 新垃圾回收器 ZGC
可伸缩.低延迟的垃圾回收器 GC 暂停时间不超过 10ms 堆管理容量范围(小M级别,大到T级别) 对应用吞吐量影响不超过15%(对比 G1) 为进一步的添加新特性和优化做基础 默认支持 Linux/ ...
- Hive学习笔记二
目录 Hive常见属性配置 将本地库文件导入Hive案例 Hive常用交互命令 Hive其他命令操作 参数配置方式 Hive常见属性配置 1.Hive数据仓库位置配置 1)Default数据仓库的最原 ...
- TD - 多选框 - CheckBox
模板 模板1:TD //Html - checked="true" 默认选中 <input dojoType="bootstrap.form.CheckBox&qu ...
- MATLAB一些常用的function
在MATLAB中一些常用的算数符号与我们平时所用的不同,比如:根号,平方,e,以及对数函数等. (1)平方:a^2 意思为a的平方,亦可以写成a*a: (2)根号:sqrt(x)意思为对x开根号,x既 ...