cookie的中文乱码问题【URL编码解码】
先搞明白为什么会乱码,为什么要转码:
在tomcat 8 之前,cookie中不能直接存储中文数据。需要将中文数据转码,一般采用URL编码(%E3)。
在tomcat 8 之后,cookie支持中文数据。特殊字符还是不支持(比如空格),建议使用URL编码存储,URL解码解析。
编码解码前后字符如下表所示:
| 编码前 | 十进制数字、汉字 |
| 编码后 | 十六进制数字、英文 |
| 解码前 | 十六进制数字、英文 |
| 解码后 | 十进制数字、汉字 |
浏览器与服务器交互过程如图所示:
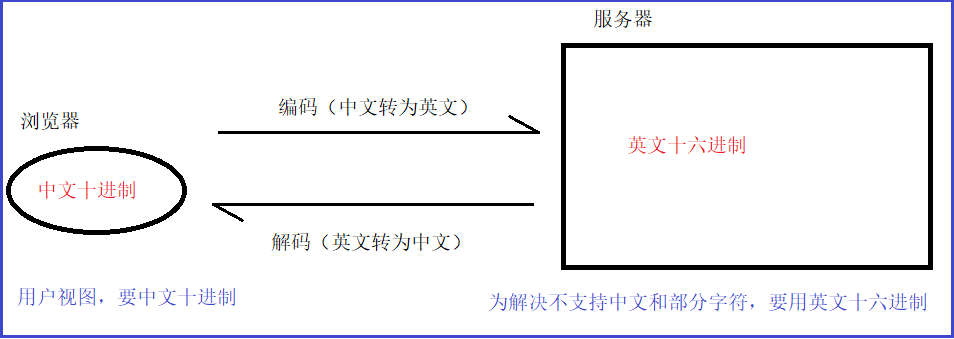
实例代码如下:
servlet中,URL编码解码的的主要代码如下:
import java.net.URLDecoder;
import java.net.URLEncoder;
//--------省略若干代码----------- String str_date = sdf.format(date);//获取当前时间
System.out.println("编码前:"+str_date);
//URL编码
str_date = URLEncoder.encode(str_date,"utf-8");
System.out.println("编码后:"+str_date); //--------省略若干代码----------- String value = c.getValue();//获取cookie的value
System.out.println("解码前:"+value);
//URL解码
value = URLDecoder.decode(value, "utf-8");
System.out.println("解码后:"+value); //--------省略若干代码-----------
全部代码如下:
import java.io.IOException;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.text.SimpleDateFormat;
import java.util.Date; import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse; /**
* Types
* @author dandelion
* @time 2019年3月7日上午10:03:02
* @作用 cookie记录上次访问时间
*/
@WebServlet("/CookieTest")
public class CookieTest extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("UTF-8");
boolean flag=false;//没有name是lastTime的cookie
Cookie[] cs = request.getCookies();
if(cs!=null&&cs.length>0){
for(Cookie c:cs){
String name = c.getName();
if("lastTime".equals(name)){
flag=true;//有name是lastTime的cookie
Date date = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("YYYY年MM月dd HH:mm:ss");
String str_date = sdf.format(date);
System.out.println("编码前:"+str_date);
//URL编码
str_date = URLEncoder.encode(str_date,"utf-8");
System.out.println("编码后:"+str_date);
c.setValue(str_date);
c.setMaxAge(30);
response.addCookie(c);
//相应数据
String value = c.getValue();
System.out.println("解码前:"+value);
//URL解码
value = URLDecoder.decode(value, "utf-8");
System.out.println("解码后:"+value);
response.getWriter().write("<h1>欢迎回来,您上次访问时间是:"+value+"</h1>");
break;
}
}
}
if(cs==null||cs.length==0||flag==false){
Date date = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("YYYY年MM月DD HH:mm:ss");
String str_date = sdf.format(date);
str_date = URLEncoder.encode(str_date, "utf-8");
Cookie c = new Cookie("lastTime", str_date);
c.setMaxAge(300);
response.addCookie(c);
response.getWriter().write("<h1>欢迎你,这是你首次登录</h1>");
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
} }
控制台输出如下:
编码前:2019年03月07 14:28:24
编码后:2019%E5%B9%B403%E6%9C%8807+14%3A28%3A24
解码前:2019%E5%B9%B403%E6%9C%8807+14%3A28%3A24
解码后:2019年03月07 14:28:24
浏览器显示如下:

说明:
日期:2019-03-07 14:35:24
cookie的中文乱码问题【URL编码解码】的更多相关文章
- 【转】asp.net Cookie值中文乱码问题解决方法
来源:脚本之家.百度空间.网易博客 http://www.jb51.net/article/34055.htm http://hi.baidu.com/honfei http://tianminqia ...
- java web url编码解码问题(下载中文名文件)
问题描述:需要url直接访问中文名的文件,类似于在地址栏里直接输入http://localhost:8080/example/丽江旅游攻略.doc 来进行文件下载,tomcat的server.xml文 ...
- WebApi中对请求参数和响应内容进行URL编码解码
项目经测试,发现从IE提交的数据,汉字会变成乱码,实验了网上很多网友说的给ajax加上contentType:"application/x-www-form-urlencoded; char ...
- sed处理url编码解码=== web日志的url处理
URL 编码/解码方法(linux shell实现),方法如下: 1.编码的两种方法: admin@~ 11:14:29>echo '手机' | tr -d '\n' | xxd -plain ...
- ASP.NET中Url编码解码
今天遇到Url编码解码的问题,纠结了一天的时间,结果上网一查才发现太二了我们. 同事写的代码把url用HttpUtility.UrlEncode编码和解码了,本地测试没有问题,部署到服务器上就提示转码 ...
- 解决Linux文档显示中文乱码问题以及编码转换
解决Linux文档显示中文乱码问题以及编码转换 解决Linux文档显示中文乱码问题以及编码转换 使vi支持GBK编码 由于Windows下默认编码是GBK,而linux下的默认编码是UTF-8,所以打 ...
- 编码解码--url编码解码
url编码解码,又叫百分号编码,是统一资源定位(URL)编码方式.URL地址(常说网址)规定了常用地数字,字母可以直接使用,另外一批作为特殊用户字符也可以直接用(/,:@等),剩下的其它所有字符必须通 ...
- Delphi中处理URL编码解码
Delphi中处理URL编码解码 一.URL简单介绍 URL是网页的地址,比方 http://www.shanhaiMy.com. Web 浏览器通过 URL 从 web server请求页面 ...
- Python学习之==>URL编码解码&if __name__ == '__main__'
一.URL编码解码 url的编码解码需要用到标准模块urllib中的parse方法 from urllib import parse url = 'http://www.baidu.com?query ...
随机推荐
- php7 数据导出Excel office 2011中文乱码问题
public function test(){ $data = array( array( 'name' => '对对对', 'score' => 80, 'grade' => '急 ...
- LimeSDR环境安装与测试
虚拟机:ubuntu虚拟机建议4g内存,64g硬盘,usb3.0已开启 //否则编译过程耗尽内存 1 换阿里云源(加速)# deb cdrom:[Ubuntu 16.04 LTS _Xenial Xe ...
- 32 C++常见错误集锦
1 下列程序中,K的值为:6 enum { a,b=5,c,d=4,e }k; K=c; 分析:enum中,首元素不赋值的话,默认为0:后一个元素不赋值的话比前一个元素大1. 2 程序运行正常. # ...
- pip 安装 nexmo
pip install nexmo报错 是因为缺少 libffi-devel 需要 yum install libffi-devel 然后再执行 pip install nexmo 即可成功
- react 调用webIm
记录下遇到的问题,之前引用腾讯云的webim,一直出错,现在改好了, 引用了, 以上是在public下的index.html引用, 但是在子模块console.log(webim);会报这个错 解决也 ...
- Nginx 单个进程允许的最大连接数
(1) 控制 Nginx 单个进程允许的最大连接数的参数为 worker_connections ,这个参数要根据服务器性能和内存使用量来调整 (2) 进程的最大连接数受 Linux 系统进程的最大打 ...
- 【PL/SQL基础知识】结构
1.pl/sql块的结构 declare --声明的变量.类型.游标 begin --程序的执行部分(类似于java的main()方法) exception --针对begin块中出现的异常 ---w ...
- Oracle 导出的表不全,以及数据库版本不同导入报错
公司有两个环境下的数据库,版本不同,一个是11g r2,另一个是10g r2 首先在11g r2下用exp导出数据库备份文件,发现部分表缺失. 原来这部分表是空的,11G中新特性,当表无数据时,不分配 ...
- 第七十九课 最短路径(Floyd)
程序如下: #ifndef GRAPH_H #define GRAPH_H #include "Object.h" #include "SharedPointer.h&q ...
- MarkDown学习——基础用法
目录 MarkDown开发版本MD2All基础用法 此处有代码<a id="top"></a>作为页内锚点 此处是用自动生成的目录 MarkDown是什么M ...