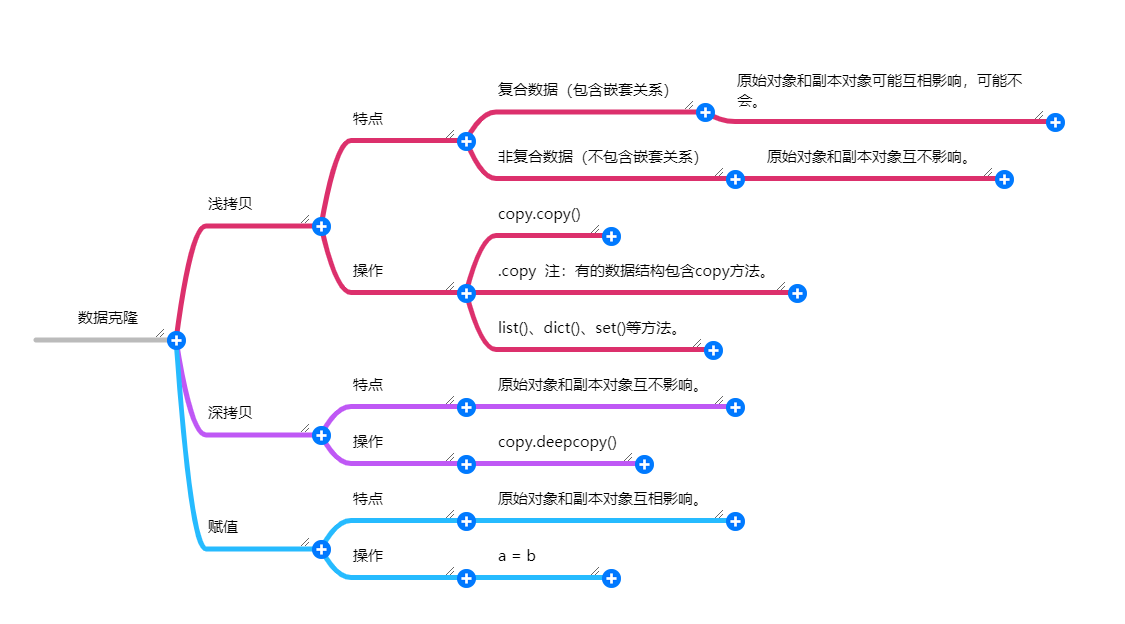
001 说说Python中的深拷贝和浅拷贝
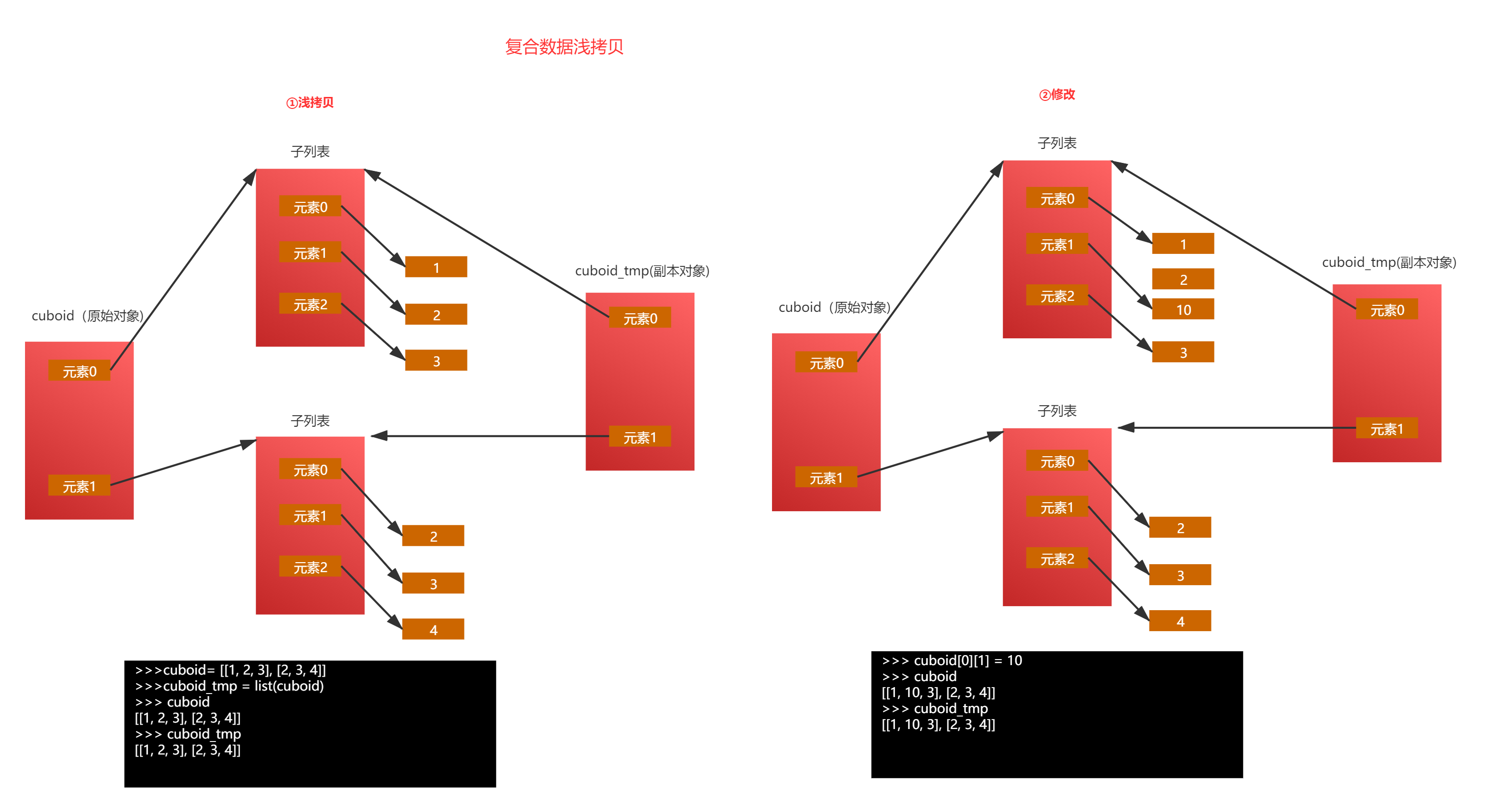
# :假设cuboid中保存了两个长方体的长、宽、高。
>>> cuboid= [[1, 2, 3], [2, 3, 4]]
# :有多种方式生成cuboid的副本,这里使用list()方法。
>>> cuboid_tmp = list(cuboid)
>>> cuboid_tmp
[[1, 2, 3], [2, 3, 4]]
# :修改原始对象数据。
>>> cuboid[0][1] = 10
>>> cuboid
[[1, 10, 3], [2, 3, 4]]
# :查看副本对象中数据并与原始对象数据对比。
>>> cuboid_tmp
[[1, 10, 3], [2, 3, 4]]
>>> id(cuboid)
2827786472008
>>> id(cuboid_tmp)
2827786472200 # 不一样
浅拷贝
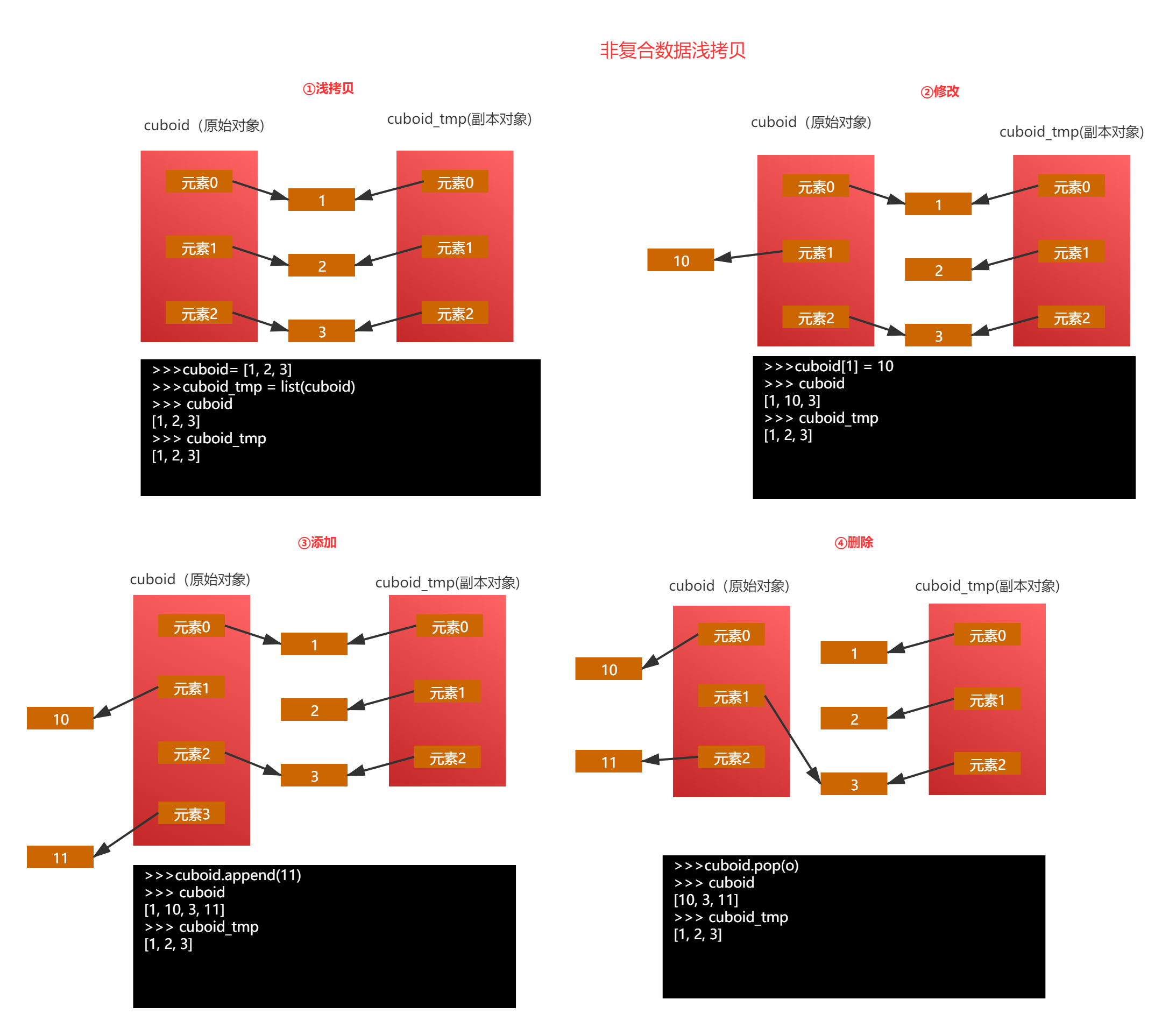
# :假设cuboid中保存了一个长方体的长、宽、高。
>>> cuboid= [1, 2, 3]
# :我们还是使用list()浅拷贝生成一个副本。
>>> cuboid_tmp = list(cuboid)
# :修改原始对象数据。
>>> cuboid[1] = 10
>>> cuboid
[1, 10, 3]
# :查看副本对象中数据并与原始对象数据对比。
>>> cuboid_tmp
[1, 2, 3]
>>> id(cuboid)
2827786471176
>>> id(cuboid_tmp)
2827786484936 # 不一样
>>> for i in cuboid:
... print(id(i))
140733841519440
140733841519728
140733841519504
>>>
>>> for i in cuboid_tmp:
... print(id(i))
140733841519440 # 一样
140733841519472 # 不一样
140733841519504 # 一样
>>> cuboid = [1,2,3]
>>> cuboid_tmp = cuboid
>>> id(cuboid)
1919680744520
>>> id(cuboid_tmp)
1919680744520 # 一样
>>> cuboid[1] = 10
>>> cuboid
[1, 10, 3]
>>> cuboid_tmp
[1, 10, 3]
001 说说Python中的深拷贝和浅拷贝的更多相关文章
- **Python中的深拷贝和浅拷贝详解
Python中的深拷贝和浅拷贝详解 这篇文章主要介绍了Python中的深拷贝和浅拷贝详解,本文讲解了变量-对象-引用.可变对象-不可变对象.拷贝等内容. 要说清楚Python中的深浅拷贝,需要 ...
- python中的深拷贝与浅拷贝
深拷贝和浅拷贝 浅拷贝的时候,修改原来的对象,浅拷贝的对象不会发生改变. 1.对象的赋值 对象的赋值实际上是对象之间的引用:当创建一个对象,然后将这个对象赋值给另外一个变量的时候,python并没有拷 ...
- python中的深拷贝和浅拷贝理解
在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用.以下分两个思路来分别理解浅拷贝和深拷贝: 利用切 ...
- python中的深拷贝和浅拷贝
python的复制,深拷贝和浅拷贝的区别 在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用 一 ...
- Python 中的深拷贝和浅拷贝
一.浅拷贝python中 对象赋值时 默认是浅拷贝,满足如下规律:1. 对于 不可变对象(字符串,元组 等),赋值 实际上是创建一个新的对象:例如: >>> person=['nam ...
- python中的深拷贝和浅拷贝(面试题二)
一.浅拷贝 定义:浅拷贝只是对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值. 浅拷贝的特点: 公用一个值: 这两个变量的内存地址一样: 对其中一个变量的值改变,另外一个变量的值也 ...
- python中的深拷贝和浅拷贝(面试题)
一.浅拷贝 定义:浅拷贝只是对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值. 浅拷贝的特点: 公用一个值: 这两个变量的内存地址一样: 对其中一个变量的值改变,另外一个变量的值也 ...
- 【转】Python中的赋值、浅拷贝、深拷贝介绍
这篇文章主要介绍了Python中的赋值.浅拷贝.深拷贝介绍,Python中也分为简单赋值.浅拷贝.深拷贝这几种"拷贝"方式,需要的朋友可以参考下 和很多语言一样,Python中 ...
- 浅谈Java中的深拷贝和浅拷贝(转载)
浅谈Java中的深拷贝和浅拷贝(转载) 原文链接: http://blog.csdn.net/tounaobun/article/details/8491392 假如说你想复制一个简单变量.很简单: ...
随机推荐
- 2020牛客暑期多校训练营(第五场)B - Graph (异或 最小生成树 分治 Trie)
B - Graph 题目链接 每次操作不会改变两点之间的路径异或和 以 1 号点为起点,算出任意一点到 1 号点的异或值 dis[i](把该值当做 i 号点权值), 那么任意两点的异或值为 \(dis ...
- 牛客挑战赛33 C 艾伦的立体机动装置(几何)
思路: 我们需要枚举展开多少条边 然后把上底面的点放到和下底面一个平面 然后算两点之间的距离 注意判断直线与线段是否有交点 #include <bits/stdc++.h> using n ...
- 2019牛客多校 Round4
Solved:3 Rank:331 B xor 题意:5e4个集合 每个集合最多32个数 5e4个询问 询问l到r个集合是不是都有一个子集的xor和等于x 题解:在牛客多校第一场学了线性基 然后这个题 ...
- 51Nod - 1632
B国拥有n个城市,其交通系统呈树状结构,即任意两个城市存在且仅存在一条交通线将其连接.A国是B国的敌国企图秘密发射导弹打击B国的交通线,现假设每条交通线都有50%的概率被炸毁,B国希望知道在被炸毁之后 ...
- python函数传参
之前一直没有注意过该问题,在leetcode144中写递归发现该问题,不知道递归函数传参是指针还是引用. 参考:http://c.biancheng.net/view/2258.html 如果是不可变 ...
- 关于rand()
虽然很早就知道rand是伪随机了,但是一般都懒得用srand. 直到模拟银行家算法时不用srand就造成数据实在有点假(-_-||) 所以要记得srand((int)time(0))啊
- Rails框架学习
Don't Repeat Yourself! Convention Over Configuration. REST. Rails框架总览. Rails框架基本使用. Rails框架数据交互. Rai ...
- SVG path d Attribute
Scalable Vector Graphics (SVG) 1.1 (Second Edition) W3C Recommendation 16 August 2011 http://www.w3. ...
- how to create react custom hooks with arguments
how to create react custom hooks with arguments React Hooks & Custom Hooks // reusable custom ho ...
- Raspberry Pi 电路图模拟器
Raspberry Pi 电路图模拟器 Circuit Diagram / Circuit Graph https://fritzing.org/learning/tutorials/building ...