Java 流处理之收集器
Java 流(Stream)处理操作完成之后,我们可以收集这个流中的元素,使之汇聚成一个最终结果。这个结果可以是一个对象,也可以是一个集合,甚至可以是一个基本类型数据。
以记录 Record 为例:
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Record {
private String col1;
private String col2;
private int col3;
}
记录 Record 包含三个属性:列1(col1)、列2(col2)和 列3(col3)。
创建四个记录实例:
Record r1 = new Record("a", "1", 1);
Record r2 = new Record("a", "2", 2);
Record r3 = new Record("b", "3", 3);
Record r4 = new Record("c", "4", 4);
添加到列表:
List<Record> records = new ArrayList<>();
records.add(r1);
records.add(r2);
records.add(r3);
records.add(r4);
收集所有记录的 列1 值,以列表形式存储结果
List<String> col1List = records.stream()
.map(Record::getCol1)
.collect(Collectors.toList());
log.info("col1List: {}", Json.toJson(col1List));
输出结果:
col1List: ["a","a","b","c"]
收集所有记录的 列1 值,且去重,以集合形式存储
Set<String> col1Set = records.stream()
.map(Record::getCol1)
.collect(Collectors.toSet());
log.info("col1Set: {}", Json.toJson(col1Set));
输出结果:
col1Set: ["a","b","c"]
收集记录的 列2 值和 列3 值的对应关系,以字典形式存储
Map<String, Integer> col2Map = records.stream()
.collect(Collectors.toMap(Record::getCol2, Record::getCol3));
log.info("col2Map: {}", Json.toJson(col2Map));
输出结果:
col2Map: {"1":1,"2":2,"3":3,"4":4}
记录的 列2 不能有重复值,否则会抛出 Duplicate key 异常。
收集所有记录中 列3 值最大的记录
Record max = records.stream()
.collect(Collectors.maxBy(Comparator.comparing(Record::getCol3)))
.orElse(null);
log.info("max: {}", Json.toJson(max));
输出结果:
max: {"col1":"c","col2":"4","col3":4}
收集所有记录中 列3 值的总和
int sum = records.stream()
.collect(Collectors.summingInt(Record::getCol3));
log.info("sum: {}", sum);
输出结果:
sum: 10
流的收集需要通过 Stream.collect() 方法完成,方法的参数是一个 Collector(收集器);收集结果时,需要根据收集结果的目标类型,传递特定的收集器实例,如上:
- Collectors.toList()
- Collectors.toSet()
- Collectors.toMap()
- Collectors.maxBy()
- Collectors.summingInt()
Collectors(java.util.stream.Collectors) 是一个工具类,内置若干收集器,我们可以通过调用不同的方法快速获取相应的收集器实例。
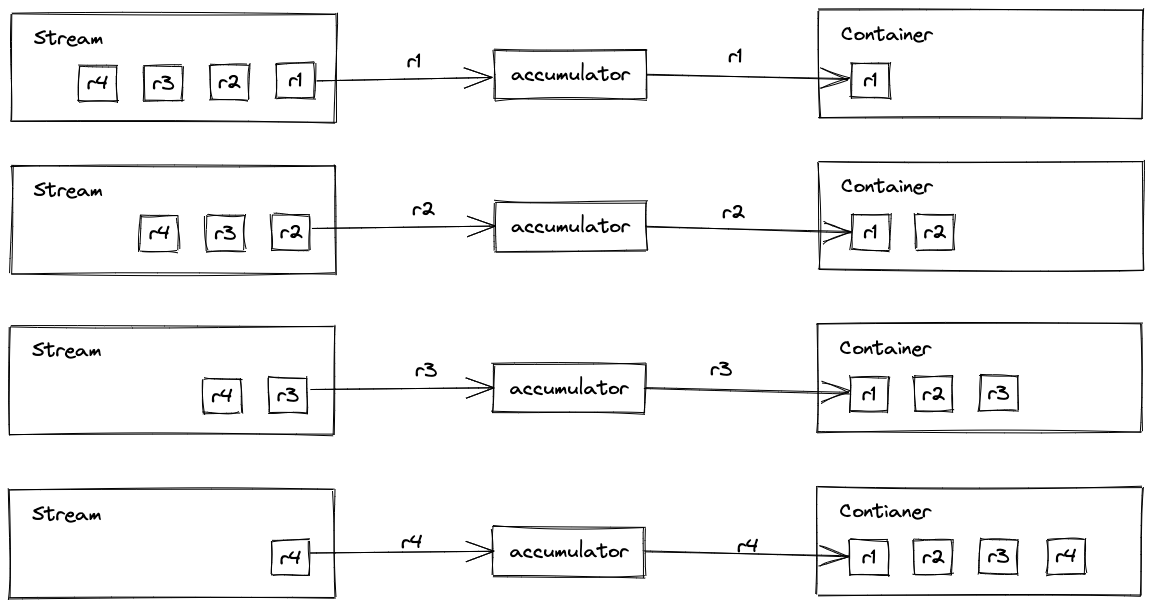
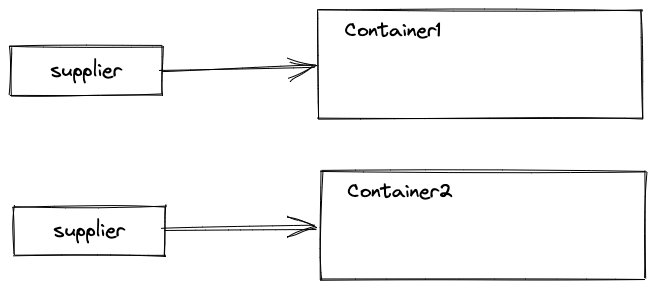
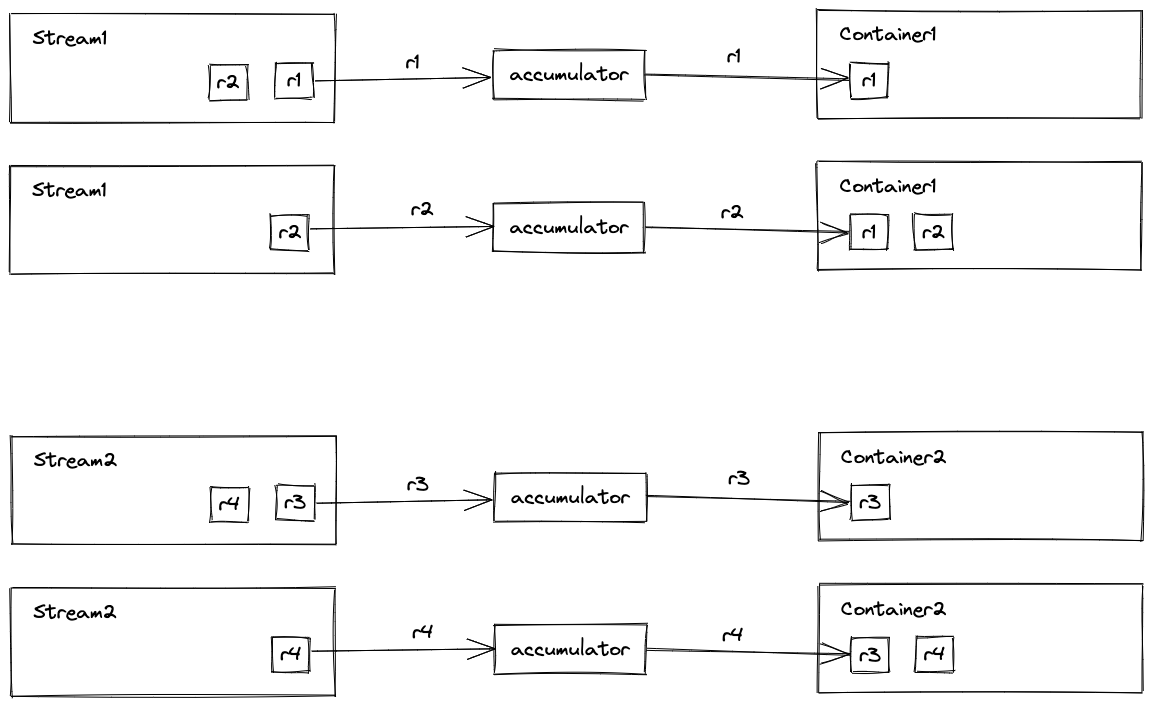
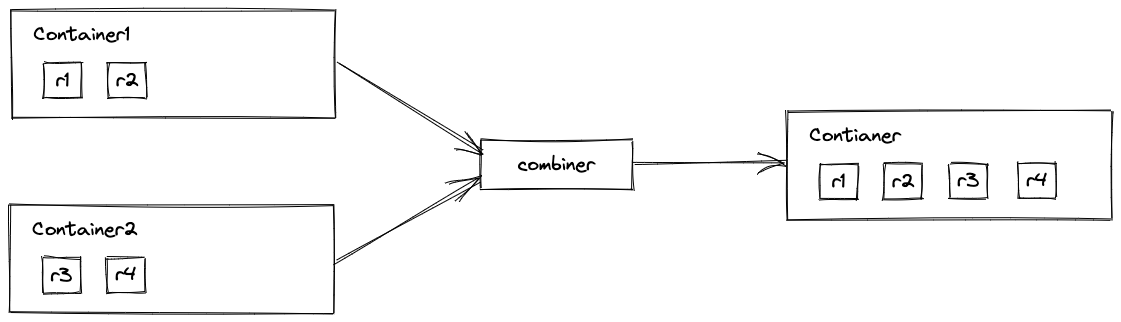
收集器(java.util.stream.Collector)本质是一个 接口,包含以下五个方法:


Java 流处理之收集器的更多相关文章
- JAVA流式布局管理器--JAVA基础
JAVA流式布局管理器的使用: FlowLayoutDeme.java: import java.awt.*;import javax.swing.*;public class FlowLayoutD ...
- JAVA 流式布局管理器
//流式布局管理器 import java.awt.*; import javax.swing.*; public class Jiemian2 extends JFrame{ //定义组件 JBut ...
- 深入理解Java虚拟机03--垃圾收集器与内存分配策略
一.概述 哪些内存需要回收? 什么时候回收? 如何回收? 二.对象已死吗 1.引用计数算法 定义:给对象添加一个引用计数器,当增加一个引用时,加1,当一个引用时,减1; 缺陷:当对象之间互相循环 ...
- [一] java8 函数式编程入门 什么是函数式编程 函数接口概念 流和收集器基本概念
本文是针对于java8引入函数式编程概念以及stream流相关的一些简单介绍 什么是函数式编程? java程序员第一反应可能会理解成类的成员方法一类的东西 此处并不是这个含义,更接近是数学上的 ...
- JAVA8给我带了什么——流的概念和收集器
到现在为止,笔者不敢给流下定义,从概念来讲他应该也是一种数据元素才是.可是在我们前面的代码例子中我们可以看到他更多的好像在表示他是一组处理数据的行为组合.这让笔者很难去理解他的定义.所以笔者不表态.各 ...
- Stream01 定义、迭代、操作、惰性求值、创建流、并行流、收集器、stream运行机制
1 Stream Stream 是 Java 8 提供的一系列对可迭代元素处理的优化方案,使用 Stream 可以大大减少代码量,提高代码的可读性并且使代码更易并行. 2 迭代 2.1 需求 随机创建 ...
- Java GC收集器配置说明
根据Java GC收集器具体分类,我们可以看出JVM根据需求不同提供了三种选择:串行收集器.并行收集器.并发收集器. 串行收集器只适用于小数据量的情况,我们主要了解一下并行收集器和并发收集器.默认情况 ...
- JAVA G1收集器 第11节
JAVA G1收集器 第11节 上两章我们讲了新生代和年老代的收集器,那么这一章的话我们就要讲一个收集范围涵盖整个堆的收集器——G1收集器. 先讲讲G1收集器的特点,他也是个多线程的收集器,能够充分利 ...
- JAVA 年老代收集器 第10节
JAVA 年老代收集器 第10节 上一章我们讲了新生代的收集器,那么这一章我们要讲的就是关于老年代的一些收集器.老年代的存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域 ...
随机推荐
- js烧脑面试题大赏
本文精选了20多道具有一定迷惑性的js题,主要考察的是类型判断.作用域.this指向.原型.事件循环等知识点,每道题都配有笔者详细傻瓜式的解析,偏向于初学者,大佬请随意. 第1题 let a = 1 ...
- 实践GoF的23种设计模式:装饰者模式
摘要:装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力.理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性. 本文分享自华为云社区<[Go实现]实践GoF的2 ...
- cup缓存基础知识
目录 cup缓存 缓存结构 直接映射缓存 cup缓存 CPU缓存(CPU Cache)的目的是为了提高访问内存(RAM)的效率,这虽然已经涉及到硬件的领域,但它仍然与我们息息相关,了解了它的一些原理, ...
- 多线程与高并发(一)—— 自顶向下理解Synchronized实现原理
一. 什么是锁? 在多线程中,多个线程同时对某一个资源进行访问,容易出现数据不一致问题,为保证并发安全,通常会采取线程互斥的手段对线程进行访问限制,这个互斥的手段就可以称为锁.锁的本质是状态+指针,当 ...
- day01--DOS常用命令
打开CMD的方式 开始+系统+命令提示符 Win键+R输入cmd打开控制台(推荐使用) 在任意的文件夹下面,按住shift键+鼠标右键点击,在此处打开命令行窗口 资源管理器的地址栏前面加,上cmd路径 ...
- 【New】Code Insertion
#include <bits/stdc++.h> using namespace std; #define Multicase() for(int T = read() ; T ; T-- ...
- js基础学习-数组
let arr1 = [ {name: 1} ] let arr2 = [ {age: 23} ] let ages = [11, 22, 23] let newArr = arr1.concat(a ...
- 【HMS core】【FAQ】HMS Toolkit典型问题合集1
1.[开发工具][HMS Toolkit][问题描述] HMS Toolkit 插件导致Android Studio崩溃无法使用 [解决方案] 1) 检查Android Studi ...
- word count的reduce过程以及项目打包部署
map过程已经写完了,上面那个流程我们涉及到了泛型以及序列化,我们要知道每个参数代表的含义,这样有助于我们理解整个流程. 下面我们开始reduce,这个过程我们要把map输出的键值对把key值相同的放 ...
- java日常开发必备:list的四种遍历
在平时的开发过程中使用List的场景很多,你知道List的遍历有多少种方式?今天一起来梳理下List的几种遍历方式.这里以java.util.ArrayList为例来演示. 这里有一个最简单的 ...