【HBase】简介、结构、数据模型、快速入门部署、shell操作、架构原理、读写数据流程、数据刷写、压缩、分割、Phoenix、表的映射、与hive集成、优化
一、简介
1、定义
分布式、可扩展、支持海量数据存储的NoSQL数据库
2、数据模型
2.1逻辑结构
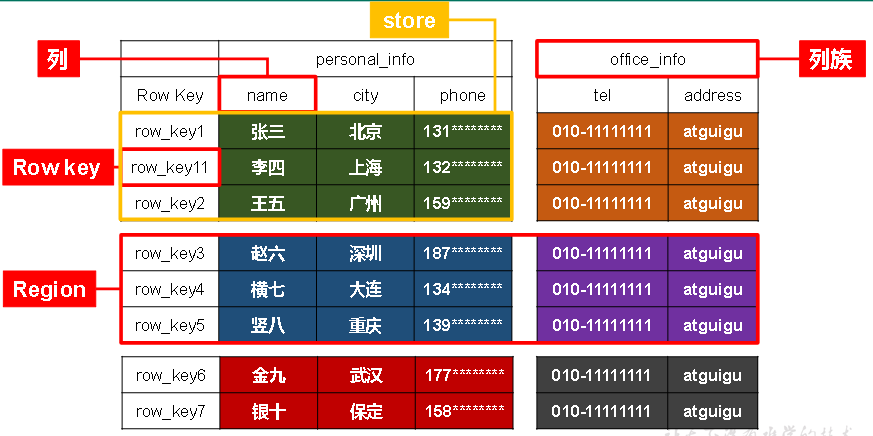
2.2物理存储结构
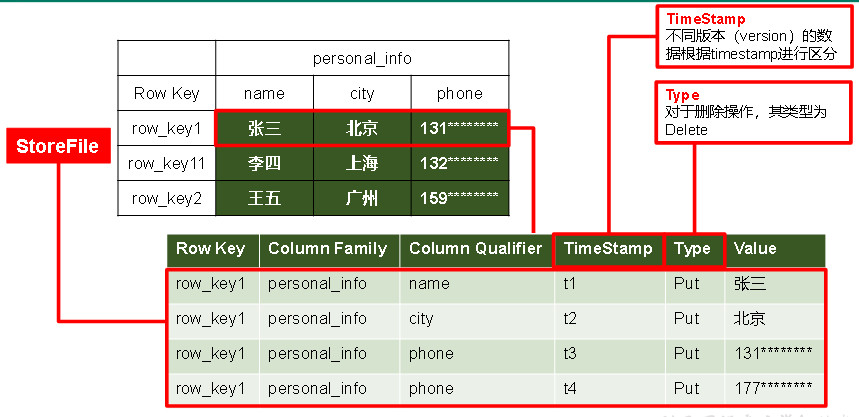
2.3数据模型介绍
Name Space:相当于数据库,包含很多张表
Region:类似于表,定义表时只需要声明列族,不需要声明具体的列。【字段可以动态、按需指定】
Row:每行数据按RowKey字典序存储,且只能根据RowKey检索
Column:由Column Family(列族)和Column Qualifier(列限定符,即列名,无需预先定义)进行限定,例如info:name,info:age。
Time Stamp:标识数据的不同版本
Cell:由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元/记录?
3、HBase基本架构
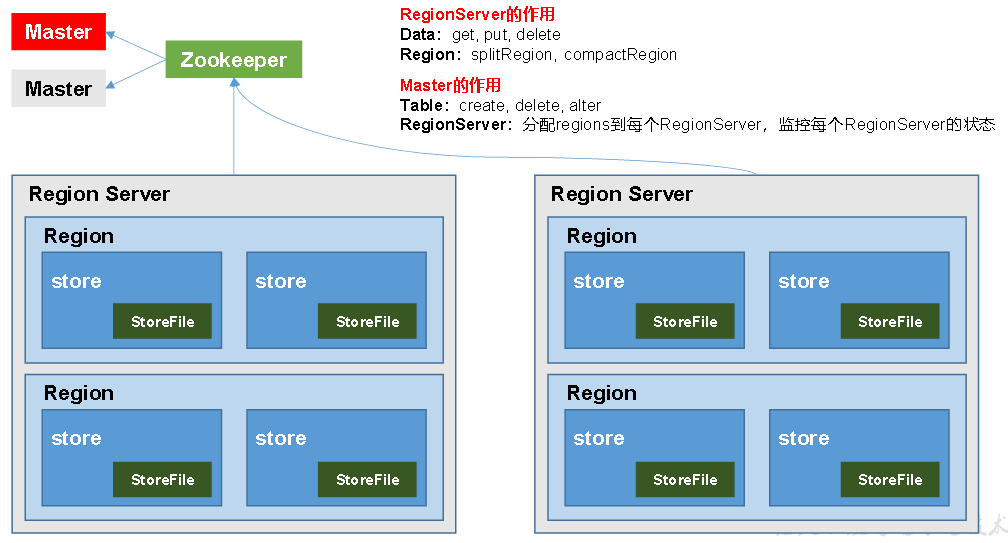
架构角色
Region Server:Region的管理者,其实现类为HRegionServer,可以实现对数据的操作(get, put, delete)和对Region的操作(splitRegion、compactRegion)
Master:Region Server的管理者,实现类为HMaster,可以实现对表的操作(create, delete, alter)和对Region Server的操作(分配regions、监控ser的状态、负载均衡和故障转移)
Zookeeper:Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护
HDFS:底层数据存储、HBase的高可用
二、HBase快速入门
1、安装部署
zk和Hadoop的部署
HBase的解压和配置文件修改:hbase-env.sh、hbase-site.xml
定义regionservers,软连接hadoop配置文件到HBase:ln -s a b
远程发送同步集群:xsync hbase/
启动HBASE:bin/hbase-daemon.sh start master及regionserver
启动方式2:bin/start-hbase.sh,查看页面:http://hadoop102:16010
对HMaster的HA高可用:
创建backup-masters文件并配置高可用HMaster节点:echo hadoop103 > conf/backup-masters
整个conf目录scp到其他节点:scp -r conf/ hadoop103:/opt/module/hbase/
2、Shell操作
进入命令行:bin/hbase shell
表的操作:create、put、scan、describe、count、delete、truncate清空表、get 'student','1001'指定行,'info:name'指定列族: 列、drop删除表、
三、HBASE进阶
1、架构原理
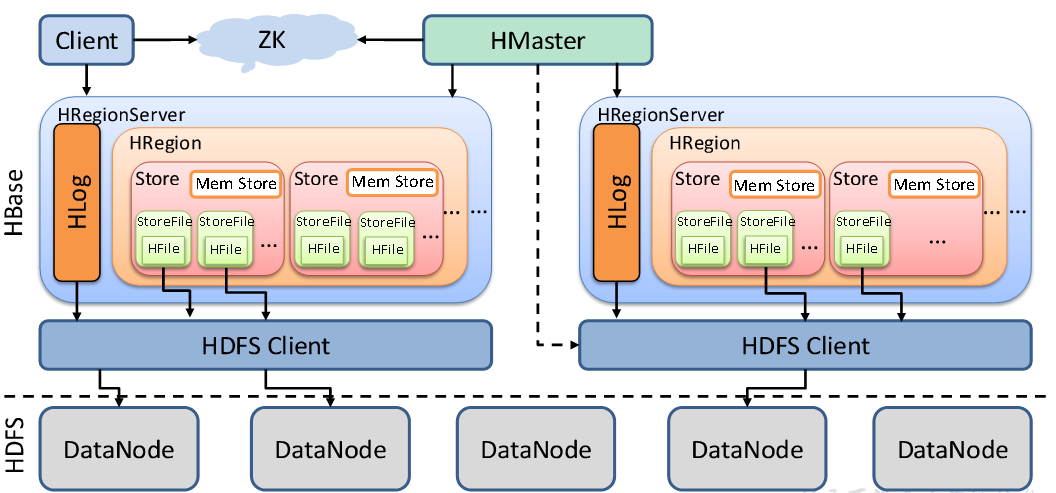
StoreFile:实际保存的物理文件,以HFile的形式存储在HDFS上,数据有序
MemStore:写缓存,先存储在MemStore中,排好序再刷写到StoreFile
WAL:写内存容易数据丢失,先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中;系统出现故障的时候,数据可以通过这个日志文件重建。
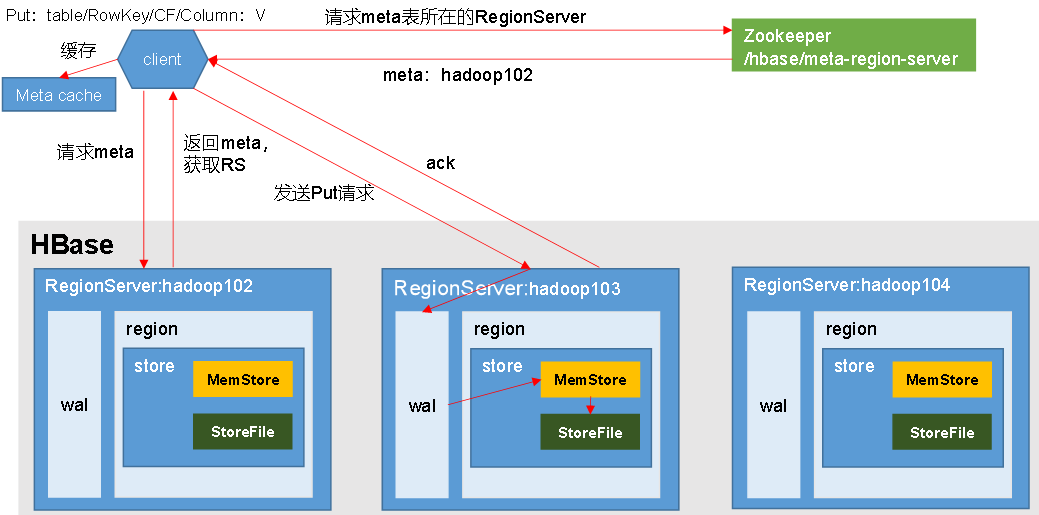
2、写数据的流程
通过zk获取Region Server地址
(追加)到WAL,写入对应的MemStore
向client发送ack,等到刷写时机后,将数据刷写到HFile
3、MemStore Flush数据刷写
某个Mem Store达到配置值时
memstore的总大小达到java_heapsize时
到达自动刷写的时间,也会触发memstore flush
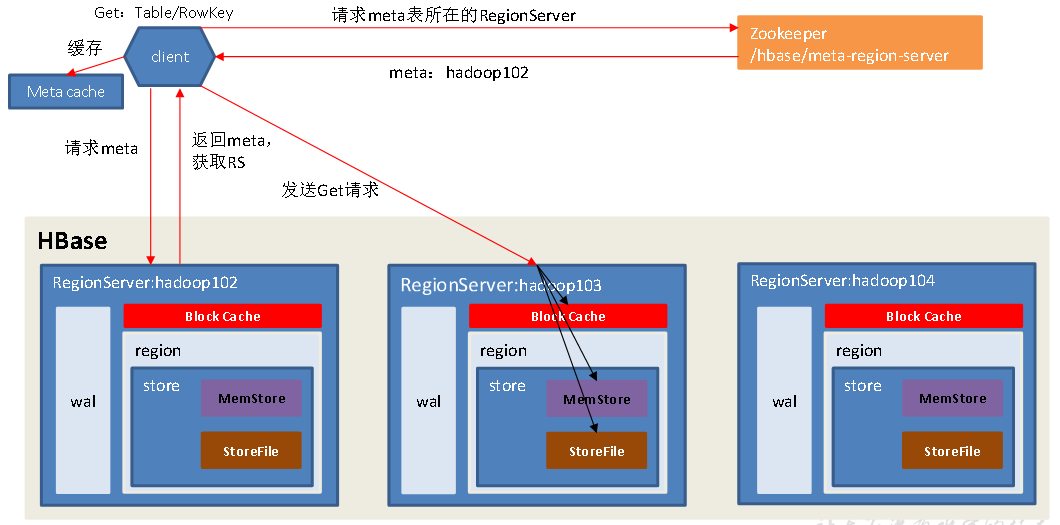
4、读流程
访问zk,获取hbase:meta表位于哪个Region Server
根据读请求的namespace:table/rowkey获取region并缓存到meta cache
查询目标数据并合并
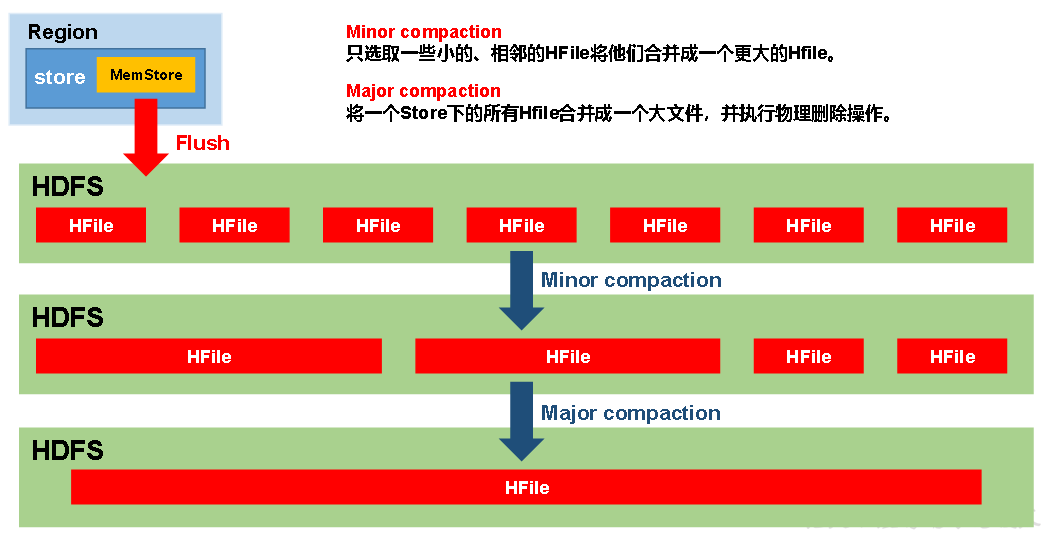
5、StoreFile Compaction
memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile
为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Minor Compaction:临近的HFile合并,但不会清理删除
Major Compaction:Store下的所有HFile合并,同时会清理和删除
6、Region Split
每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分
由于负载均衡,可能会将当前table的region转移到其他region server上

四、整合Phoenix
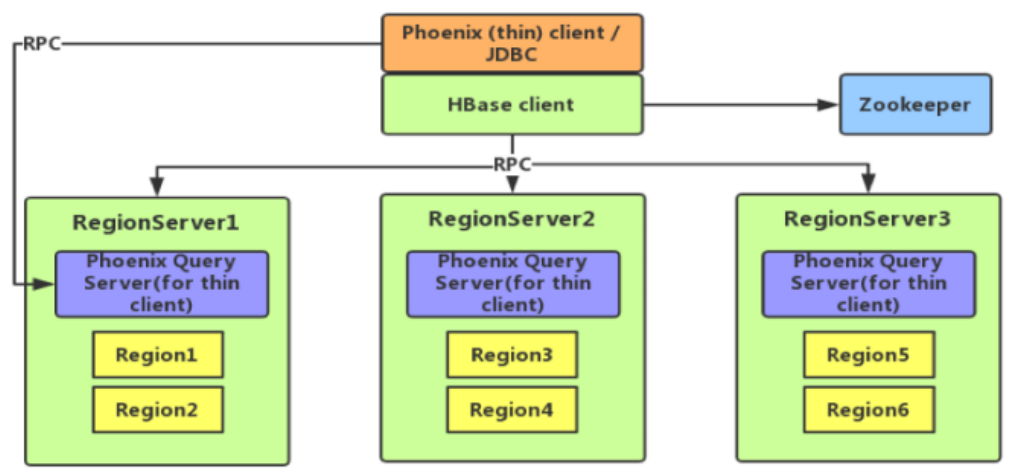
1、Phoenix简介
定义:可以使用标准JDBC API代替HBase客户端API
特点:容易集成、操作简单、支持二级索引
Phoenix架构:
2、快速入门
安装bsdtar3、上传解压jar包、【server和client】拷贝到各个节点的hbase/lib
启动:/opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
Shell操作
显示所有表:!tables
建表:表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。指定多个列的联合作为RowKey
插入数据:upsert into student values('1001','zhangsan');
退出命令行:!quit
3、表的映射
视图映射和表映射
进入命令行:/opt/module/hbase-1.3.1/bin/hbase shell
建表:create 'test','info1','info2'
创建关联test表的视图:create view "test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar);
删除视图:drop view "test";
JDBC操作
4、Phoenix二级索引
协处理器
二级索引配置文件
全局二级索引:创建新表,适用于多读少写的业务场景
本地二级索引:Local Index适用于写操作频繁
五、与Hive的集成
1、HBase与Hive的对比



2、与Hive集成使用
2.1 插入数据到Hive表的同时能够影响HBase表:hive-中间表-hbase
Hive中创建表同时关联HBase
Hive中创建临时中间表,用于load文件中的数据
向Hive中间表中load数据
insert命令将中间表中的数据导入到Hive关联Hbase的那张表中
2.2借助Hive来分析HBase这张表
Hive中创建外部表
使用Hive函数进行一些分析操作
六、HBase优化
1、预分区:提前规划region分区,提高性能
create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
手工设定、生成16进制序列、按文件规则、使用java api
2、RowKey设计
随机数、hash、散列值
字符串反转、拼接
3、内存优化
16~48G内存
4、基础优化,配置hbase-site.xml
允许在HDFS的文件中追加内容
优化DataNode允许的最大文件打开数
优化延迟高的数据操作的等待时间
优化数据的写入效率
设置RPC监听数量
优化HStore文件大小
指定scan.next扫描HBase所获取的行数
flush、compact、split机制
【HBase】简介、结构、数据模型、快速入门部署、shell操作、架构原理、读写数据流程、数据刷写、压缩、分割、Phoenix、表的映射、与hive集成、优化的更多相关文章
- 其他主流开源硬件简介BeagleBone Black快速入门
其他主流开源硬件简介BeagleBone Black快速入门 1.3 其他主流开源硬件简介 开源硬件种类繁多,但主要有两款开源硬件常与BeagleBone比较.它们就是Arduino和Raspberr ...
- 【第一篇】ASP.NET MVC快速入门之数据库操作(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- Flask简介,安装,demo,快速入门
1.Flask简介 Flask是一个相对于Django而言轻量级的Web框架. 和Django大包大揽不同,Flask建立于一系列的开源软件包之上,这其中 最主要的是WSGI应用开发库Werkzeug ...
- Hbase简介以及简单的入门操作
Hbase是一个分布式的.面向列的开源数据库,可实时的读写.随机访问超大规模的数据集. Hbase主要分为两种模型: 逻辑模型和物理模型 1. 逻辑模型 Hbase的名字的来源是Hadoop data ...
- Shell基础快速入门 了解shell运行原理
Shell简介 Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁.Shell 既是一种命令语言,又是一种程序设计语言. Shell 是指一种应用程序,这个应用程序提供了一个界 ...
- ADO.NET 快速入门(十三):使用 OLE DB 检索数据
OleDbDataReader 类提供了一种从数据源读取数据记录只进流的方法.如果想使用 SQL Server 7.0 或者更高版本,请参考文章:使用 SQL Server 检索数据. OleDb ...
- istio部署-快速入门
参考 istio/istio Quick Start Evaluation Install fleeto/sleep fleeto/flaskapp 本文为 istio 快速入门部署,一般用于演示环境 ...
- 【第二篇】ASP.NET MVC快速入门之数据注解(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- 【番外篇】ASP.NET MVC快速入门之免费jQuery控件库(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- 【第三篇】ASP.NET MVC快速入门之安全策略(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
随机推荐
- 合理编写C++模块(.h、.cc)
模块划分 合理编写模块的 demo.h.demo.cc 下例为C++为后端服务编写的探活检测服务 health_server.h #ifndef HEALTH_SERVER_H #define HEA ...
- 4_Spring
一. Spring Spring的基本组成: 1.最完善的轻量级核心框架. 2.通用的事务管理抽象层. 3.JDBC抽象层. 4.集成了Toplink, Hibernate, JDO, and iBA ...
- javaweb 导出文件名乱码的问题解决方案
fileName = new String(fileName.getBytes("ISO8859-1"), "UTF-8"); 或者 String finalF ...
- pgsql 的问题
pgsql 怎么插入inet类型的数据?insert into table (remote_addr) values ( ?::INET); pgsql如何截取时间的精度 select create ...
- Docker | dockerfile构建centos镜像,以及CMD和ENTRYPOINT的区别
构建自己的centos镜像 docker pull centos下载下来的镜像都是基础版本,缺少很多常用的命令功能,比如:ll.vim等等, 下面介绍制作一个功能较全的自己的centos镜像. 步骤 ...
- 1.RabbitMQ系列之服务启动
1. docker方式启动MQ # latest RabbitMQ 3.10 docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:156 ...
- C语言两个升序递增链表逆序合并为一个降序递减链表,并去除重复元素
#include"stdafx.h" #include<stdlib.h> #define LEN sizeof(struct student) struct stud ...
- python信息检索实验之向量空间模型与布尔检索
import numpy as np import pandas as pd import math def bool_retrieval(string): if string.count('and' ...
- 微信小程序之顶部导航栏
wxml: <!--导航条--><view class="navbar"> <text wx:for="{{navbar}}" d ...
- CH58X服务修改
在对ble系列应用时,很多时候拿手机充当主机.在使用ble 调试助手时常会用到write.read.notify等功能.有时可能会根据自己的需求对这些服务进行修改.下图是官方例程体现出的service ...