如何使用强化学习算法解决贪吃蛇问题(Neural Network Learns to Play Snake)
相关:
Neural Network Learns to Play Snake
https://github.com/greerviau/SnakeAI/
RL算法是有很多baseline算法的,算法library也是比较多的,因此使用ML/RL求解贪吃蛇问题的难点其实在于问题建模而不是使用RL方法求解。
在上面的相关链接中可以知道,这里面的建模方法为:
我们建设蛇的头可以发射8个射线,分别是8个方向,间隔45度角,具体如下:
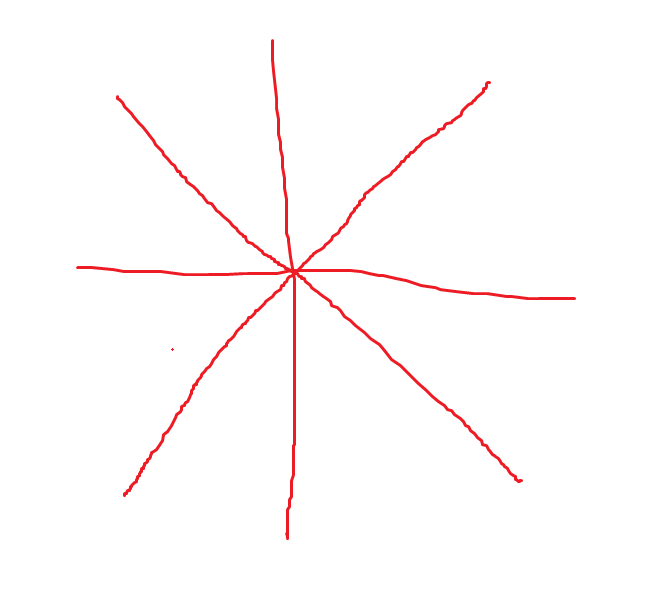
每个射线返回三个数值,分别是这个射线方向上食物、蛇身体、墙体到蛇头的距离,由此可以得到8*3=24个数值,该数值组成输入向量,输入到神经网络中,表示当前的蛇的状态,这样就完成了贪吃蛇的问题建模。
注意:
该问题的建模中蛇的头是没有方向的,也就是说蛇头是没有朝向的,蛇头可以想象为一个点,游戏中是以一个方格的形式出现。
Vision
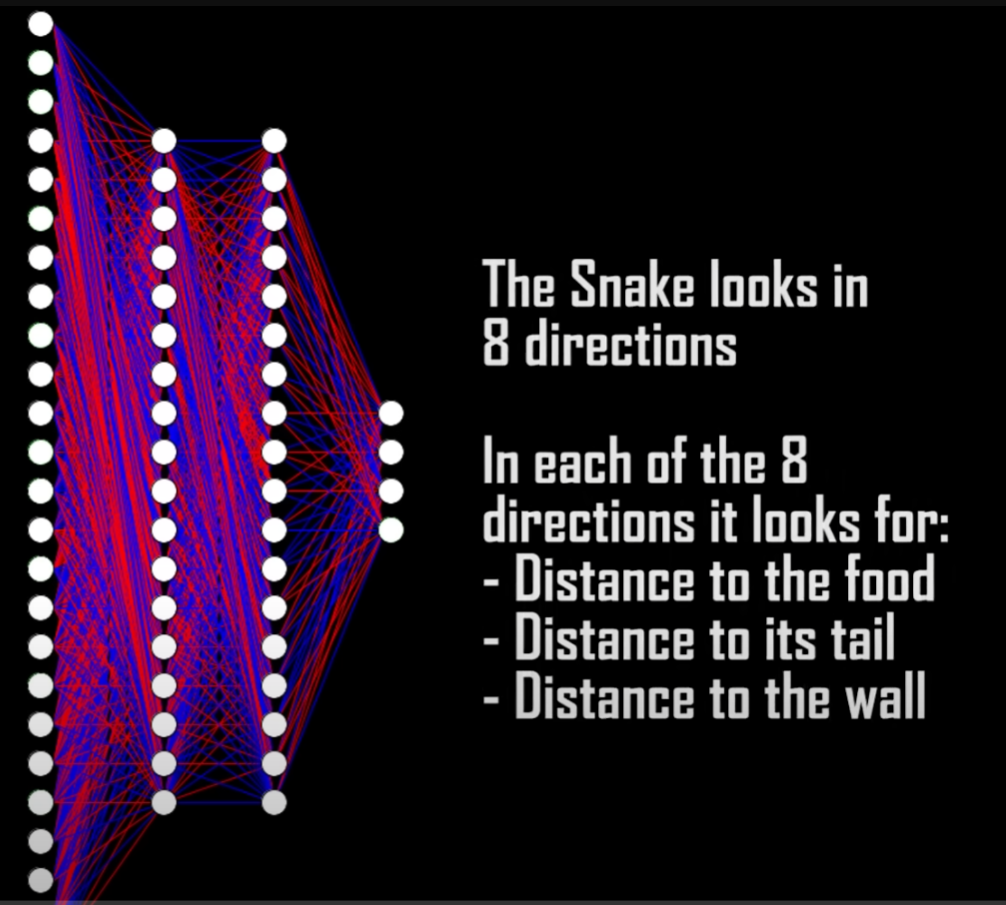
The snake can see in 8 directions. In each of these directions the snake looks for 3 things:
- Distance to food
- Distance to its own body
- Distance to a wall
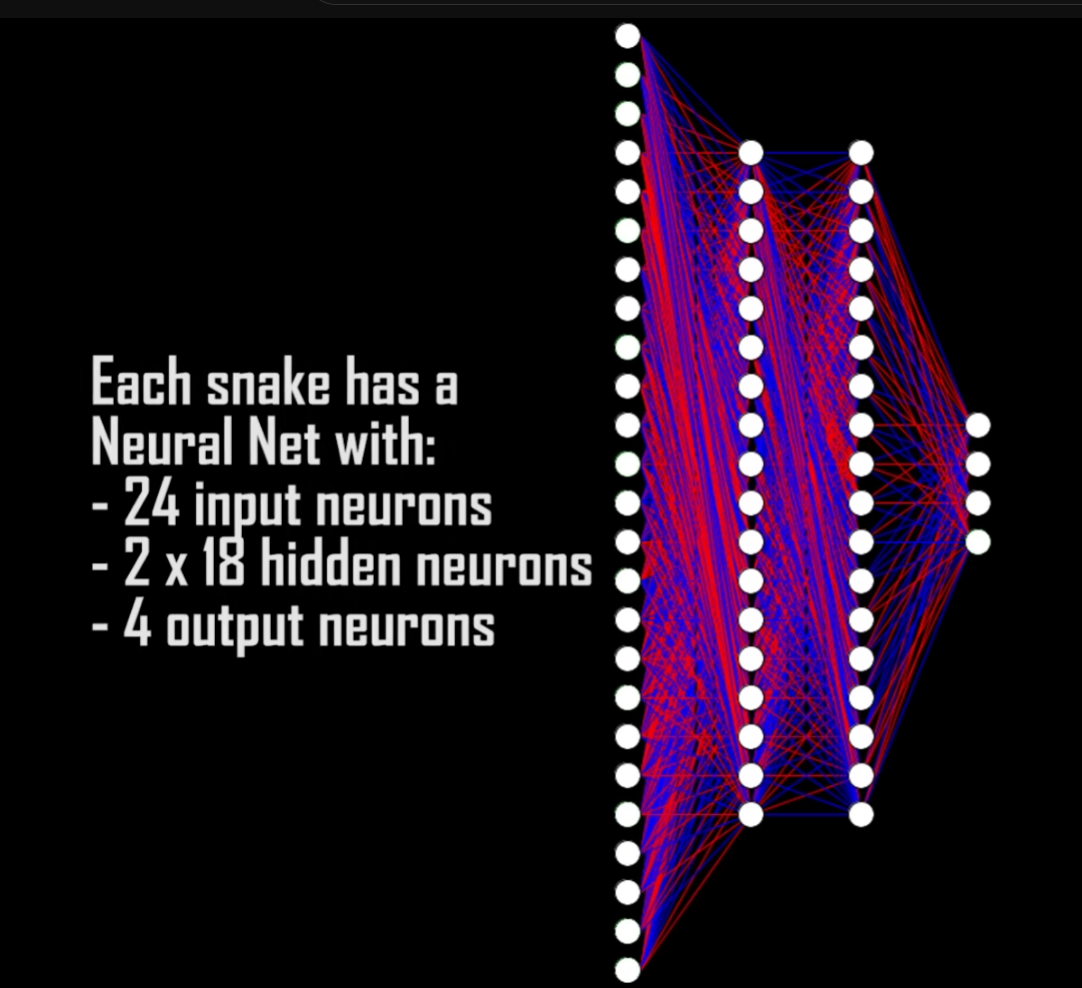
3 x 8 directions = 24 inputs. The 4 outputs are simply the directions the snake can move.

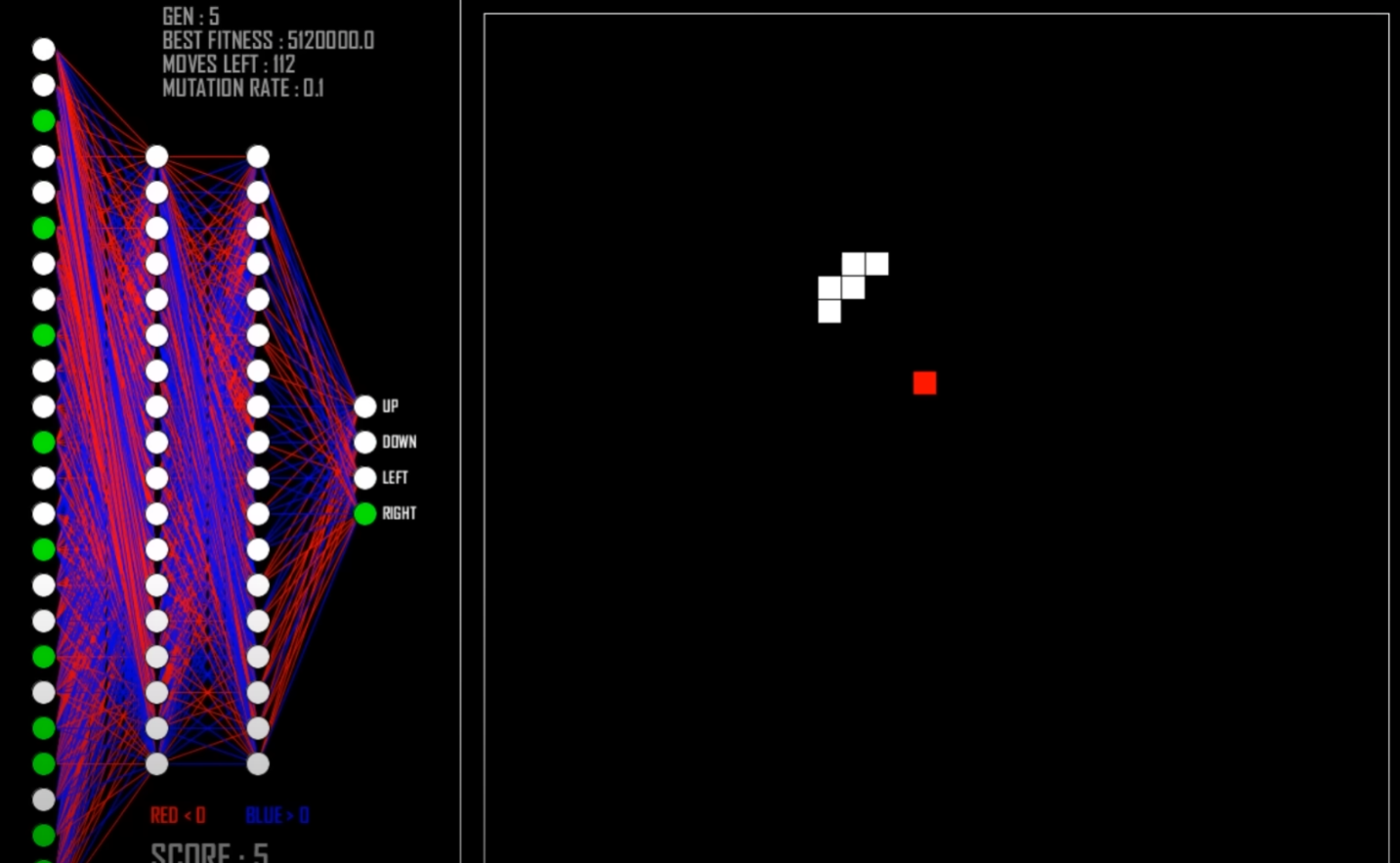
上面给出的是使用机器学习算法解决贪吃蛇问题,其实使用ML/RL方法解决贪吃蛇问题并不是最高效率的方法,由于贪吃蛇问题是可以使用数学方式求解析解的,或者使用数据结构建立好用算法策略来求解,总之,使用启发式算法或者数学解析解的方法可以更高效率求解贪吃蛇问题,不过由于本文主要是研究Reinforcement Learning问题,因此其他方法求解该问题不具体展开,下面给出其他方法的相关资料。
其他方法解决贪吃蛇问题:
How to Win Snake: The UNKILLABLE Snake AI
https://github.com/BrianHaidet/AlphaPhoenix/tree/master/Snake_AI_(2020a)_DHCR_with_strategy
强化学习算法library库:(集成库)
https://github.com/Denys88/rl_games
https://github.com/Domattee/gymTouch
个人github博客地址:
https://devilmaycry812839668.github.io/
如何使用强化学习算法解决贪吃蛇问题(Neural Network Learns to Play Snake)的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 深度学习:卷积神经网络(convolution neural network)
(一)卷积神经网络 卷积神经网络最早是由Lecun在1998年提出的. 卷积神经网络通畅使用的三个基本概念为: 1.局部视觉域: 2.权值共享: 3.池化操作. 在卷积神经网络中,局部接受域表明输入图 ...
- 强化学习算法Policy Gradient
1 算法的优缺点 1.1 优点 在DQN算法中,神经网络输出的是动作的q值,这对于一个agent拥有少数的离散的动作还是可以的.但是如果某个agent的动作是连续的,这无疑对DQN算法是一个巨大的挑战 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 贪吃蛇的java代码分析(一)
自我审视 最近自己学习java已经有了一个多月的时间,从一开始对变量常量的概念一无所知,到现在能勉强写几个小程序玩玩,已经有了长足的进步.今天没有去学习,学校里要进行毕业答辩和拍毕业照了,于是请了几天 ...
- 强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用.这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学 ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
随机推荐
- StarNet:关于 Element-wise Multiplication 的高性能解释研究 | CVPR 2024
论文揭示了star operation(元素乘法)在无需加宽网络下,将输入映射到高维非线性特征空间的能力.基于此提出了StarNet,在紧凑的网络结构和较低的能耗下展示了令人印象深刻的性能和低延迟 来 ...
- 19-canvas绘制文字
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- 瑞芯微rk356x板子快速上手
@ 目录 rk3568 CPU GPU NPU VPU 一.编译环境要求 二.编译前准备 0)开发板型号 1)安装第三方编译工具 2)设置adb路径 3)安装USB驱动DriverAssitant_v ...
- esphome-esp8266
esp8266使用esphome接入hass 对于生成配置文件的更改 此处nodemcu泛指集成的开发板,一般十几块钱一块 下方使用的是D1,对应的针脚是GPIO5 esp8266: board: n ...
- Docker 抓取 buildx 缓存
有时候由于配置的失误,导致构建了好久的镜像没能推送到云或者保存到本地.而如果重新构建,则可能又要全部重来.其实这时候我们可以导出 buildx 中的缓存到本地文件,再将本地文件导入为镜像.这样可以节省 ...
- 【YashanDB知识库】自关联外键插入数据时报错:YAS-02033 foreign key constraint violated parent key not found
问题现象 使用如下的sql语句创建自关联外键表: drop table self_f_key; create table self_f_key(t1 number primary key not nu ...
- 通过 maven 命令来查看 jar 包的引用关系
通过 maven 命令来查看 jar 包的引用关系 1.可以通过maven命令来查看jar包的引用关系 mvn dependency:tree -Dverbose -Dincludes=org.cod ...
- 如何在 Web 前端做 3D 音效处理
一.背景 在社交元宇宙.大逃杀等类型的游戏场景下,用户在通过简单语音交流外,结合场景也需要一些立体声效果来让用户感知游戏角色周围其他用户的存在及其对应的距离和方位,提高语音互动的趣味性. 为了满足 ...
- TypeScript 5.1 & 5.2
getter 和 setter 可以完全不同类型了 以前我们提过,getter 的类型至少要是其中一个 setter 的类型.这个限制被突破了.现在可以完全使用不同类型了. v5.1 后,没有再报错了 ...
- TypeScript 高级教程 – 把 TypeScript 当编程语言使用 (第二篇)
前言 上一篇, 我们提到, TypeScript 进阶有 3 个阶段. 第一阶段是 "把 TypeScript 当强类型语言使用", 我们已经介绍完了. 第二阶段是 "把 ...