runoob-pandas(python)
https://www.runoob.com/pandas/pandas-tutorial.html
Pandas 教程

Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 应用
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
数据结构
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
Pandas 安装
安装 pandas 需要基础环境是 Python,开始前我们假定你已经安装了 Python 和 Pip。
使用 pip 安装 pandas:
pip install pandas
安装成功后,我们就可以导入 pandas 包使用:
import pandas
实例 - 查看 pandas 版本
>>> pandas.__version__ # 查看版本
'1.1.5'
导入 pandas 一般使用别名 pd 来代替:
import pandas as pd
实例 - 查看 pandas 版本
>>> pd.__version__ # 查看版本
'1.1.5'
Pandas 数据结构 - Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
创建一个简单的 Series 实例:
实例
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
输出结果如下:
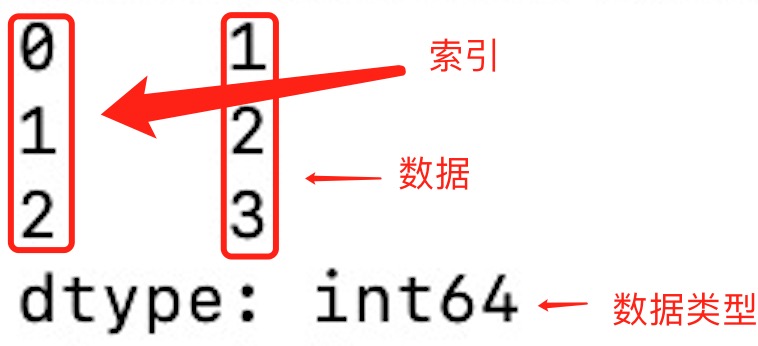
从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
实例
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar[1])
输出结果如下:
2
我们可以指定索引值,如下实例:
实例
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
输出结果如下:

根据索引值读取数据:
Pandas 数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
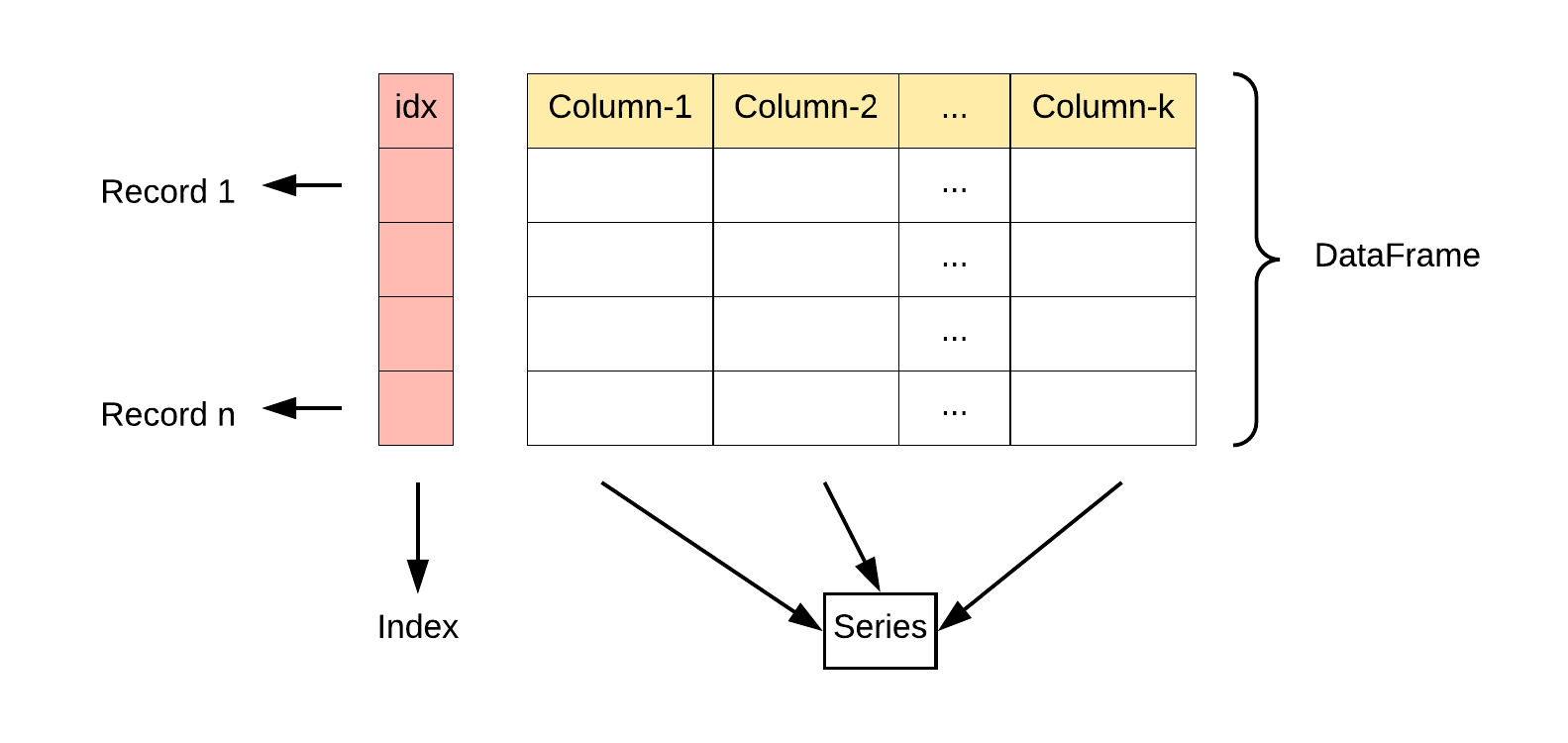
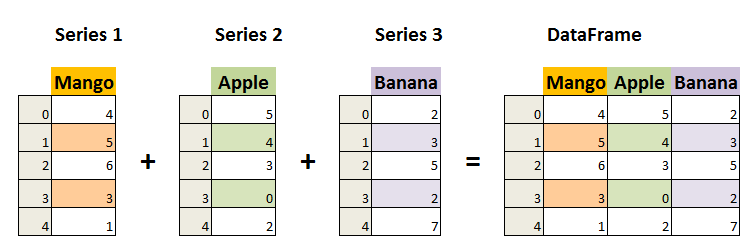
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
实例 - 使用列表创建
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
输出结果如下:
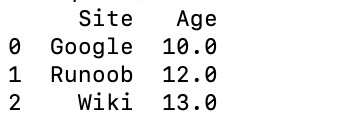
以下实例使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
ndarrays 可以参考:NumPy Ndarray 对象
实例 - 使用 ndarrays 创建
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
输出结果如下:
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):
Pandas CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很方便的处理 CSV 文件,本文以 nba.csv 为例,你可以下载 nba.csv 或打开 nba.csv 查看。
实例
df = pd.read_csv('nba.csv')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
实例
df = pd.read_csv('nba.csv')
print(df)
输出结果为:
Name Team Number Position Age Height Weight College Salary
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0
.. ... ... ... ... ... ... ... ... ...
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG 24.0 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C 26.0 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN NaN NaN NaN NaN NaN
我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
实例
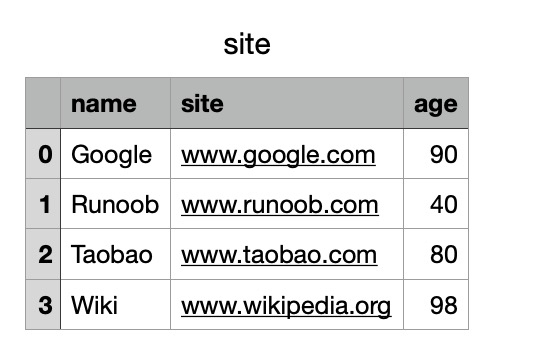
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
执行成功后,我们打开 site.csv 文件,显示结果如下:
数据处理
Pandas JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
Pandas 可以很方便的处理 JSON 数据,本文以 sites.json 为例,内容如下:
实例
实例
df = pd.read_json('sites.json')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
实例
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)
以上实例输出结果为:
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。
在这个教程中,我们将利用 Pandas包来进行数据清洗。
上表包含来四种空数据:
- n/a
- NA
- —
- na
Pandas 清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
我们可以通过 isnull() 判断各个单元格是否为空。
实例
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
runoob-pandas(python)的更多相关文章
- 基于pandas python的美团某商家的评论销售数据分析(可视化)
基于pandas python的美团某商家的评论销售数据分析 第一篇 数据初步的统计 本文是该可视化系列的第二篇 第三篇 数据中的评论数据用于自然语言处理 导入相关库 from pyecharts i ...
- https://www.runoob.com/python/python-variable-types.html
https://www.runoob.com/python/python-variable-types.html
- Pandas python
原文: https://github.com/catalystfrank/Python4DataScience.CH 和大熊猫们(Pandas)一起游戏吧! Pandas是Python的一个 ...
- 基于pandas python sklearn 的美团某商家的评论分类(文本分类)
美团店铺评价语言处理以及分类(NLP) 第一篇 数据分析部分 第二篇 可视化部分, 本文是该系列第三篇,文本分类 主要用到的包有jieba,sklearn,pandas,本篇博文主要先用的是词袋模型( ...
- 基于pandas python的美团某商家的评论销售(数据分析)
数据初步的分析 本文是该系列的第一篇 数据清洗 数据初步的统计 第二篇 数据可视化 第三篇 数据中的评论数据用于自然语言处理 from pyecharts import Bar,Pie import ...
- 推荐:python科学计算pandas/python画图库matplotlib【转】
机器学习基础3--python科学计算pandas(上) 地址:https://wangyeming.github.io/2018/09/04/marchine-learning-base-panda ...
- Pandas Python For Data Science
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- 【python操作Excel的常见方法汇总】 xlrd pandas xlwings
用python处理Excel数据,实现Excel的功能:分列.透视等功能 1. Excel 解压文件 #解压tar_path中的压缩文件到uzipPath def unzip_archive(tar_ ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
随机推荐
- 鸿蒙Banner图一多适配不同屏幕
认识一多 随着终端设备形态日益多样化,分布式技术逐渐打破单一硬件边界,一个应用或服务,可以在不同的硬件设备之间随意调用.互助共享,让用户享受无缝的全场景体验.而作为应用开发者,广泛的设备类型也能为应用 ...
- 一文彻底弄懂JUC工具包的CountDownLatch的设计理念与底层原理
CountDownLatch 是 Java 并发包(java.util.concurrent)中的一个同步辅助类,它允许一个或多个线程等待一组操作完成. 一.设计理念 CountDownLatch 是 ...
- SAM4MLLM:结合多模态大型语言模型和SAM实现高精度引用表达分割 | ECCV'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处 论文: SAM4MLLM: Enhance Multi-Modal Large Language Model for Referring Expres ...
- 【一步步开发AI运动小程序】十七、如何识别用户上传视频中的人体、运动、动作、姿态?
[云智AI运动识别小程序插件],可以为您的小程序,赋于人体检测识别.运动检测识别.姿态识别检测AI能力.本地原生识别引擎,内置10余个运动,无需依赖任何后台或第三方服务,有着识别速度快.体验佳.扩展性 ...
- golang WEB框架Hertz --- 获取参数
安装Hertz命令行工具 请确保您的Go版本在1.15及以上版本,笔者用的版本是1.18 配置好GO的环境后,按照Hertz的命名行工具 go install github.com/cloudwego ...
- python模块之sqlite3
在Python中操作sqlite3 1)基本使用 import sqlite3 conn = sqlite3.connect('example.db') cursor = conn.cursor() ...
- 结合uWSGI和Nginx部署flask项目
在开发环境,我们一般使用python起一个web服务即可访问,但是对于生产环境来说,我们一般使用nginx+uWSGI的方式进行部署. 使用Nginx优点: 安全:不管什么请求都要经过代理服务器,这样 ...
- 鸿蒙NEXT元服务:利用App Linking实现无缝跳转与二维码拉起
[效果] 元服务链接格式(API>=12适用):https://hoas.drcn.agconnect.link/ggMRM 生成二维码后效果: [参考网址] 使用App Linking实现 ...
- 生成式AI如何辅助医药行业智能营销
生成式AI如何辅助医药行业智能营销 生成式AI在医药行业的智能营销中发挥着日益重要的作用,它通过多种方式辅助医药企业提升市场洞察能力.优化营销策略.增强客户互动和体验,从而推动销售增长和品牌价值的提升 ...
- Mac m1 安装 Homebrew
Homebrew 是 Mac 的包管理器,类似于 Linux 中的 apt,Windows 中的 choco. 自从 M1 芯片发布,Homebrew 正在积极适配新架构,如今已经有了原生支持 ARM ...