数据可视化之分析篇(九)PowerBI数据分析实践第三弹 | 趋势分析法
https://zhuanlan.zhihu.com/p/133484654
以财务报表分析为例,介绍通用的分析方法论,整体架构如下图所示:
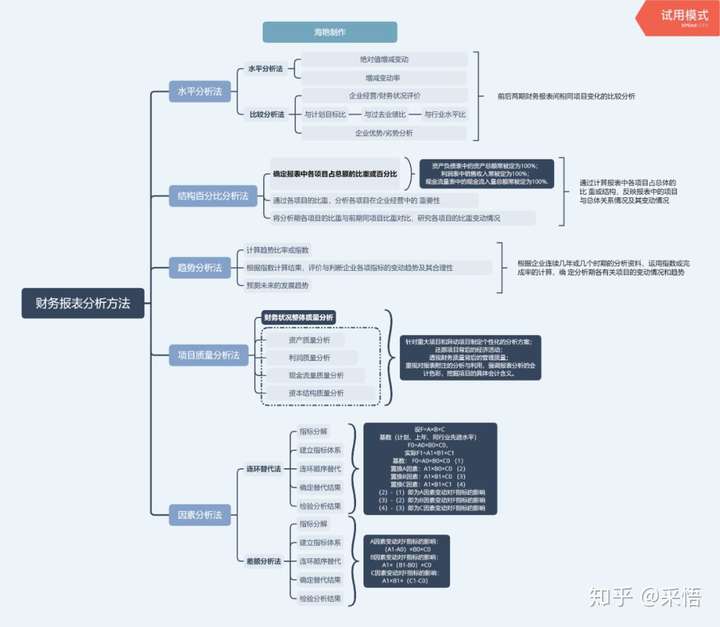
(点击查看大图)
我会围绕这五种不同的方法论,逐步阐述他们在 PowerBI 中的应用,之前已经介绍过前两个分析方法,本文谈一下第三种:趋势分析法的应用。
趋势分析法
趋势分析法是根据企业连续几年或几个时期的分析资料,运用指数或完成率的计算,确定分析期各有关项目的变动情况和趋势的一种财务分析方法。
趋势分析法的一般步骤是:
1.计算趋势比率或指数;
2.根据指数计算结果,评价和判断企业各项指标的变动趋势及其合理性;
3.预测未来的发展趋势。
涉及的常用dax函数:
SELECTCOLUMNS 返回具有从表中选择的列以及 DAX 表达式指定的新列的表GENERATESERIES 返回具有一列,并且从始至终使用连续值填充的表SELECTEDVALUE
在指定列中只有一个值时返回该值,否则返回替代结果
AVERAGEX
计算通过表格计算出的一组表达式的平均值(算术平均值)
DATESINPERIOD
返回给定期间中的日期
在开始之前,先来一个小插曲,不知道大家对前两次分享中的内容是否还有印象,有没有想在大金额的数值显示时把显示单位更换为万元或其它?那如果我们想以万元显示该怎样做呢?
(截止12月PowerBI 显示单位依然不支持万元)

具体做法附上:没有我们就自己创建一个。
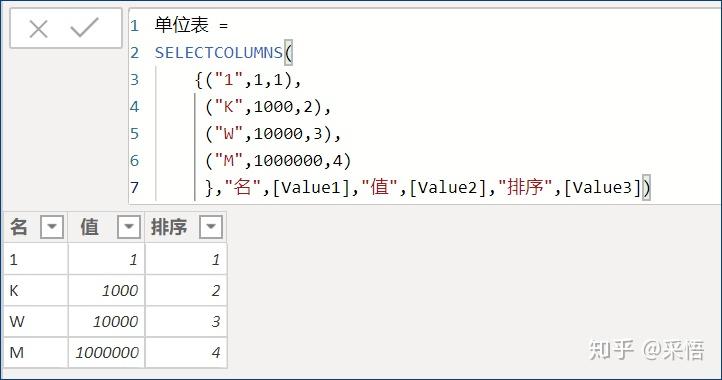
单位值= SELECTEDVALUE('单位表'[值],1)更改下对应度量值:
销售利润 = SUM('订单'[利润])/[单位值]让我们来看下不同单位的效果:

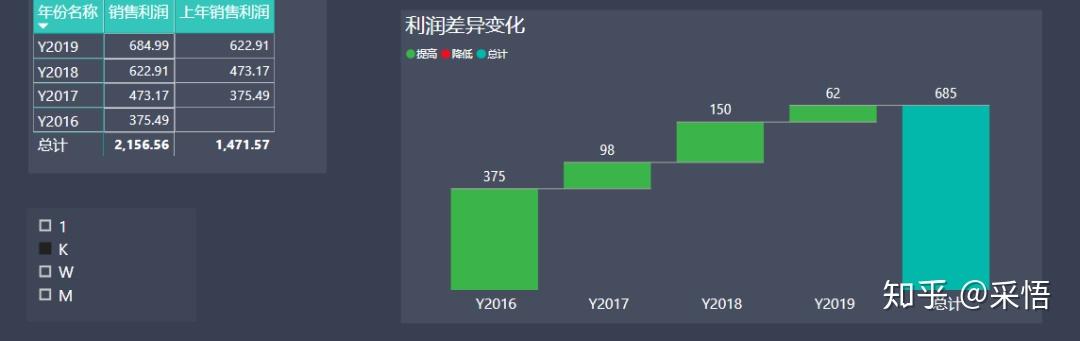

言归正传,让我们来进入正题:我们来使用销售收入进行实践 。
构建移动平均
在构建移动平均前,让我们先构建一个1-100的连续数据表作为动态筛选项。
筛选数据 = GENERATESERIES(1,100,1)注意:此处正确顺序建模-新表-输入上附DAX
筛选数据值 = SELECTEDVALUE('筛选数据'[筛选数据])
注意:此处正确顺序为建模-新建度量值-输入上附DAX
销售收入移动平均值 =AVERAGEX(DATESINPERIOD( '日期'[日期], MAX('日期'[日期]), -[筛选数据值],DAY),[销售收入])度量值写完,接下来让我们进行进行销售预测及销售趋势分析。
首先创建销售趋势图

其次加入趋势线

最后进入预测
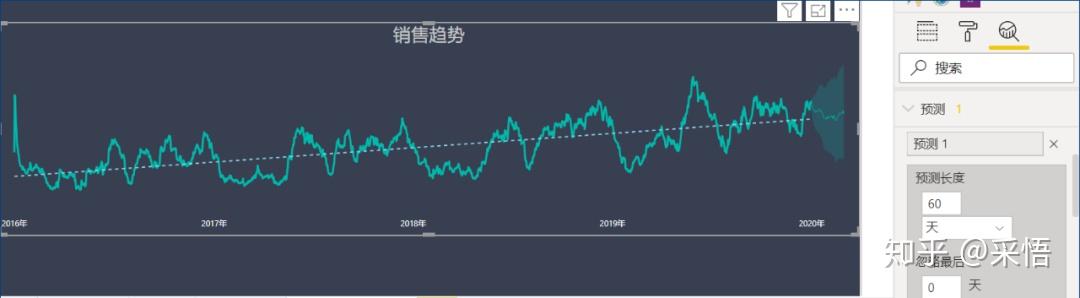
加入“销售收入”

最后呈现结果

分别看下各年情况
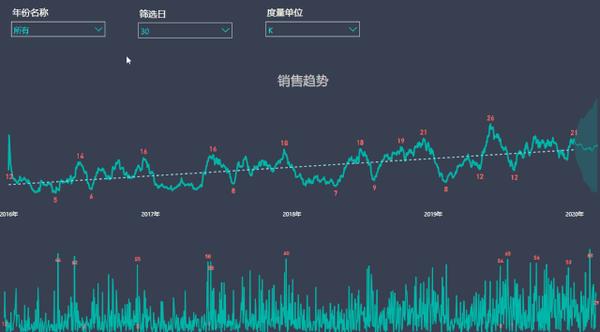
当然还可以这样

也还可以这样
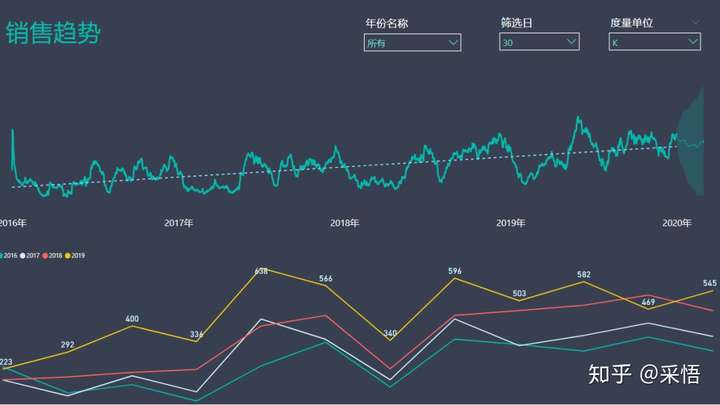
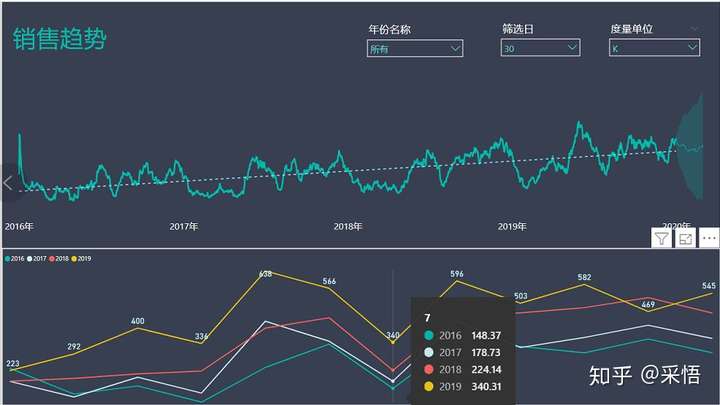
通过上面的内容,我们不难发现这一目标企业销售收入呈逐年递增趋势,每年第7月出现销售波动呈现销售下降趋势,8月又回调,那我们是否可以由此发现该企业的销售规律?以及由此去探究7月出现下降究竟是什么原因呢?
举个例子:每年我们剁手的日子6.18,双十一,双十二,这个时间段以销售电子产品为主业的零售企业是否会在当月或前月销售收入猛增呢?
通过上面的内容,不知你是否对其销售趋势有一个自己的预期,以及对这一目标企业销售情况有自己的预判,想一想这一企业未来销售情况将会是怎样呢?
注意:在实际中,影响销售的因素很多,在做销售趋势预测时需要综合考虑多种因素,请结合业务真实情况出发做销售趋势预测。
数据可视化之分析篇(九)PowerBI数据分析实践第三弹 | 趋势分析法的更多相关文章
- 数据可视化之PowerQuery篇(十九)PowerBI数据分析实践第三弹 | 趋势分析法
https://zhuanlan.zhihu.com/p/133484654 本文为星球嘉宾"海艳"的PowerBI数据分析工作实践系列分享之三,她深入浅出的介绍了PowerBI ...
- 数据可视化之分析篇(八)Power BI数据分析应用:结构百分比分析法
https://zhuanlan.zhihu.com/p/113113765 PowerBI数据分析02:结构百分比分析法 作者:海艳 结构百分比分析法,又称纵向分析,是指同一期间财务报表中不同项目间 ...
- 数据可视化之分析篇(二)Power BI 数据分析:客户购买频次分布
https://zhuanlan.zhihu.com/p/100070260 商业数据分析通常都可以简化为对数据进行筛选.分组.汇总的过程,本文通过一个实例来看看PowerBI是如何快速完成整个过程的 ...
- 数据可视化之分析篇(一)使用Power BI进行动态帕累托分析
https://zhuanlan.zhihu.com/p/57763423 通过简单的点击交互,就能进行动态分析发现见解,才是我们需要的,恰好这也是 PowerBI 所擅长的. 就帕累托分析来说,能从 ...
- 数据可视化之分析篇(七)Power BI数据分析应用:水平分析法
https://zhuanlan.zhihu.com/p/103264851 首先,以财务报表分析为例,介绍通用的分析方法论,整体架构如下图所示: (点击查看大图) 接下来我会围绕这五种不同的方法论, ...
- 数据可视化之分析篇(四)PowerBI分析模型:产品关联度分析
https://zhuanlan.zhihu.com/p/64510355 逛超市的时候,面对货架上琳琅满目的商品,你会觉得这些商品的摆放,或者不同品类的货架分布是随机排列的吗,当然不是. 应该都听说 ...
- 数据可视化之分析篇(六)使用Power BI进行流失客户分析
https://zhuanlan.zhihu.com/p/73358029 为了提升销量,在不断吸引新客户的同时,还要防止老客户离你而去,但每一个顾客不可能永远是你的客户,不可避免的都会经历新客户.活 ...
- 数据可视化之分析篇(五)如何使用Power BI计算新客户数量?
https://zhuanlan.zhihu.com/p/65119988 每个企业的经营活动都是围绕着客户而开展的,在服务好老客户的同时,不断开拓新客户是每个企业的经营目标之一. 开拓新客户必然要付 ...
- 数据可视化之分析篇(三)Power BI总计行错误,这个技巧一定要掌握
https://zhuanlan.zhihu.com/p/102567707 前一段介绍过一个客户购买频次统计的案例: Power BI 数据分析应用:客户购买频次分布. 我并没有在文章中显示总计行 ...
随机推荐
- (十)深入理解maven构建生命周期和各种plugin插件
链接:https://blog.csdn.net/zhaojianting/article/details/80321488
- os模块查看系统数据
>>> import os >>> os.name # 操作系统类型 'posix' 如果是posix,说明系统是Linux.Unix或Mac OS X,如果是nt ...
- wget介绍和命令总结
参考资料: https://www.cnblogs.com/ftl1012/p/9265699.html https://www.cnblogs.com/lsdb/p/7171779.html cur ...
- 【JMeter_17】JMeter逻辑控制器__随机顺序控制器<Random Order Controller>
随机顺序控制器<Random Order Controller> 业务逻辑: 当控制器被触发时,将控制器下的所有子节点顺序打乱执行一遍,执行一遍,执行一遍,不是执行一个. 注意:是将子节点 ...
- 简单梳理JavaScript垃圾回收机制
JavaScript具有自动垃圾回收机制,即执行环境会负责管理代码执行过程中使用地内存. 这种垃圾回收机制的原理很简单:找出那些不再继续使用的变量,然后释放其占用的内存.为此,垃圾收集器会按照固定的时 ...
- jmeter正则提取器提取一个值或多个值
[安装Dummy插件] 这个插件可以模拟服务器返回,相当于一个mockserver了. 首先安装Dummy,选项--插件管理--可选插件--Dummy. [模拟响应] 添加线程组,在线程组下添加Dum ...
- ASP.NET WebAPI框架解析第一篇
ASP.NET WebAPI有两种寄宿模式,一种是WebHost,一种是SelfHost,为什么可以有两种模式的原因在于WebAPI有一个相对独立的消息处理管道,只要给这个消息管道传递一个封装好的对象 ...
- 黎活明8天快速掌握android视频教程--20_采用ContentProvider对外共享数据
1.内容提供者是让当前的app的数据可以让其他应用访问,其他应该可以通过内容提供者访问当前app的数据库 contentProvider的主要目的是提供一个开发的接口,让其他的应该能够访问当前应用的数 ...
- 单元测试中使用mock最好不要使用easymock而应该使用powermock
视频参考汪文君powermock视频教程相当的经典
- disruptor架构二
小故事:Disruptor说的是生产者和消费者的故事. 有一个数组.生产者往里面扔芝麻.消费者从里面捡芝麻. 但是扔芝麻和捡芝麻也要考虑速度的问题. 1 消费者捡的比扔的快 那么消费者要停下来.生产者 ...