吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第三周:浅层神经网络(Shallow neural networks) -课程笔记
第三周:浅层神经网络(Shallow neural networks)
3.1 神经网络概述(Neural Network Overview)
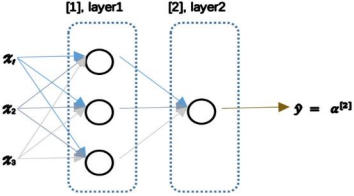
使用符号$ ^{[]}$表示第层网络中 节点相关的数,这些节点的集合被称为第层网络。
【1】初始:前向:
计算梯度
【2】第二层:类似只不过x=\(a^{[1]}\):
在逻辑回归中,通过直接计算得 到结果。而这个神经网络中,我们反复的计算和,计算和,最后得到了最终的输出 loss function。
3.2 神经网络的表示(Neural Network Representation)
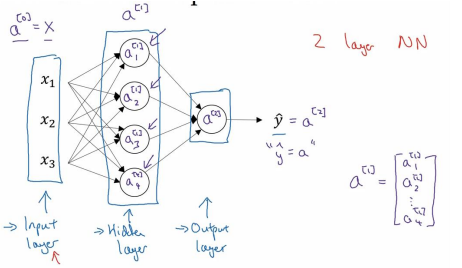
输入层:\(x_1,x_2,x_3\)
隐藏层 hidden layer 有两个参数\(W,b\),\(^{[1]}(W^{[1]},b^{[1]})\)表示这些参数是和第一层隐藏层有关。是一个 4x3 的矩阵,而是一个 4x1 的向量
输出层 output layer 负责产生预测值
因为不将输入层看作一个标准的层,故而称为一个两层的神经网络。
3.3 计算一个神经网络的输出(Computing a Neural Network's output)
神经元的计算与逻辑回归一样分为两步:
第一步,计算\(_1^{[1]} , _1{[1]} = _1^{[1]}+_1^{[1]}\)。
第二步,通过激活函数计算\(_1^{[1]} , _1^{[1]} = (_1^{[1]})\)。
隐藏层的第二个以及后面两个神经元的计算过程一样,只是注意符号表示不同
向量化计算:
3.4 多样本向量化(Vectorizing across multiple examples)
如何向量化多个训练样本,并计算出结果:
逻辑回归是将各个训练样本组合成矩阵,对矩阵的各列进行计算。神经网络是通过对逻辑回归中的等式简单的变形,让神经网络计算出输出值。这种计算是所有的训练样本同时进行的
想计算个训练样本上的所有输出,就应该向量化整个计算
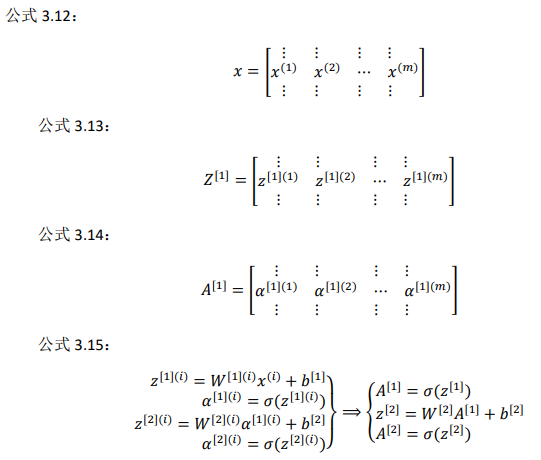
3.5 向 量 化 实 现 的 解 释 ( Justification for vectorized implementation)
为什么上一节中写下的公式就是将多个样本向量 化的正确实现。
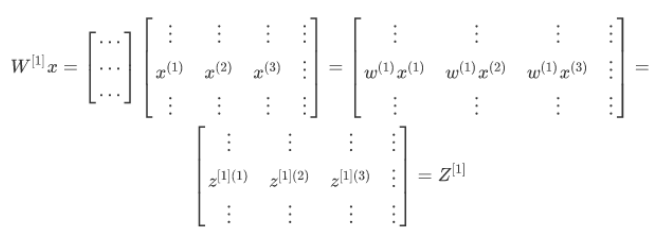
为当有不同的训练样本时,将它们堆到矩阵的各列中,那么 它们的输出也就会相应的堆叠到矩阵 \( ^{[1]}\) 的各列中
类似的分析可以发现,前向传播的其它步也可以使用非常相似的逻辑,即如果将输入 按列向量横向堆叠进矩阵,那么通过公式计算之后,也能得到成列堆叠的输出。
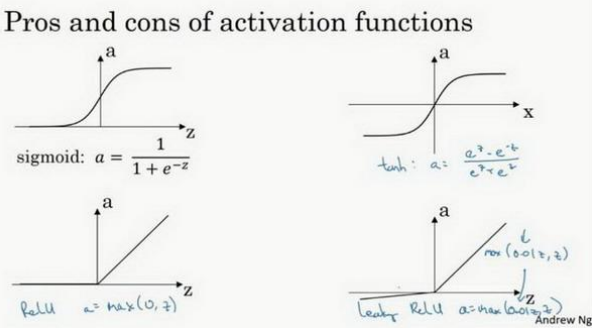
3.6 激活函数(Activation functions)
sigmoid 函数:
\(a=\sigma(z)=\frac{1}{1+e^{-z}}\)
更通常的情况下,使用不同的函数\((^{[1]} )\),可以是除了 sigmoid 函数意外的非线性函 数。
tanh 函数或者双曲正切函数是总体上都优于 sigmoid 函数的激活函数:
\(a=tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}\)
tanh 函数是 sigmoid 的向下平移和伸缩后的结果。对它进行了变形后,穿过了 (0,0)点,并且值域介于+1 和-1 之间。
结果表明,如果在隐藏层上使用函数$ℎ(^{1} ) $效果总是优于 sigmoid 函数。因为函数值域在-1 和+1 的激活函数,其均值是更接近零均值的。在训练一个算法模型时,如果使用 tanh 函数代替 sigmoid 函数中心化数据,使得数据的平均值更接近 0 而不是 0.5. 这会使下一层学习简单一点
tanh 函数在 所有场合都优于 sigmoid 函数。 但有一个例外:在二分类的问题中,对于输出层,因为的值是 0 或 1,所以想让^的数 值介于 0 和 1 之间,而不是在-1 和+1 之间。所以需要使用 sigmoid 激活函数。
\(g(^{[2]} ) = (^{[2]} )\)
在这个例子里,对隐藏层使用 tanh 激活函数,输出层使用 sigmoid 函数。
sigmoid 函数和 tanh 函数两者共同的缺点是,在特别大或者特别小的情况下,导数的 梯度或者函数的斜率会变得特别小,最后就会接近于 0,导致降低梯度下降的速度。
另一个很流行的函数是:修正线性单元的函数(ReLu)
= (0, )
只要是正值的情况下,导数恒等于 1,当是负 值的时候,导数恒等于 0。从实际上来说,当使用的导数时,=0 的导数是没有定义的。但 是当编程实现的时候,的取值刚好等于 0.00000001,这个值相当小,所以,在实践中,不 需要担心这个值,是等于 0 的时候,假设一个导数是 1 或者 0 效果都可以。
一些选择激活函数的经验法则:
如果输出是 0、1 值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单 元都选择 Relu 函数。
另一个版本的 Relu 被称为 Leaky Relu:
当是负值时,这个函数的值不是等于 0,而是轻微的倾斜:
这个函数通常比 Relu 激活函数效果要好,尽管在实际中 Leaky ReLu 使用的并不多。
两者的优点是:
第一,在的区间变动很大的情况下,激活函数的导数或者激活函数的斜率都会远大于 0,在程序实现就是一个 if-else 语句,而 sigmoid 函数需要进行浮点四则运算,在实践中, 使用 ReLu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。
第二,sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和 Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。(同时应该注 意到的是,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性, 而 Leaky ReLu 不会有这问题)
在 ReLu 的梯度一半都是 0,但是,有足够的隐藏层使得 z 值大于 0,所以对大多数的 训练数据来说学习过程仍然可以很快。
概括一下:
sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。 tanh 激活函数:tanh 是非常优秀的,几乎适合所有场合。 ReLu 激活函数:最常用的默认函数,,如果不确定用哪个激活函数,就使用 ReLu 或者 Leaky ReLu-- = (0.01, )
3.7 为什么需要非线性激活函数?(why need a nonlinear activation function?)
事实证明:要让你的神经网络能够计算出有趣的函数,你必须使用非线性激活函数:
如果只用线性激活函数或者叫恒等激励函数,那么神经网络只是把输入线性组合再输出。

事实证明,如果使用线性激活函数或者没有使用一个激活函数,那么无论神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。事实证明如果在隐藏层用线性激活函数,在输出层用 sigmoid 函数,那么这个模型的复杂度和没有任何隐藏层的标准 Logistic 回归是一样的
只有一个地方可以使用线性激活函数------() = ,就是在做机器学习中的回归问题:
是一个实 数,举个例子,比如你想预测房地产价格, 就不是二分类任务 0 或 1,而是一个实数,从 0 到正无穷。如果 是个实数,那么在输出层用线性激活函数也许可行,你的输出也是一个 实数,从负无穷到正无穷。
唯一可以用线性激活函数的通常就是输出层;除了这种情况,会在隐层用线性函数的,也有一些特殊情况,比如与压缩有关的,在这里不深入讨论。总之在隐层使用线性激活函数非常少见。
3.8 激活函数的导数(Derivatives of activation functions)
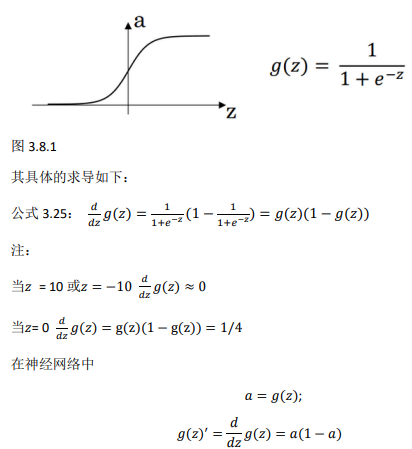
1、sigmoid activation function:
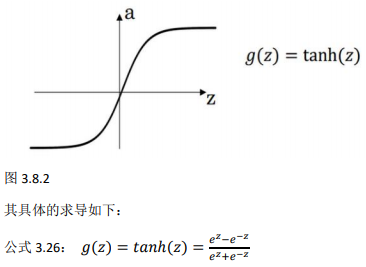
2、Tanh activation function:

3、Rectified Linear Unit (ReLU):
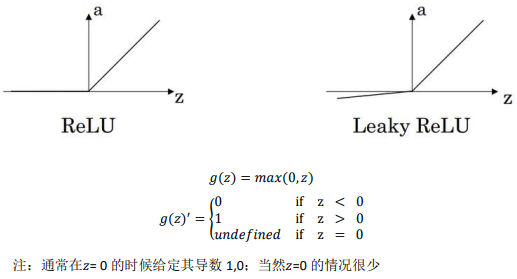
4、Leaky linear unit (Leaky ReLU)

3.9 神 经 网 络 的 梯 度 下 降 ( Gradient descent for neural networks)
以二分类任务为例:
Cost function: 公式:$ (^{1} , ^{1} , ^{[2]} , ^{[2]}) = \frac{1}{}\sum_{i=1}^mL(\hat{y} , )$
loss function 和之前做 logistic 回归完全一样:\(L(a,y)=-( ylog(a)+(1-y)log(1-a) )\)
训练参数需要做梯度下降,在训练神经网络的时候,随机初始化参数很重要,而不是初 始化成全零。当你参数初始化成某些值后,每次梯度下降都会循环计算以下预测值:
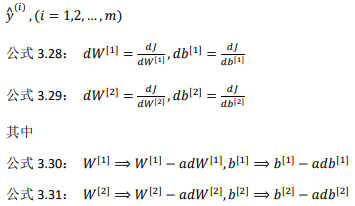
正向传播:

反向传播:

是1 × 的矩阵; 这里 np.sum 是 python 的 numpy 命令,axis=1 表示水平相加求和,keepdims 是防止 python 输出那些古怪的秩数(, ),加上这个确保阵矩阵 [2]这个向量输出的维度为(, 1)这 样标准的形式。
3.10(选修)直观理解反向传播(Backpropagation intuition)
逻辑回归的推导:
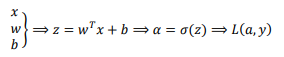
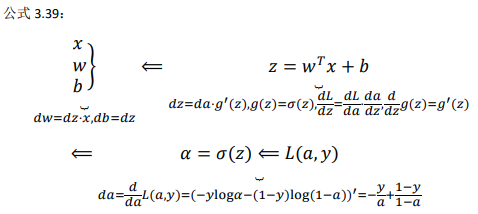
神经网络的计算中,与逻辑回归十分类似,但中间会有多层的计算:
前向传播: 计算\(^{[1]}\),\(^{ [1]}\),再计算\(^{ [2]}\),\(^{ [2]}\),最后得到 loss function。 反向传播: 向后推算出\(^{[2]}\),然后推算出\(^{[2]}\),接着推算出\(^{[1]}\),然后推算出\(^{[1]}\)。
向后推算出\(^{[2]}\),然后推算出\(^{[2]}\)的步骤 可以合为一步:


3.11 随机初始化(Random+Initialization)
对于一个神经网络,如果把权重或者参数都初始化为 0,那么梯度下降将不会起作用:

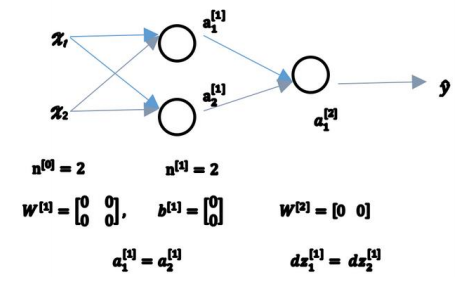
如果这样初始化这个神经网络,那么这两个隐含单元就会完全一样, 因此他们完全对称,也就意味着计算同样的函数,并且肯定的是最终经过每次训练的迭代, 这两个隐含单元仍然是同一个函数。
如果把权重都初始化为 0,那么由于隐含单元开始计算同一个函数, 所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同 的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管训练网络多 长时间,隐含单元仍然计算的是同样的函数。
要想两个不同的隐含单元计算不同的函数, 解决方法就是随机初始化参数:
把 \(^{[1]}\) 设 为 np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如 0.01,这样把它初始化为很小的随机数。然后没有这个对称的问题(叫做 symmetry breaking problem),所 以可以把 初始化为 0,因为只要随机初始化你就有不同的隐含单元计算不同的东西, 因此不会有 symmetry breaking 问题了:

0.01:
通常倾向于初始化为很小的随机数。因为如果用 tanh 或者 sigmoid 激活函数,或者说只在输出层有一个 Sigmoid,如果(数值)波动太大,当计算激活值时\(^{[1]} = ^{[1]} + ^{[1]}, ^{[1]} = (^{[1]} ) = ^{[1]} (^{[1]})\)如果很大,就会很大。的一些值就会很大或者很小,因此这种情况下很可能停在 tanh/sigmoid 函数的平坦的地方,这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
事实上有时有比 0.01 更好的常数,当训练一个只有一层隐藏层的网络时(这是相对浅的神经网络,没有太多的隐藏层),设为 0.01 可能也可以。但当训练一个非常非常深的神经网络,可能会选择一个不同于的常数而不是 0.01。
吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第三周:浅层神经网络(Shallow neural networks) -课程笔记的更多相关文章
- 吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分. 遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记. 有人说推导任意层MLP很容易,我 ...
- 吴恩达深度学习第2课第2周编程作业 的坑(Optimization Methods)
我python2.7, 做吴恩达深度学习第2课第2周编程作业 Optimization Methods 时有2个坑: 第一坑 需将辅助文件 opt_utils.py 的 nitialize_param ...
- 吴恩达深度学习第4课第3周编程作业 + PIL + Python3 + Anaconda环境 + Ubuntu + 导入PIL报错的解决
问题描述: 做吴恩达深度学习第4课第3周编程作业时导入PIL包报错. 我的环境: 已经安装了Tensorflow GPU 版本 Python3 Anaconda 解决办法: 安装pillow模块,而不 ...
- cousera 吴恩达 深度学习 第一课 第二周 作业 过拟合的表现
上图是课上的编程作业运行10000次迭代后,输出每一百次迭代 训练准确度和测试准确度的走势图,可以看到在600代左右测试准确度为最大的,74%左右, 然后掉到70%左右,再掉到68%左右,然后升到70 ...
- 吴恩达深度学习第2课第3周编程作业 的坑(Tensorflow+Tutorial)
可能因为Andrew Ng用的是python3,而我是python2.7的缘故,我发现了坑.如下: 在辅助文件tf_utils.py中的random_mini_batches(X, Y, mini_b ...
- 吴恩达深度学习第1课第3周编程作业记录(2分类1隐层nn)
2分类1隐层nn, 作业默认设置: 1个输出单元, sigmoid激活函数. (因为二分类); 4个隐层单元, tanh激活函数. (除作为输出单元且为二分类任务外, 几乎不选用 sigmoid 做激 ...
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 深度学习 吴恩达深度学习课程2第三周 tensorflow实践 参数初始化的影响
博主 撸的 该节 代码 地址 :https://github.com/LemonTree1994/machine-learning/blob/master/%E5%90%B4%E6%81%A9%E8 ...
随机推荐
- 面试中的老大难-mysql事务和锁,一次性讲清楚!
众所周知,事务和锁是mysql中非常重要功能,同时也是面试的重点和难点.本文会详细介绍事务和锁的相关概念及其实现原理,相信大家看完之后,一定会对事务和锁有更加深入的理解. 本文主要内容是根据掘金小册& ...
- eclipse中 sec/test/resource 文件夹消失怎么设置?
右键改包--->build path --->Configure bulid path 按 add Folder 搞定.....
- hdfs常用api(java)
1.下载文件到本地 public class HdfsUrlTest { static{ //注册url 让java程序识别hdfs的url URL.setURLStreamHandlerFactor ...
- 手把手教你写VueRouter
Vue-Router提供了俩个组件 `router-link` `router-view`, 提供了俩个原型上的属性`$route` `$router` ,我现在跟着源码来把它实现一下 开始 先看平时 ...
- jqgrid 获取选中用户的数据插入
因为查询出的表和被插入的表不是在同一个数据库,所以先从前台jqgrid表格中获取到数据后,再插入表中. 实现: 获取到jqgrid选中 的每行数据之后,发ajax请求把数据以json格式传入后台,后台 ...
- 多线程系列(二)之Thread类
在上一遍文章中讲到多线程基础,在此篇文章中我们来学习C#里面Thread类.Thread类是在.net framework1.0版本中推出的API.如果对线程的概念还不太清楚 的小伙伴请阅读我的上一遍 ...
- Finding the Right EAV Attribute Table
$customer = Mage::getModel('catalog/product'); $entity = $customer->getResource(); $attribute = M ...
- golang slice 简单排序
原文链接:https://www.jianshu.com/p/603be4962a62 demo package main import ( "fmt" "sort&qu ...
- failed to find romfile "vgabios-stdvga.bin"
问题:failed to find romfile "vgabios-stdvga.bin" 解决: apt-get install vgabios ln -s /usr/shar ...
- Git-commit-中添加表情
git commit 中使用表情 我们经常可以在github上看到国外大佬的commit信息中有很多可爱的表情,这是怎么做到的呢? ok,可以这样使用哦:git commit -m '提交信息 :em ...