关系网络数据可视化:2. Python数据预处理
将数据中导演与演员的关系整理出来,得到导演与演员的关系数据,并统计合作次数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline import warnings
warnings.filterwarnings('ignore')
# 不发出警告
# 读取数据 import os
# os.chdir('C:/Users/Hjx/Desktop/')
os.chdir(r'C:\Users\Administrator\Desktop\ch0304_data')
df = pd.read_excel('豆瓣电影数据.xlsx',sheetname=0,header=0)
print('数据总共%i条' % len(df))
print('数据字段为:\n',df.columns.tolist())
df.head(2)
# 查看数据

#数据清洗
data = df[['name', '导演', '主演']]
data.dropna(inplace = True)
data.head()
data_yy = data['主演'].str.split('/ ', expand=True)
col_len1 = len(data_yy.columns)
data_yy.columns = ['yy'+str(i) for i in range(col_len1)]
data_yy.head()

data_dy = data['导演'].str.split('/ ', expand=True)
col_len2 = len(data_dy.columns)
data_dy.columns = ['dy'+str(i) for i in range(col_len2)]
data_dy.head()
data2 = data_dy.join(data_yy).join(data['name'])
data2.head()

#拆分+合并 data_re = pd.DataFrame(columns=['name','导演','演员'])
# 创建一个空的Dataframe col_yy = data_yy.columns
col_dy = data_dy.columns for dy in col_dy:
for yy in col_yy:
data_i = data2[['name', dy, yy]].dropna() # 提取数据
data_i.columns = ['name', '导演', '演员'] ## 列名重命名
# print(data_i)
data_re = pd.concat([data_re, data_i]) # 添加数据
print(data_re.head())
# 遍历数据后,得到一个导演与演员的关系数据,并做去重处理
# 这里index是有重复的,但作为过程数据可忽略

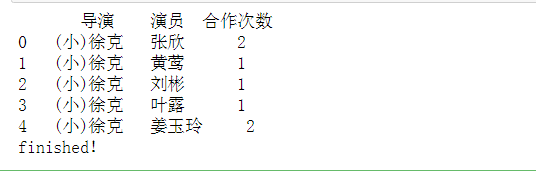
# 汇总统计导演和演员的合作次数 result = data_re.groupby(['导演','演员']).count()
result.reset_index(inplace=True)
result.columns = ['导演','演员','合作次数']
print(result.head())
# 按照导演-演员进行计数统计,得到结果数据
# reset_index() → 将所有索引级别转换为列 writer = pd.ExcelWriter('output.xlsx')
result.to_excel(writer,'sheet1')
writer.save()
# 存为excel
# 注意:output.xlsx文件不能是打开状态 print('finished!')
关系网络数据可视化:2. Python数据预处理的更多相关文章
- 【数据科学】Python数据可视化概述
注:很早之前就打算专门写一篇与Python数据可视化相关的博客,对一些基本概念和常用技巧做一个小结.今天终于有时间来完成这个计划了! 0. Python中常用的可视化工具 Python在数据科学中的地 ...
- 分形、分形几何、数据可视化、Python绘图
本系列采用turtle.matplotlib.numpy这三个Python工具,以分形与计算机图像处理的经典算法为实例,通过程序和图像,来帮助读者一步步掌握Python绘图和数据可视化的方法和技巧,并 ...
- caffe(13) 数据可视化(python接口)配置
caffe程序是由c++语言写的,本身是不带数据可视化功能的.只能借助其它的库或接口,如opencv, python或matlab.大部分人使用python接口来进行可视化,因为python出了个比较 ...
- 数据可视化:使用python代码实现可视数据随机漫步图
#2020/4/5 ,是开博的第一天,希望和大家相互交流学习,很开森,哈哈~ #像个傻子哟~ #好,我们进入正题, #实现功能:利用python实现数据随机漫步,漫步点数据可视化 #什么是 ...
- 数据透视:Excel数据透视和Python数据透视
作者 | leo 早于90年代初,数据透视的概念就被提出,主要的应用场景是处理大量数据的交互式汇总查询,它实现了行或列的移动,使得行可以移到列上,列移到行上,从而根据使用者的诉求取对关注的数据子集进行 ...
- 数据可视化(8)--D3数据的更新及动画
最近项目组加班比较严重,D3的博客就一拖再拖,今天终于不用加班了,赶紧抽点时间写完~~ 今天就将D3数据的更新及动画写一写~~ 接着之前的博客写~~ 之前写了一个散点图的例子,下面可以自己写一个柱状图 ...
- <数据可视化>样例+数据+画图
1 样例 1.1样例1 子图系列 from pylab import * def f(x): return np.exp(-x) * np.cos(2*np.pi*x) x1 = np.arange( ...
- Python数据可视化的四种简易方法
摘要: 本文讲述了热图.二维密度图.蜘蛛图.树形图这四种Python数据可视化方法. 数据可视化是任何数据科学或机器学习项目的一个重要组成部分.人们常常会从探索数据分析(EDA)开始,来深入了解数据, ...
- 从python爬虫以及数据可视化的角度来为大家呈现“227事件”后,肖战粉丝的数据图
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取t.cn ...
- python grib气象数据可视化
基于Python的Grib数据可视化 利用Python语言实现Grib数据可视化主要依靠三个库——pygrib.numpy和matplotlib.pygrib是欧洲中期天气预报中心 ...
随机推荐
- PHP针对数字的加密解密类,可直接使用
<?phpnamespace app;/** * 加密解密类 * 该算法仅支持加密数字.比较适用于数据库中id字段的加密解密,以及根据数字显示url的加密. * @author 深秋的竹子 * ...
- tcpdump详解
tcpdump -i eth1 'host 121.14.84.221 and greater 76' -Ap -v -s10000 抓取 eth1 和 121.14.84.221 上的所有长度大于7 ...
- 8)django-示例(url传递参数)
url传递参数有两种,一个是通过普通分组方式,一个是通过带命名分组方式 1.传递方式 1)普通分组方式,传递参数顺序是严格的.如下例子 url(r'^detail-(\d+)-(\d+).html', ...
- PKUWC2019垫底记
凭着noip2018中超凡的运气,我来到了纪中. DAY0 听说PKUWC可以看榜?那就不用担心写挂啦!开心! 刚从雅礼回来休息了一天,下午就和hz一起坐上教练的车去到了中山纪中. 纪中好大好漂亮啊! ...
- hive学习01词频统计
词频统计 #创建表,只有一列,列名line create table word_count ( line string) row format delimited fields terminated ...
- js学习——基础知识
数据类型 函数.方法 变量作用域 运算符 条件语句 break和continue typeof 错误(异常) 变量提升 严格模式 JSON void(0) JavaScript ...
- SpringBoot集成前端模版(thymeleaf)
1.在application.properties配置文件中添加 thymeleaf 的配置信息 spring.datasource.driverClassName=com.mysql.jdbc.Dr ...
- uva11426 欧拉函数应用,kuangbin的筛法模板
/* 给定n,对于所有的对(i,j),i<j,求出sum{gcd(i,j)} 有递推式sum[n]=sum[n-1]+f[n] 其中f[n]=gcd(1,n)+gcd(2,n)+gcd(3,n) ...
- CF 1051F
题意:给定一张n个点,m条边的无向联通图,其中m-n<=20,共q次询问,每次询问求给定两点u,v间的最短路长度 第一眼看见这题的时候,以为有什么神奇的全图最短路算法,满心欢喜的去翻了题解,发现 ...
- eclipse的安装及使用
1.安装 2工作区 3透视图添加透视图 关闭和显示各个子视图 点击视图右上角的关闭按钮可以关闭当前视图 可以选择Window-->Show View菜单项打开各个子视图 4创建项目 选择File ...