Elasticsearch 聚合统计与SQL聚合统计语法对比(一)
Es相比关系型数据库在数据检索方面有着极大的优势,在处理亿级数据时,可谓是毫秒级响应,我们在使用Es时不仅仅进行简单的查询,有时候会做一些数据统计与分析,如果你以前是使用的关系型数据库,那么Es的数据统计跟关系型数据库还是有很大的区别的,所以,这篇内容,为了更好的理解,我简单对比了Es中统计的写法与关系型数据库的写法。
首先,先了解一下Es中关于聚合的概念:
1:桶(Buckets)满足特定条件的文档的集合;
2:指标(Metrics)对桶内的文档进行统计计算
这两个概念是什么意思?先看下面一段T-SQL统计代码:
SELECT Color,SUM(1) as Nums【2】
FROM #Cars
GROUP BY Color 【1】
桶:满足特定条件的集合,这个很好理解,比如可以把蓝色的放到蓝色的桶里,绿色的放到绿色的桶里,桶是用来存放不同类型的集合。SQL代码中【1】就可以理解对桶进行分组,有多少种颜色,就会有几种不同的桶。桶类似于SQL中GROUP BY;
指标:对桶内的数据进行统计计算。SQL代码中【2】就可以理解为指标,每个桶里有多少条记录。指标类似于SQL中各种汇总,如Count(),Sum(),Max(),Min();
概念了解之后,对比来了, 我们来做一组数据:
1. 创建表结构并填充数据
1.1创建SQLSERVER结构与数据
CREATE TABLE #Cars
(
ID int IDENTITY(1,1) NOT NULL, --创建自增序列
Price int, --价格
Color varchar(50), --颜色
Make varchar(50), --品牌
Sold datetime, --销售日期
Primary key(ID) --定义ID为临时表#Cars的主键
);
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (10000,'红色','汉兰达','2014-10-28');
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (20000,'红色','汉兰达','2014-11-05');
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (30000,'绿色','福特','2014-05-18');
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (15000,'蓝色','丰田','2014-11-05');
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (12000,'绿色','丰田','2014-07-02');
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (20000,'红色','汉兰达','2014-11-05');
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (80000,'红色','宝马','2014-01-01');
INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (25000,'蓝色','福特','2014-02-12');
1.2创建Elastsearch 结构与数据
POST /testindex/cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "红色", "make" : "汉兰达", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "红色", "make" : "汉兰达", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "绿色", "make" : "福特", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "蓝色", "make" : "丰田", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "绿色", "make" : "丰田", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "红色", "make" : "汉兰达", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "红色", "make" : "宝马", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "蓝色", "make" : "福特", "sold" : "2014-02-12" }
2. 统计查询对比
上面的代码中,分别创建了Es与SQLSERVER的数据结构,并且填充了一些数据。接下来,我们来举几个统计的例子,来看看他们两个之间的统计代码分别怎么写。
2.1 统计哪个颜色的销量最好?
【SQLSERVER实现】
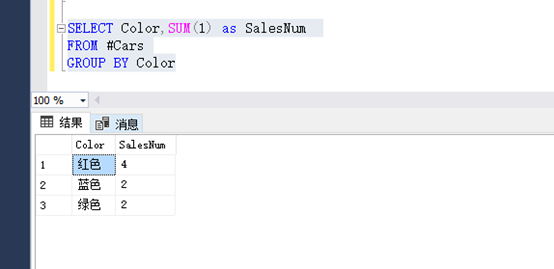
SELECT Color,SUM(1) as SalesNum
FROM #Cars
GROUP BY Color
结果如下图:
【Elasticsearch 实现】
GET testindex/cars/_search
{
"size": 0, 【3】
"aggs": {【1】
"SalesNum": { 【2】
"terms": {【4】
"field": "color.keyword",
"size": 10
}
}
}
}
结果如下图:
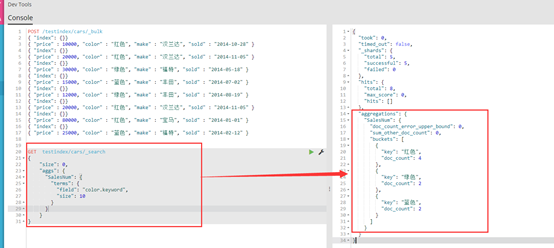
【1】:如果想要进行统计分析,统计代码需要写在aggs中,aggs是aggregations 的简称,也可以写作 aggregations。
【2】:是指定的列的名称,作用同SQLSERVER统计中as 重命名。
【3】:这里设置了返回值为0,因为这个查询不仅仅返回了我们的统计的内容,还返回了搜索结果的内容,这里我们并不需要搜索结果的内容,所以设置为0.
【4】:这里定义了桶的类型,如果需要不同的统计内容,这些需要使用不同的统计类型。
2.2 按颜色统计出平均价格?
【SQLSERVER实现】
SELECT Color,AVG(Price) as '平均价格'
FROM #Cars
GROUP BY Color
【Elasticsearch 实现】
GET testindex/cars/_search
{
"size": 0,
"aggs": {
"s": {
"terms": {
"field": "color.keyword",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
2.3 按照颜色统计出平均价格、最高价格、最低价格?
【SQLSERVER实现】
SELECT Color,AVG(Price) as '平均价格',MIN(Price) as MinPrice,MAX(Price) as MaxPrice
FROM #Cars
GROUP BY Color
【Elasticsearch 实现】
参考:https://elasticsearch.cn/question/4799
2.4 统计每一个企业品牌的最低价格和最高价格?
【SQLSERVER实现】
SELECT Make,MIN(Price) as MinPrice,MAX(Price) as MaxPrice
FROM #Cars
GROUP BY Make
【Elasticsearch 实现】
GET testindex/cars/_search
{
"size": 0
,"aggs": {
"make": {
"terms": {
"field": "make.keyword"
}
,"aggs": {
"price_age": {
"avg": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
}
,"max_price":{
"max": {
"field": "price"
}
}
}
}
}
}
通过上面的几个示例,我简单总结了几个SQLSever 中汇总函数与Es 的对比,看下面的表格:
|
SQLSERVER函数 |
Agg_Type |
功能说明 |
|
GROUP BY 字段名称 |
Terms (避免使用分词字段用来分组) |
分组、Es划分桶 |
|
Max()函数 |
Max |
求最大值 |
|
Min()函数 |
Min |
求最小值 |
|
Avg()函数 |
Avg |
求平均值 |
今天就先对比下简单的聚合汇总、求平均值统计,明天再对比下其他的,比如日期的聚合以及聚合的排序等。
Elasticsearch 聚合统计与SQL聚合统计语法对比(一)的更多相关文章
- lucene中facet实现统计分析的思路——本质上和word count计数无异,像splunk这种层层聚合(先filed1统计,再field2统计,最后field3统计)lucene是排序实现
http://stackoverflow.com/questions/185697/the-most-efficient-way-to-find-top-k-frequent-words-in-a-b ...
- sql 聚合函数、排序方法详解
聚合函数 count,max,min,avg,sum... select count (*) from T_Employee select Max(FSalary) from T_Employee 排 ...
- ElasticSearch 2 (35) - 信息聚合系列之近似聚合
ElasticSearch 2 (35) - 信息聚合系列之近似聚合 摘要 如果所有的数据都在一台机器上,那么生活会容易许多,CS201 课商教的经典算法就足够应付这些问题.但如果所有的数据都在一台机 ...
- sql 聚合查询
如果我们要统计一张表的数据量,例如,想查询students表一共有多少条记录,难道必须用SELECT * FROM students查出来然后再数一数有多少行吗? 这个方法当然可以,但是比较弱智.对于 ...
- Elasticsearch聚合 之 Range区间聚合
Elasticsearch提供了多种聚合方式,能帮助用户快速的进行信息统计与分类,本篇主要讲解下如何使用Range区间聚合. 最简单的例子,想要统计一个班级考试60分以下.60到80分.80到100分 ...
- SQL语句统计每天、每月、每年的 数据
SQL语句统计每天.每月.每年的数据 1.每年select year(ordertime) 年,sum(Total) 销售合计from 订单表group by year(ordertime) 2.每月 ...
- SQL Server数据库--》top关键字,order by排序,distinct去除重复记录,sql聚合函数,模糊查询,通配符,空值处理。。。。
top关键字:写在select后面 字段的前面 比如你要显示查询的前5条记录,如下所示: select top 5 * from Student 一般情况下,top是和order by连用的 orde ...
- 全废话SQL Server统计信息(2)——统计信息基础
接上文:http://blog.csdn.net/dba_huangzj/article/details/52835958 我想在大地上画满窗子,让所有习惯黑暗的眼睛都习惯光明--顾城<我是一个 ...
- 【转】SQL语句统计每天、每月、每年的数据
原文:https://www.cnblogs.com/Fooo/p/3435687.html SQL语句统计每天.每月.每年的数据 1.每年select year(ordertime) 年,sum(T ...
随机推荐
- mysql自增id超大问题查询
引言 小A正在balabala写代码呢,DBA小B突然发来了一条消息,"快看看你的用户特定信息表T,里面的主键,也就是自增id,都到16亿了,这才多久,在这样下去过不了多久主键就要超出范围了 ...
- 从 0 到 1 实现 React 系列 —— 2.组件和 state|props
看源码一个痛处是会陷进理不顺主干的困局中,本系列文章在实现一个 (x)react 的同时理顺 React 框架的主干内容(JSX/虚拟DOM/组件/生命周期/diff算法/setState/ref/. ...
- 实时采集新加坡交易所A50指数
http://www.investing.com/indices/ftse-china-a50 前段时间有人问我如何得到这个网页的实时指数变化,经过抓包发现该网站提供的指数实时变化是通过Websock ...
- Linux模拟控制网络时延
之前以为可以使用Linux自带的工具模拟控制网络时延,所以上网找了一些资料.后来发现,找到的资料目前只支持在一个网卡上模拟发送报文的时延,而不能设置有差别的网络时延,或者说当要模拟的向A发送的时延与要 ...
- org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): com.bw.mapper.BillMapper.getBillList at org.apache.ibatis.binding.MapperMethod$SqlCommand.<init>(MapperMethod.java:225
这个错误是没有找到映射文件 org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): com.b ...
- nginx学习笔记二
一,nginx架构在Linux系统中以daemon(守护进程)的方式在后台运行,后台进程包含一个master进程和多个worker进程(多进程的工作方式) master进程 | 信号 | | ---- ...
- linux之常见错误
在日常开发中,尤其是在Linux中进行操作的时候,经常会碰到各种各样的错误.记录一下,熟能生巧,慢慢参透linux的奥秘 1) 在安装ssl证书的时候,发生certbot命令无法使用的情况 解决方案: ...
- js-canvas(基本用法)
###1. canvas(画布) <canvas>是HTML 5 新增的元素,可用于通过使用JavaScript中的脚本来绘制图形 默认宽高为300px*150px 基本概念和方法入门推荐 ...
- 【转帖】Linux定时任务Crontab命令详解
Linux定时任务Crontab命令详解 https://www.cnblogs.com/intval/p/5763929.html 知道有crontab 以及 at 命令 改天仔细学习一下 讲sys ...
- synchronized无法禁止指令重排序的证明
package demo.reorder; import java.util.concurrent.ExecutorService; import java.util.concurrent.Execu ...