一致性 Hash 学习与实现
普通的 Hash 解决的是什么问题?
下图是一个普通的余数法构造的哈希表。
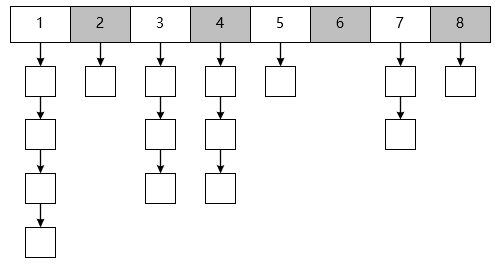
一般在编程中使用哈希表,某个 bucket 突然就没了的概率比较小,常见的是因为负载因子太大需要增加 bucket,然后 rehash。
考虑在上图中,2 号 bucket 突然就没了会发生什么情形。
最直接的做法就是,后面的 bucket 依次往前面补位,然后重新计算 key 的 hash 值。
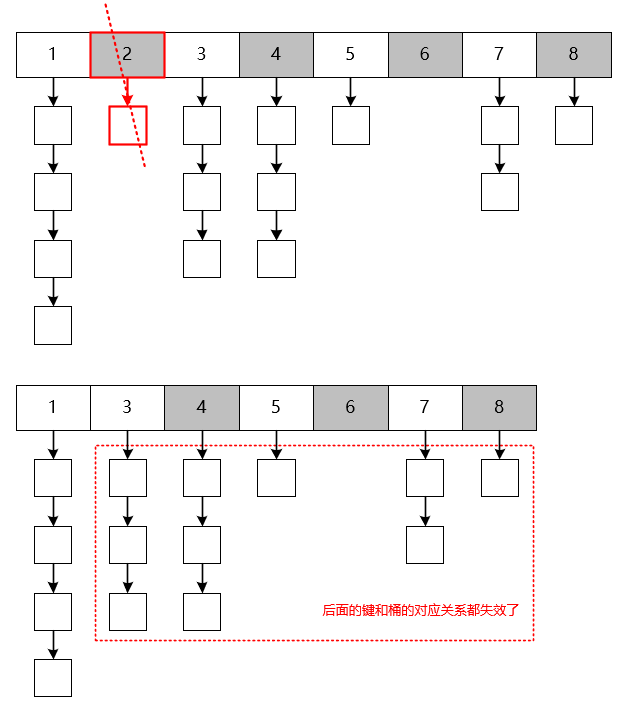
2 号 bucket 虽然只存放了一个 key,但是由于 2 号 bucket 的丢失,导致后面所有 bucket 存放的 key 的映射关系都失效了。
如果这个 hash 表在内存中,无非就是 rehash 一下,重新建立对应关系,问题不大。
但如果这种情况发生在分布式缓存中呢?这会导致大量的缓存失效,有可能导致很多请求直接冲到后端。
想想看,本来想用分布式缓存扛流量,结果仅仅因为其中一台缓存服务器挂掉了而导致整个缓存系统不可用,太脆弱了。
问题在于:每一个 key 映射到 bucket 的规则太精确了,完全没有余地,每个 bucket 挨得太密。对 key 计算完后的 hash 值直接指向了 bucket。
我是这么理解的,这种 Hash 表就好像多米诺骨牌,只要把其中的一块推倒,那么直接到后面的多米诺骨牌都倒了(对应的就是映射关系全失效了)。
一致性 Hash 是怎么解决这个问题的呢?
1997 年,麻省理工学院(MIT)的 David Karger 等 6 个人发布学术论文:
《Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web》
中文翻译就是:一致性哈希和随机树:用于缓解万维网上热点的分布式缓存协议。
我想用我的理解来讲,接上面提到的看法是,这些 bucket 都挨得太紧密了,那这样得话,我何不就把每个 bucket 的距离搞得足够长呢?
原来 Hash 表的长度可能是 57,103,947,或者 2053 这种质数。
这次我玩一把大的,直接 Hash 表的长度是 2^32-1,然后把桶分布在这个上面,大概长这样:
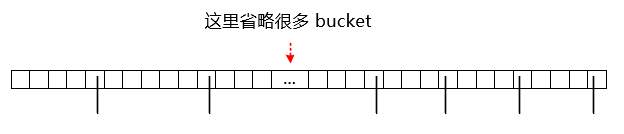
我不太喜欢用环来描述,脑子不太好使,还是用最简单的数组描述把。
虽然这个一致性 Hash 表很长,但是真正用来装数据的 bucket 不多,bucket 通过 hash 算法(方法有很多)能均匀分布到这个很长的数组中。
一个 key 准备存取或者查找的过程是这样的:
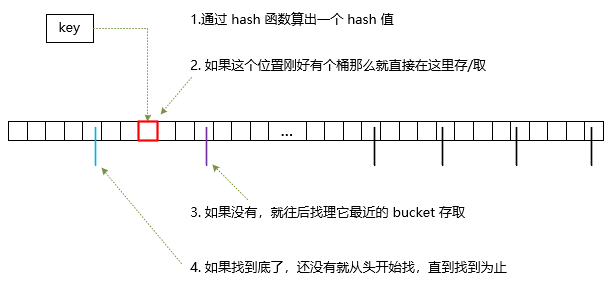
怎么样,是不是很简单?不过事情还没完。
这样的好处就是,bucket 之间是隔离开的,增加或者减少 bucket 只会对局部有影响,不会影响到全局,具体自己去分析吧。
一致性 Hash 倾斜的问题
如果说实际的 bucket 本来就很少呢?这样会导致大量的键和某个 bucket 建立映射,key 分布不均匀。
这里的解决方法挺厉害的,就是虚拟 bucket,也就是我一个实际的 bucket 可以虚拟出很多个 bucket 来,那么这些虚拟的 bucket 只是名字和实际 bucket 不一样。
然后虚拟节点也会挂在 Hash 表中,类似这样的:
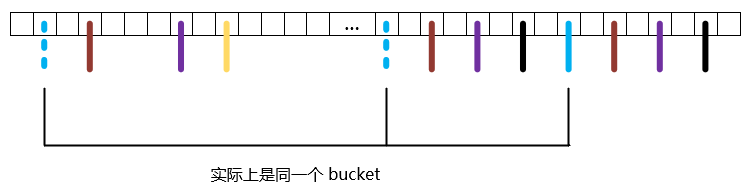
虚拟出来的节点越多,key 的分布越均匀。
总结
1. 隔离不同的 bucket,bucket 的增加或者减少只对局部有影响
2. 虚拟节点解决 key 分布不均匀
算法没有思想重要!
我想看了上面这些,应该可以自己写一个简单版的 Consistent Hash 了。下次我写个很 low 逼的给你们看看。
一致性 Hash 学习与实现的更多相关文章
- 一致性hash学习
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简 单哈 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- swift学习之一致性hash
转自:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- Java 一致性Hash算法的学习
目前我们很多时候都是在做分布式系统,但是我们需把客户端的请求均匀的分布到N个服务器中,一般我们可以考虑通过Object的HashCodeHash%N,通过取余,将客户端的请求分布到不同的的服务端.但是 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- Java实现一致性Hash算法深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中”一致性Hash算法”部分,对于为什么要使用一致性Hash算法和一致性Hash算法的算法原 ...
- 百度资深架构师带你深入浅出一致性Hash原理
一.前言 在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用. 但是普通的余数h ...
- 分布式一致性hash算法
写在前面 在学习Redis的集群内容时,看到这么一句话:Redis并没有使用一致性hash算法,而是引入哈希槽的概念.而分布式缓存Memcached则是使用分布式一致性hash算法来实现分布式存储. ...
随机推荐
- 2108 ACM 向量积 凹凸
题目:http://acm.hdu.edu.cn/showproblem.php?pid=2108 图一中,向量a × 向量 b 根据右手定则,得出向量c的方向.即为凸多边形. 图二中,若向量a ...
- 免花生壳 TCP测试 DTU测试 GPRS测试TCP服务器
通常在学习GPRS或者DTU的时候,往往没有自己的服务器,很多时候我们只能用这个模块打个电话发个短信,但是随着移动互联的兴起,各行各业大家都开始弄移动接入.为了这个需求,这里提供TCP移动接入. 工作 ...
- 学不动了,ECMAScript2018都来了
原文:ECMAScript regular expressions are getting better! 作者: Mathias Bynens: Google V8引擎开发者 译者:Fundebug ...
- JS面向对象之创建对象模式
虽然Object构造函数或对象字面量都可以用来创建单个对象,但都有一个缺点,使用同一个接口来创建对象,会产生大量重复的代码,为解决这个问题,引出下列方法 1.工厂模式 抽象了创建具体对象的过程,用函数 ...
- 3ds max学习笔记-- 动画
栗子:若要使茶壶从a点运动到b点,是需要动画实现的:动画与传统意义的移动不同,与时间是存在关系的: 时间线,时间滑条: [时间配置]按钮: 弹出面板: 动画时间轴默认时间是从0帧开始100结束:总长度 ...
- 用列表实现一个简单的图书管理系统 python
#coding=utf-8 book_list=[] #图书馆所有书 unborrowed_book=[] #可借阅的书 borrowed_book=[] #已经借出去的书 def add(): ...
- linux 下通过xhost进入图形界面,经常会出现报错“unable to open display”
linux 下通过xhost进入图形界面,经常会出现报错“unable to open display” linux下的操作步骤如下: [root@localhost ~]# vncserver N ...
- GMA Round 1 年货
传送门 年货 三角形的年货有没有见过啊?(如下图所示,图中共有12层小三角形,共计144个) 啊,不,这不是真正的年货,真正的年货是正六边形的!(这是什么设定?) 总之,麻烦你在图中找出顶点在三角形格 ...
- spring跨域问题
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Co ...
- mount 命令用法
mount 功能: 加载指定的文件系 统:mount可将指定设备中指定的文件系统加载到 Linux目录下(也就是装载点).可将经常使用的设备写入文件/etc/fastab,以使系 统在每次启动时自动加 ...