NameNode和SecondaryNameNode(面试开发重点)
NameNode和SecondaryNameNode(面试开发重点)
1 NN和2NN工作机制
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
NN和2NN工作机制,如图所示。
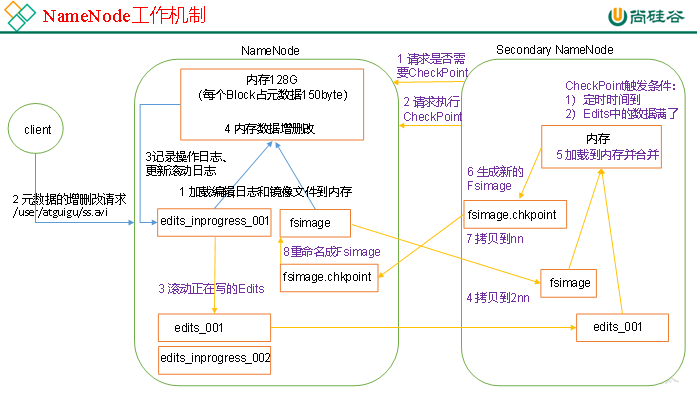
1. 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改。
2. 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
NN和2NN工作机制详解:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
-----------------------------------------------------------------------------------------------------------------------------------------------------
2 Fsimage和Edits解析

2. oiv查看Fsimage文件
(1)查看oiv和oev命令
[current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[current]$ pwd
/opt/module/hadoop-2.7./data/tmp/dfs/name/current
[current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7./fsimage.xml
[current]$ cat /opt/module/hadoop-2.7./fsimage.xml
将显示的xml文件内容拷贝到Eclipse中创建的xml文件中,并格式化。部分显示结果如下。
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>user</name>
<mtime>1512722284477</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16387</id>
<type>DIRECTORY</type>
<name>atguigu</name>
<mtime>1512790549080</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16389</id>
<type>FILE</type>
<name>wc.input</name>
<replication>3</replication>
<mtime>1512722322219</mtime>
<atime>1512722321610</atime>
<perferredBlockSize>134217728</perferredBlockSize>
<permission>atguigu:supergroup:rw-r--r--</permission>
<blocks>
<block>
<id></id>
<genstamp>1001</genstamp>
<numBytes>59</numBytes>
</block>
</blocks>
</inode >
思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么?
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
3. oev查看Edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
[current]$ hdfs oev -p XML -i edits_0000000000000000012- -o /opt/module/hadoop-2.7./edits.xml [current]$ cat /opt/module/hadoop-2.7./edits.xml
将显示的xml文件内容拷贝到Eclipse中创建的xml文件中,并格式化。显示结果如下。
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>129</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD</OPCODE>
<DATA>
<TXID>130</TXID>
<LENGTH>0</LENGTH>
<INODEID>16407</INODEID>
<PATH>/hello7.txt</PATH>
<REPLICATION>2</REPLICATION>
<MTIME>1512943607866</MTIME>
<ATIME>1512943607866</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-1544295051_1</CLIENT_NAME>
<CLIENT_MACHINE>192.168.1.5</CLIENT_MACHINE>
<OVERWRITE>true</OVERWRITE>
<PERMISSION_STATUS>
<USERNAME>atguigu</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
<RPC_CLIENTID>908eafd4-9aec-4288-96f1-e8011d181561</RPC_CLIENTID>
<RPC_CALLID>0</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<DATA>
<TXID>131</TXID>
<BLOCK_ID>1073741839</BLOCK_ID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<DATA>
<TXID>132</TXID>
<GENSTAMPV2>1016</GENSTAMPV2>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE>
<DATA>
<TXID>133</TXID>
<PATH>/hello7.txt</PATH>
<BLOCK>
<BLOCK_ID>1073741839</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1016</GENSTAMP>
</BLOCK>
<RPC_CLIENTID></RPC_CLIENTID>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_CLOSE</OPCODE>
<DATA>
<TXID>134</TXID>
<LENGTH>0</LENGTH>
<INODEID>0</INODEID>
<PATH>/hello7.txt</PATH>
<REPLICATION>2</REPLICATION>
<MTIME>1512943608761</MTIME>
<ATIME>1512943607866</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME></CLIENT_NAME>
<CLIENT_MACHINE></CLIENT_MACHINE>
<OVERWRITE>false</OVERWRITE>
<BLOCK>
<BLOCK_ID>1073741839</BLOCK_ID>
<NUM_BYTES>25</NUM_BYTES>
<GENSTAMP>1016</GENSTAMP>
</BLOCK>
<PERMISSION_STATUS>
<USERNAME>atguigu</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
</EDITS >
思考:NameNode如何确定下次开机启动的时候合并哪些Edits?
3 CheckPoint时间设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property> <property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
4 NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
1. kill -9 NameNode进程
2. 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
$ rm -rf /opt/module/hadoop-2.7./data/tmp/dfs/name/*
3. 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
[atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7./data/tmp/dfs/namesecondary/* ./name/
4. 重新启动NameNode
[atguigu@hadoop102 hadoop-2.7.]$ sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
1.修改hdfs-site.xml中的
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
2. kill -9 NameNode进程
3. 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
$ rm -rf /opt/module/hadoop-2.7./data/tmp/dfs/name/*
4. 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
[dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7./data/tmp/dfs/namesecondary ./ [namesecondary]$ rm -rf in_use.lock [ dfs]$ pwd
/opt/module/hadoop-2.7./data/tmp/dfs [dfs]$ ls
data name namesecondary
5. 导入检查点数据(等待一会ctrl+c结束掉)
$ bin/hdfs namenode -importCheckpoint
6. 启动NameNode
$ sbin/hadoop-daemon.sh start namenode
5 集群安全模式
1. 概述

2.基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
3. 案例
模拟等待安全模式
(1)查看当前模式
$ hdfs dfsadmin -safemode get
Safe mode is OFF
(2)先进入安全模式
[atguigu@hadoop102 hadoop-2.7.]$ bin/hdfs dfsadmin -safemode enter
(3)创建并执行下面的脚本
在/opt/module/hadoop-2.7.2路径上,编辑一个脚本safemode.sh
[atguigu@hadoop102 hadoop-2.7.]$ touch safemode.sh
[atguigu@hadoop102 hadoop-2.7.]$ vim safemode.sh #!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-2.7./README.txt / [atguigu@hadoop102 hadoop-2.7.]$ chmod safemode.sh [atguigu@hadoop102 hadoop-2.7.]$ ./safemode.sh
(4)再打开一个窗口,执行
[atguigu@hadoop102 hadoop-2.7.]$ bin/hdfs dfsadmin -safemode leave
(5)观察
(a)再观察上一个窗口
Safe mode is OFF
(b)HDFS集群上已经有上传的数据了。
6 NameNode多目录配置
1. NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
2. 具体配置如下
(1)在hdfs-site.xml文件中增加如下内容
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
(2)停止集群,删除data和logs中所有数据。
[atguigu@hadoop102 hadoop-2.7.]$ rm -rf data/ logs/
[atguigu@hadoop103 hadoop-2.7.]$ rm -rf data/ logs/
[atguigu@hadoop104 hadoop-2.7.]$ rm -rf data/ logs/
(3)格式化集群并启动。
[atguigu@hadoop102 hadoop-2.7.]$ bin/hdfs namenode –format
[atguigu@hadoop102 hadoop-2.7.]$ sbin/start-dfs.sh
(4)查看结果
[atguigu@hadoop102 dfs]$ ll
总用量
drwx------. atguigu atguigu 12月 : data
drwxrwxr-x. atguigu atguigu 12月 : name1
drwxrwxr-x. atguigu atguigu 12月 : name2
NameNode和SecondaryNameNode(面试开发重点)的更多相关文章
- DataNode(面试开发重点)
1 DataNode工作机制 DataNode工作机制,如图所示. 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和 ...
- HDFS的数据流读写数据 (面试开发重点)
1 HDFS写数据流程 1.1 剖析文件写入 HDFS写数据流程,如图所示 1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是 ...
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- hadoop及NameNode和SecondaryNameNode工作机制
hadoop及NameNode和SecondaryNameNode工作机制 1.hadoop组成 Common MapReduce Yarn HDFS (1)HDFS namenode:存放目录,最重 ...
- HDFS05 NameNode和SecondaryNameNode
NameNode和SecondaryNameNode(了解) 目录 NameNode和SecondaryNameNode(了解) NN 和 2NN 工作机制 NameNode工作机制 Secondar ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- Android开发重点难点1:RelativeLayout(相对布局)详解
前言 啦啦啦~博主又推出了一个新的系列啦~ 之前的Android开发系列主要以完成实验的过程为主,经常会综合许多知识来写,所以难免会有知识点的交杂,给人一种混乱的感觉. 所以博主推出“重点难点”系列, ...
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- NameNode 与 SecondaryNameNode 的工作机制
一.NameNode.Fsimage .Edits 和 SecondaryNameNode 概述 NameNode:在内存中储存 HDFS 文件的元数据信息(目录) 如果节点故障或断电,存在内存中的数 ...
随机推荐
- List<Activity> lists的关闭finish()
public class App extends Application { private static List<Activity> lists = new ArrayList< ...
- Python os.pathconf() 方法
概述 os.pathconf() 方法用于返回一个打开的文件的系统配置信息.高佣联盟 www.cgewang.com Unix 平台下可用. 语法 fpathconf()方法语法格式如下: os.fp ...
- 新手程序员求职简历缺少这 3 点!别说8k薪资,4K你可能都拿不到!
制作一份简历可能需要八百到千字,但HR看简历的时间只不过短短十秒,甚至可以说是一目十行. 我想针对想做程序员的刚毕业的学生分享着一点自己在求职招聘方面的感悟,不针对工作了多年的老同志了.快毕业那会儿, ...
- luogu P4284 [SHOI2014]概率充电器 期望 概率 树形dp
LINK:概率充电器 大概是一个比较水的题目 不过有一些坑点. 根据期望的线性性 可以直接计算每个元件的期望 累和即为答案. 考虑统计每一个元件的概率的话 那么对其有贡献就是儿子 父亲 以及自己. 自 ...
- MR程序的几种提交运行模式
本地模式运行 1-在windows的eclipse里面直接运行main方法 将会将job提交给本地执行器localjobrunner 输入输出数据可以放在本地路径下 输入输出数据放在HDFS中:(hd ...
- C++的常用输入及其优化以及注意事项
$\mathcal{P.S:}$ 对于输入方式及其优化有了解的大佬可直接阅读$\mathcal{Part}$ $\mathcal{2}$ 特别鸣谢:@归斋目录: $\mathcal{Part}$ $\ ...
- 从入门到熟悉HTTPS的9个问题
原文:bestswifter https://juejin.im/post/58c5268a61ff4b005d99652a Q1: 什么是 HTTPS? BS: HTTPS 是安全的 HTTP ...
- 【AHOI2009】中国象棋 题解(线性DP+数学)
前言:这题主要是要会设状态,状态找对了问题迎刃而解. --------------------------- 题目描述 这次小可可想解决的难题和中国象棋有关,在一个N行M列的棋盘上,让你放若干个炮(可 ...
- 基于boost的bind与function的一个简单示例消息处理框架
前两年开始接触boost,boost库真是博大精深:今天简单介绍一下boost中之前用到的的bind与function,感觉挺实用的,分享给大家,我对boost用的也不多,让大家见笑了. 上次文发了一 ...
- MySQL数据库高可用方案
一.什么是高可用性: 高可用性=可靠性,它的本质就是通过技术和工具提高可靠性,尽可能长时间保持数据可用和系统运行,实现高可用性的原则,首先要消除单点故障,其次通过冗余机制实现快速恢复,还有就是实现容错 ...