CDH+Kylin三部曲之二:部署和设置
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
本文是《CDH+Kylin三部曲》系列的第二篇,上一篇《CDH+Kylin三部曲之一:准备工作》已将所需的机器和文件准备完毕,可以部署CDH和Kylin了;
执行ansible脚本部署CDH和Kylin(ansible电脑)
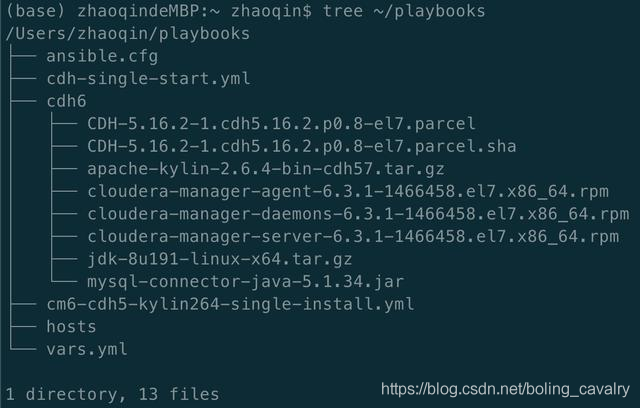
- 进入ansible电脑的~/playbooks目录,经过上一篇的准备工作,该目录下应该是下图这些内容:
- 检查ansible远程操作CDH服务器是否正常,执行命令ansible deskmini -a "free -m",正常情况下显示CDH服务器的内存信息,如下图:

- 执行命令开始部署:ansible-playbook cm6-cdh5-kylin264-single-install.yml
- 整个部署过程涉及在线安装、传输大文件等耗时的操作,请耐心等待(半小时左右),如果部署期间出错退出(例如网络问题),只需重复执行上述命令即可,ansible保证了操作的幂等性;
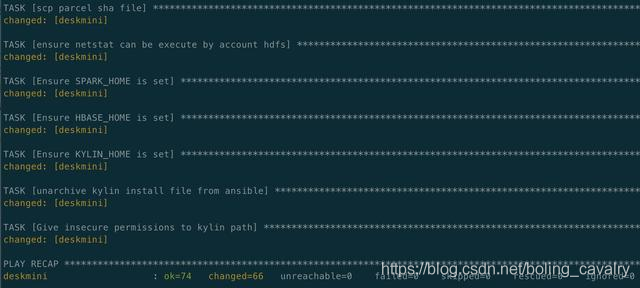
- 部署成功如下图所示:
重启CDH服务器
由于修改了selinux和swap的设置,需要重启操作系统才能生效,因此请重启CDH服务器;
执行ansible脚本启动CDH服务(ansible电脑)
- 等待CDH服务器重启成功;
- 登录ansible电脑,进入~/playbooks目录;
- 执行初始化数据库和启动CDH的脚本:ansible-playbook cdh-single-start.yml
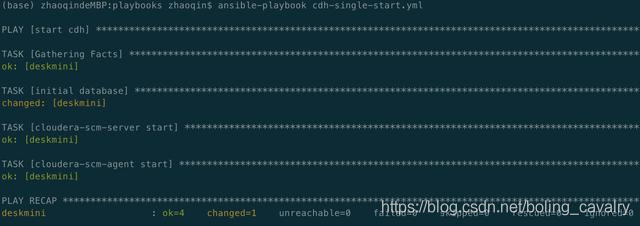
- 启动完成输出如下信息:
- ssh登录CDH服务器,执行此命令观察CDH服务的启动情况:tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log,看到下图红框中的内容时,表示启动完成,可以用浏览器登录了:

设置(浏览器操作)
现在CDH服务已经启动了,可以通过浏览器来操作:
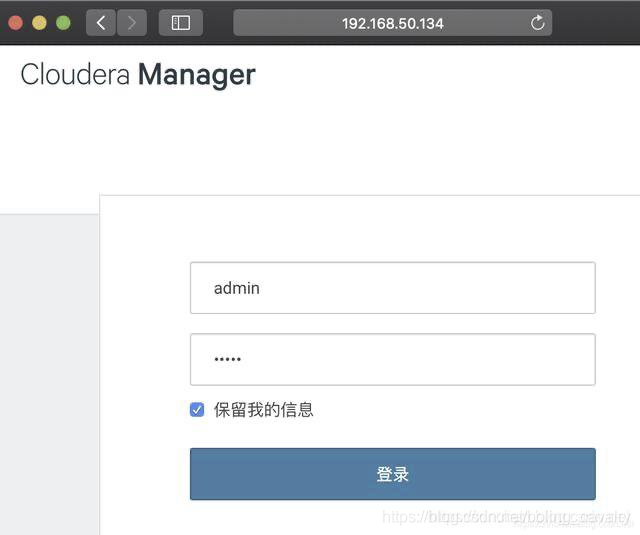
- 浏览器访问:http://192.168.50.134:7180 ,如下图,账号密码都是admin:
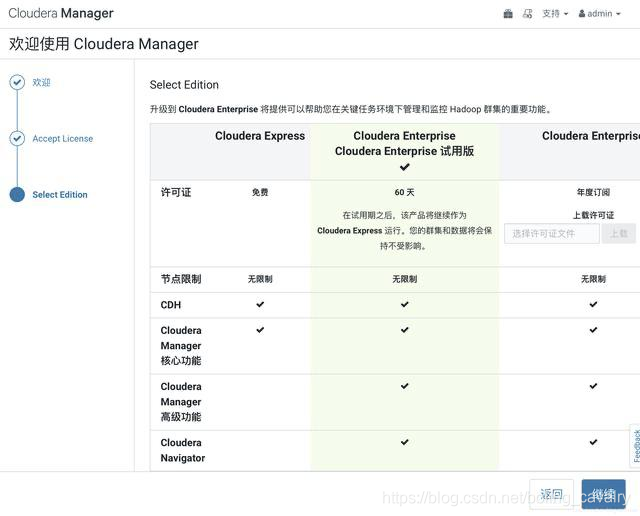
- 一路next,在选择版本页面选择60天体验版:
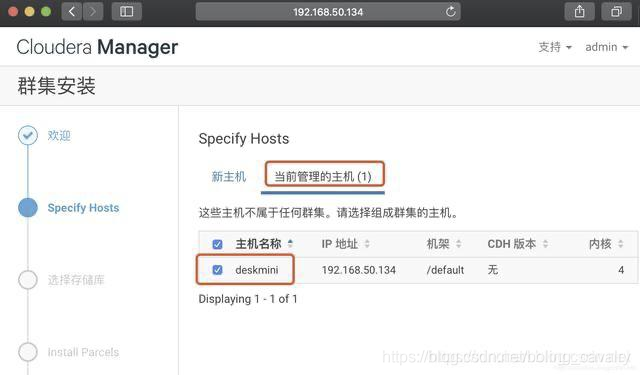
- 选择主机页面可见CDH服务器(deskmini):
- 在选择CDH版本的页面,请选择下图红框中的5.16.2-1:

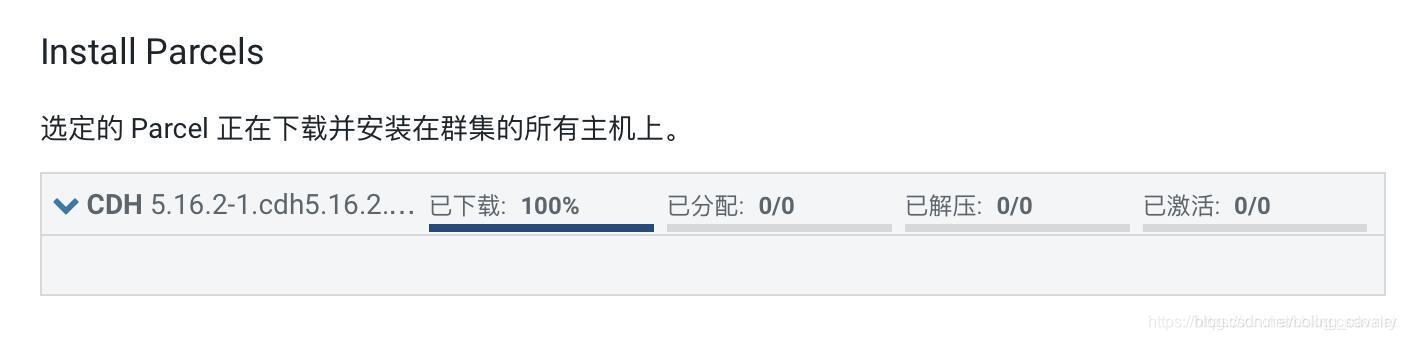
- 进入安装Parcel的页面,由于提前上传了离线parcle包,因此下载进度瞬间变成百分之百,此时请等待分配、解压、激活的完成:
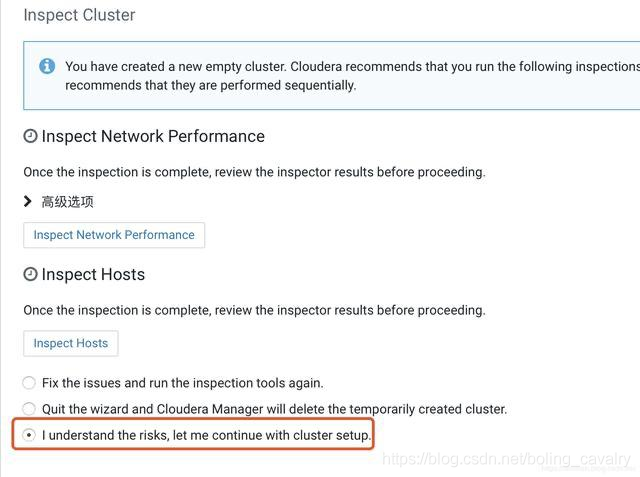
- 接下来有一些推荐操作,这里选择如下图红框,即可跳过:
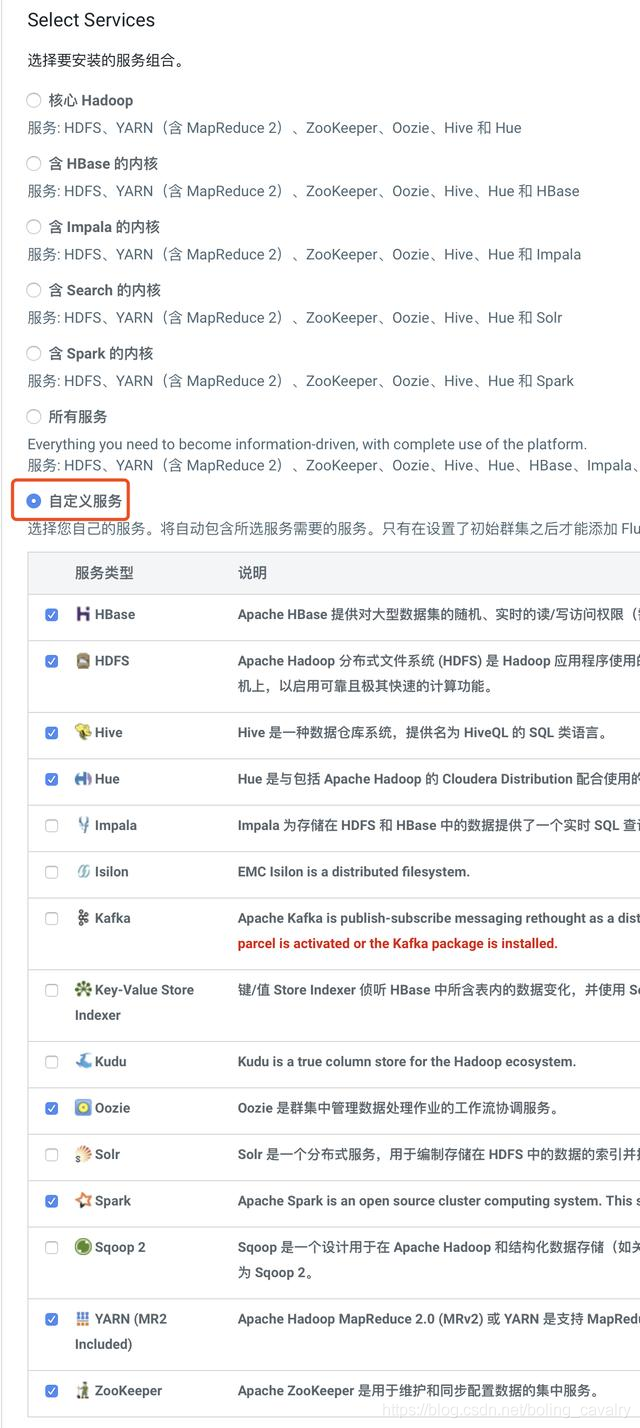
- 接下来是选择服务的页面,我选择了自定义服务,然后选择了HBase、HDFS、Hive、Hue、Oozie、Spark、YARN、Zookeeper这八项,可以满足运行Kylin的需要:
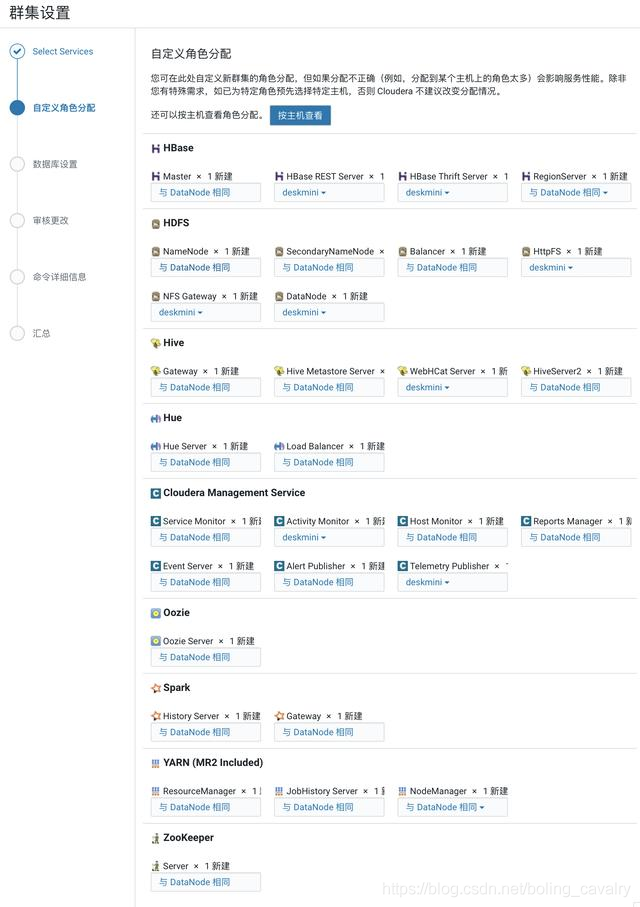
- 在选择主机的页面,都选择CDH服务器:
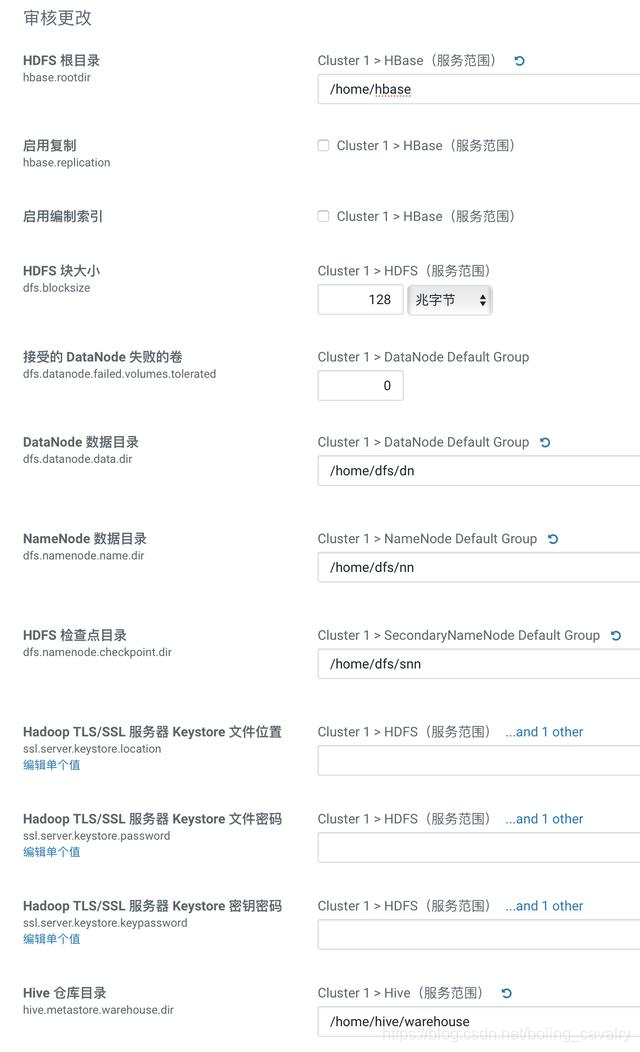
- 接下来是数据库设置的页面,您填写的内容必须与下图保持一致,即主机名为localhost,Hive的数据库、用户、密码都是hive,Activity Monitor的数据库、用户、密码都是amon,Reports Manager的数据库、用户、密码都是rman,Oozie Server的数据库、用户、密码都是oozie,Hue的数据库、用户、密码都是hue,这些内容在ansible脚本中已经固定了,此处的填写必须保持一致:

- 在设置参数的页面,请按照您的硬盘实际情况设置,我这里/home目录下空间充足,因此存储位置都改为/home目录下:
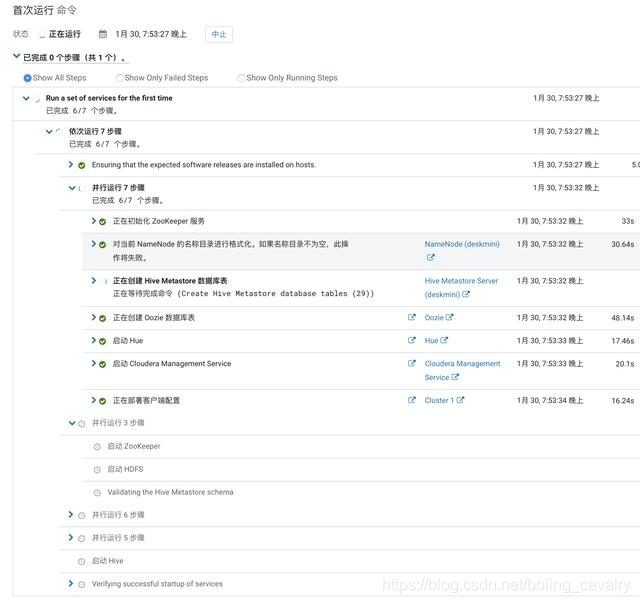
- 等待服务启动:
- 各服务启动完成:
HDFS设置
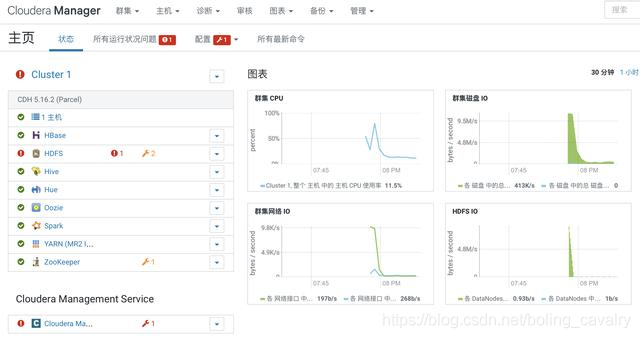
- 如下图红框所示,HDFS服务存在问题:
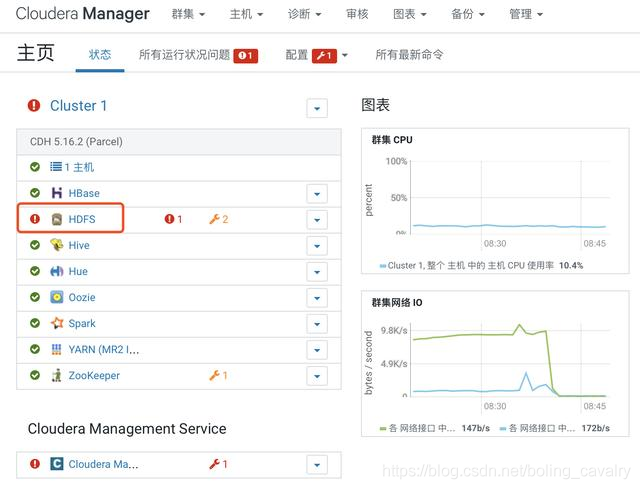
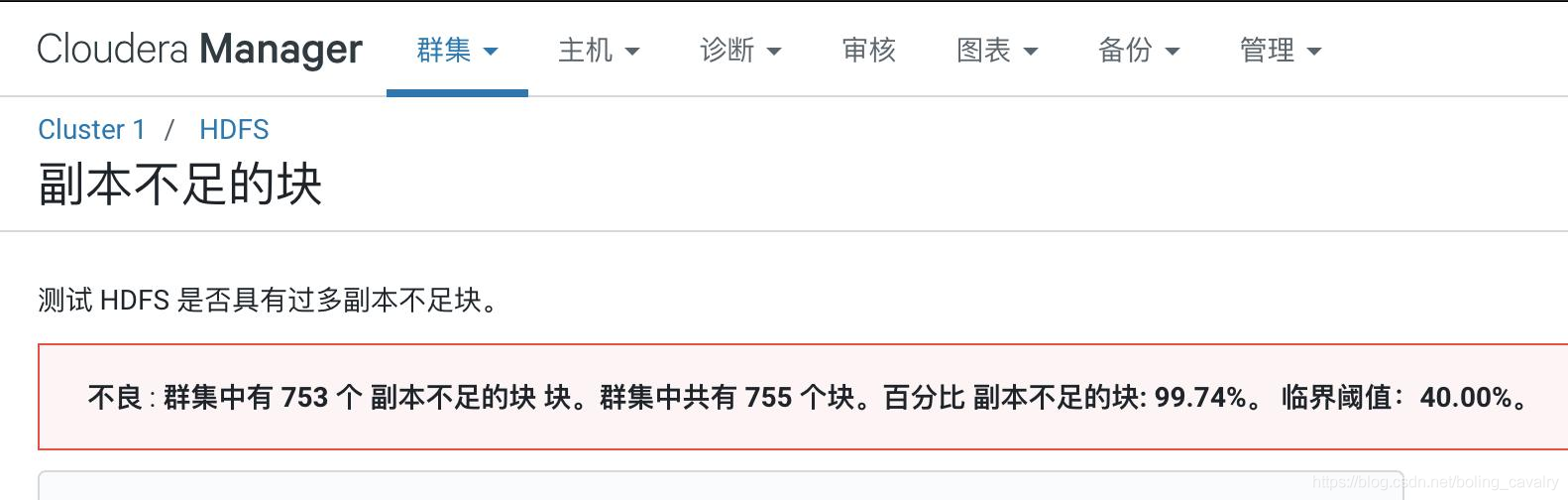
- 点击上图中红色感叹号可见问题详情,如下图,是常见的副本问题:
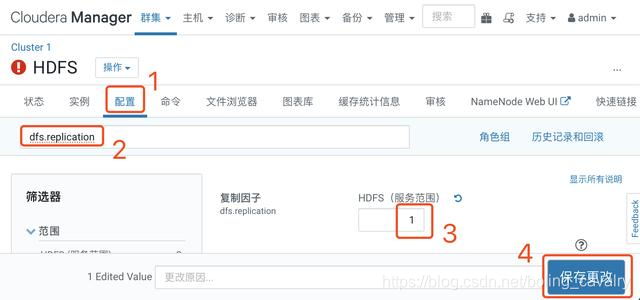
- 操作如下图,在HDFS的参数设置页面,将dfs.replication的值设置为1(只有一个数据节点):
- 经过上述设置,副本数已经调整为1,但是已有文件的副本数还没有同步,需要重新做设置,SSH登录到CDH服务器上;
- 执行命令su - hdfs切换到hdfs账号,再执行以下命令即可完成副本数设置:
hadoop fs -setrep -R 1 /
- 回到网页,重启HDFS服务,如下图:
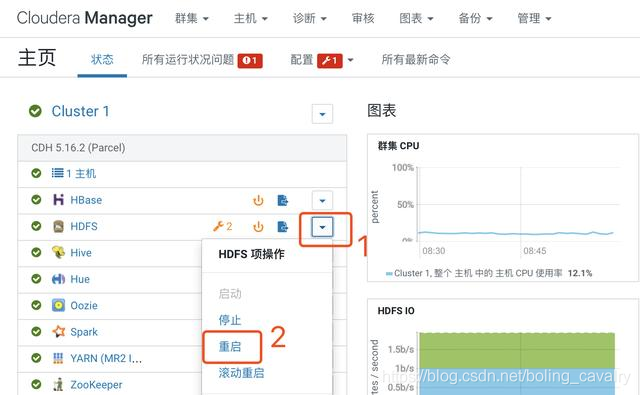
- 重启后HDFS服务正常:
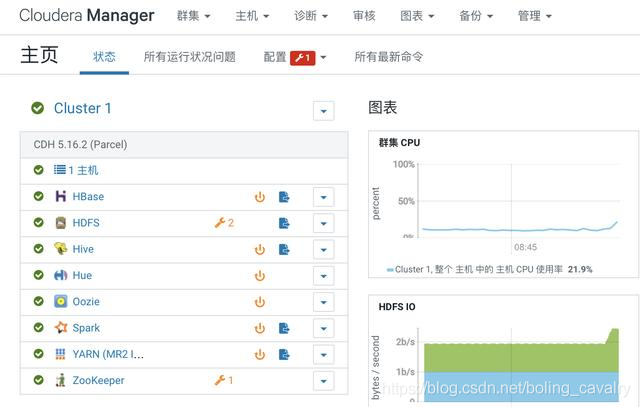
YARN设置
默认的YARN参数是非常保守的,需要做一些设置才能顺利执行Spark任务:
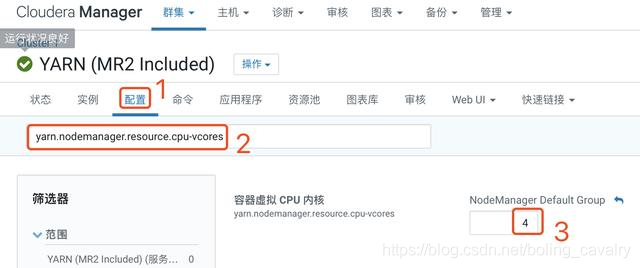
- 进入YARN管理页;
- 如下图所示,检查参数yarn.nodemanager.resource.cpu-vcores的值,该值必须大于1,否则提交Spark任务后YARN不分配资源执行任务,(如果您的CDH服务器是虚拟机,当CPU只有单核时,则此参数就会被设置为1,解决办法是先提升虚拟机CPU核数,再来修改此参数):
- yarn.scheduler.minimum-allocation-mb:单个容器可申请的最小内存,我这里设置为1G
- yarn.scheduler.maximum-allocation-mb:单个容器可申请的最大内存,我这里设置为8G
- yarn.nodemanager.resource.memory-mb:节点最大可用内存,我这里设置为8G
- 上述三个参数的值,是基于我的CDH服务器有32G内存的背景,请您按照自己硬件资源自行调整;
- 设置完毕后重启YARN服务,操作如下图所示:
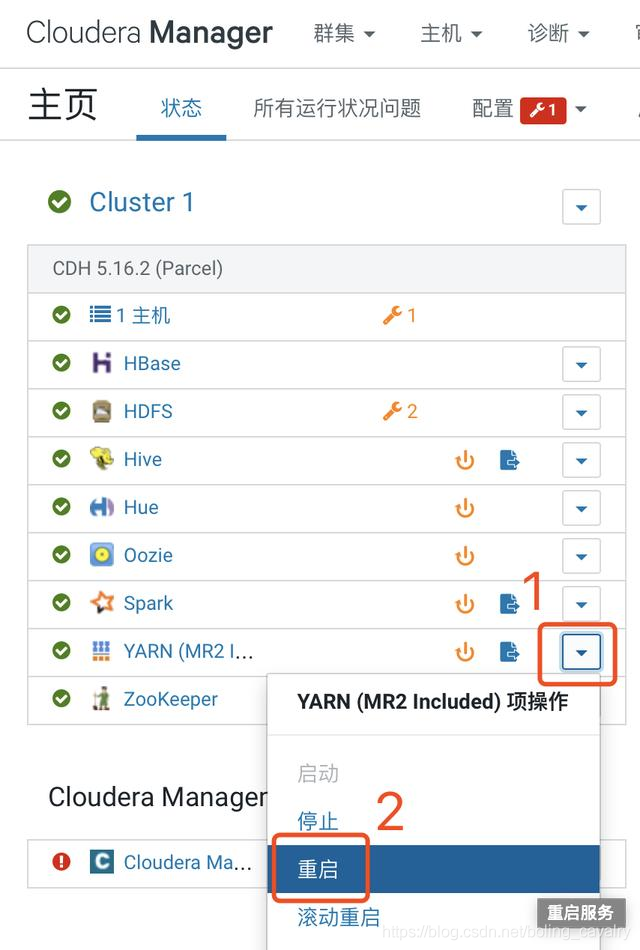
Spark设置(CDH服务器)
需要在Spark环境准备一个目录以及相关的jar,否则Kylin启动会报错(提示spark not found, set SPARK_HOME, or run bin/download-spark.sh),以root身份SSH登录CDH服务器,执行以下命令:
mkdir $SPARK_HOME/jars \
&& cp $SPARK_HOME/assembly/lib/*.jar $SPARK_HOME/jars/ \
&& chmod -R 777 $SPARK_HOME/jars
启动Kylin(CDH服务器)
- SSH登录CDH服务器,执行su - hdfs切换到hdfs账号;
- 按照官方推荐,先执行检查环境的命令:$KYLIN_HOME/bin/check-env.sh
- 检查通过的话控制台输出如下:

- 启动Kylin:$KYLIN_HOME/bin/kylin.sh start
- 控制台输出以下内容说明启动Kylin成功:
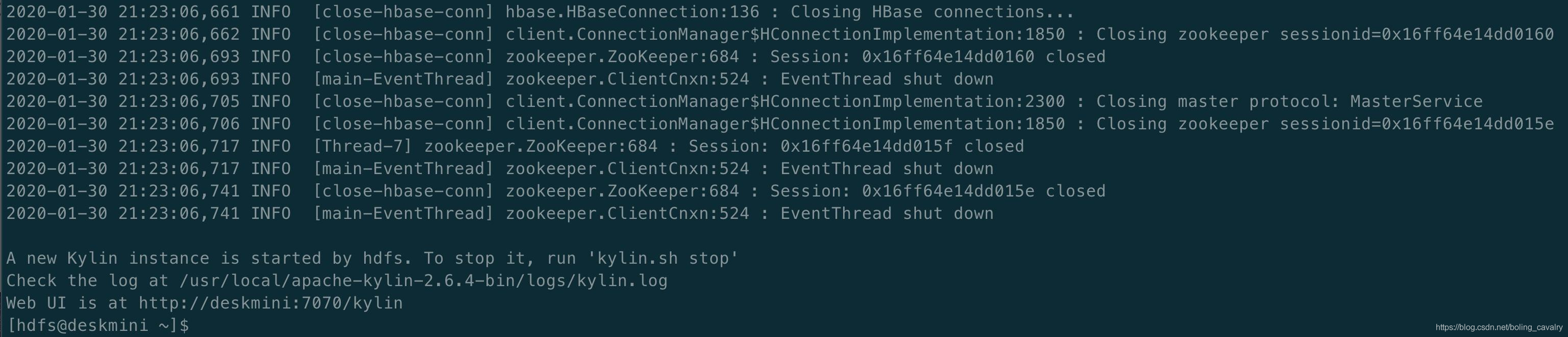
登录Kylin
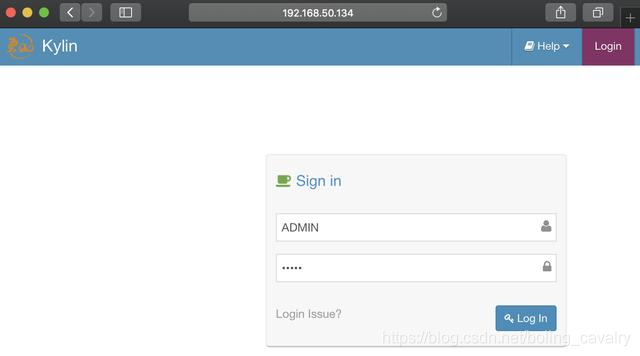
- 浏览器访问:http://192.168.50.134:7070/kylin,如下图,账号ADMIN,密码KYLIN(账号和密码都是大写):
- 登录成功,可以使用了:
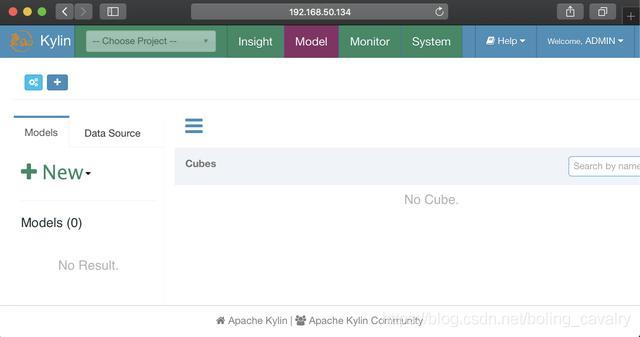
至此,CDH和Kylin的部署、设置、启动都已完成,Kylin已经可用了,在下一篇文章中,我们就在此环境运行Kylin的官方demo,体验Kylin;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
CDH+Kylin三部曲之二:部署和设置的更多相关文章
- CDH+Kylin三部曲之三:Kylin官方demo
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- CDH+Kylin三部曲之一:准备工作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- CDH5部署三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink on Yarn三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- kubernetes下的Nginx加Tomcat三部曲之二:细说开发
本文是<kubernetes下的Nginx加Tomcat三部曲>的第二章,在<kubernetes下的Nginx加Tomcat三部曲之一:极速体验>一文我们快速部署了Nginx ...
- 手把手教从零开始在GitHub上使用Hexo搭建博客教程(二)-Hexo参数设置
前言 前文手把手教从零开始在GitHub上使用Hexo搭建博客教程(一)-附GitHub注册及配置介绍了github注册.git相关设置以及hexo基本操作. 本文主要介绍一下hexo的常用参数设置. ...
- [原]CentOS7安装Rancher2.1并部署kubernetes (二)---部署kubernetes
################## Rancher v2.1.7 + Kubernetes 1.13.4 ################ ##################### ...
- Docker下实战zabbix三部曲之二:监控其他机器
在上一章<Docker下实战zabbix三部曲之一:极速体验>中,我们快速安装了zabbix server,并登录管理页面查看了zabbix server所在机器的监控信息,但是在实际场景 ...
- Flink的DataSource三部曲之二:内置connector
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- spring framework源码之SpringFactoriesLoader
SpringFactoriesLoader 查询META-INF/spring.factories的properties配置中指定class对应的所有实现类. public abstract clas ...
- FTL指令常用标签及语法
FTL指令常用标签及语法注意:使用freemaker,要求所有标签必须闭合,否则会导致freemaker无法解析. freemaker注释:<#-- 注释内容 -->格式部分,不会输出 - ...
- FreeSWITCH 处理Refer盲转时,UUI传递不对(没有将SIP 消息头Refer-To中的User-to-User传递给B-Leg)
运行环境: CentOS 7.6 FreeSWICH 1.6.18 一.问题场景: FreeSWITCH收到REFER命令后,重新发起的INVITE消息中的 "U ...
- MVC设计模式-笔记1
MVC不仅仅是一个设计模式,它应该说是一种软件开发架构模式,它包含了很多的设计模式,最为密切是以下三种模式: 1.Observer观察者模式 2.Composite组合模式 3.Strategy策略模 ...
- Centos7防火墙以及端口控制
开启防火墙 systemctl start firewalld.service --启动firewall systemctl enable firewalld.service --开机时启动firew ...
- 【Processing-日常4】等待动画2
之前在CSDN上发表过: https://blog.csdn.net/fddxsyf123/article/details/79781034
- nginx特性
nginx特点: 更快,高扩展性,高可靠性,低能耗性,单机支持10w以上的并发连接,热部署,自由的BSD, Apache.Lighttpd.Tomcat.Jetty.IIS,它们都是Web服务器 SN ...
- Salesforce Javascript(二) 箭头函数
本篇参考:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Functions/Arrow_functions 我们在 ...
- 使用 .NET 进行游戏开发
微软是一家综合性的网络公司,相信这点来说不用过多的赘述,没有人不知道微软这个公司,这些年因为游戏市场的回报,微软收购了很多的游戏公司还有独立工作室,MC我的世界就是最成功的的案例,现在市值是排在全世界 ...
- Codeforces Global Round 11 个人题解(B题)
Codeforces Global Round 11 1427A. Avoiding Zero 题目链接:click here 待补 1427B. Chess Cheater 题目链接:click h ...