SparkSQL – 从0到1认识Catalyst(转载)
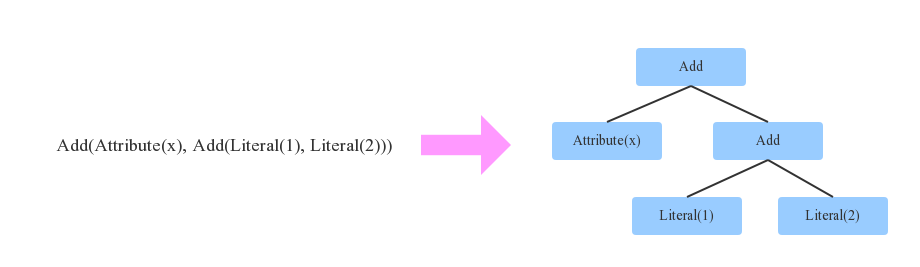
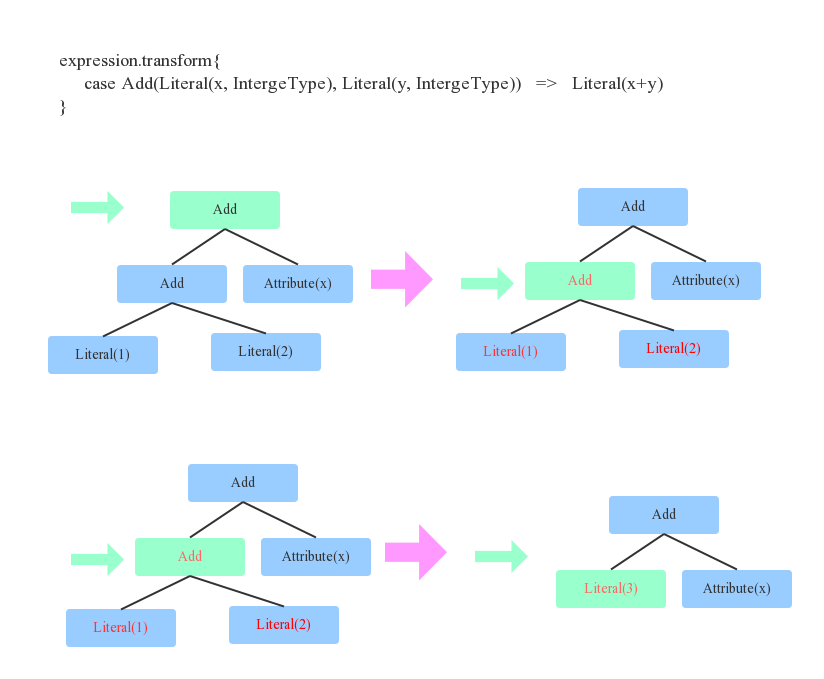
预备知识-Tree&Rule
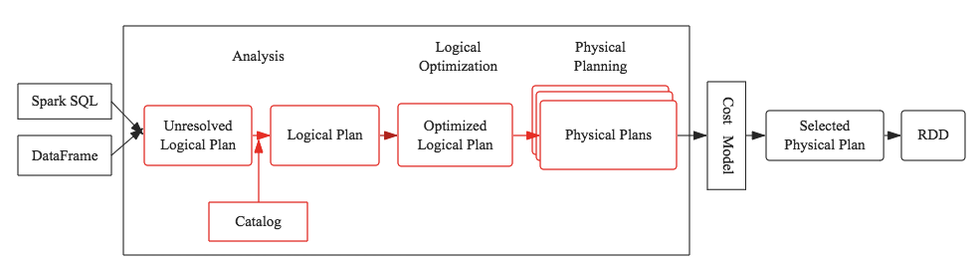
Catalyst工作流程
Parser
Analyzer
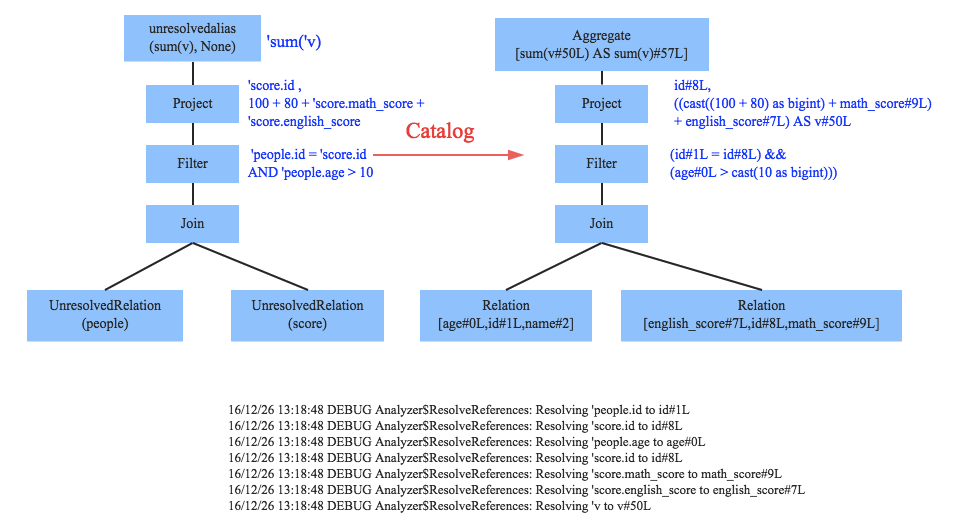
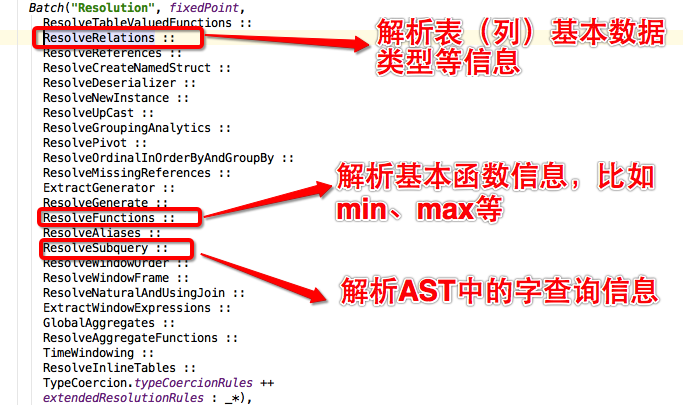
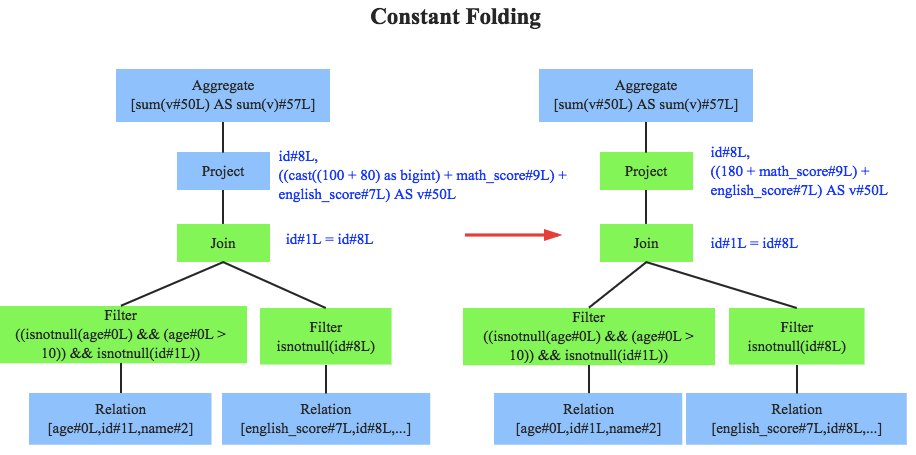
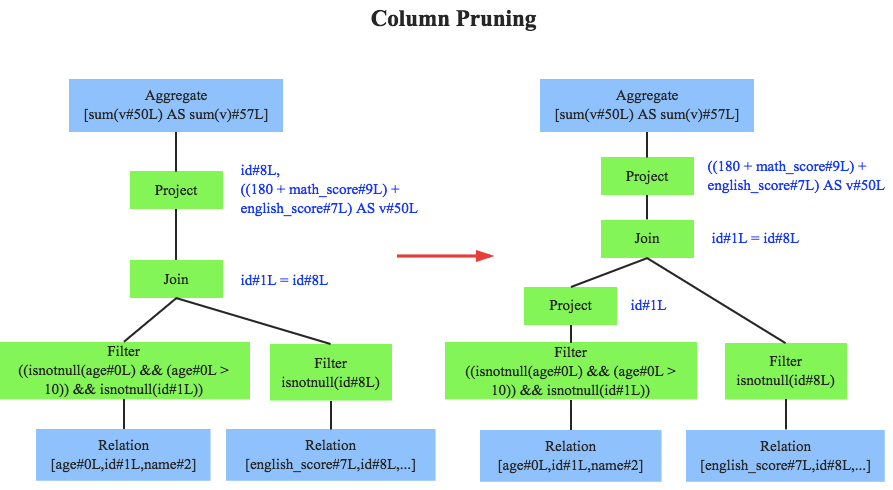
Optimizer


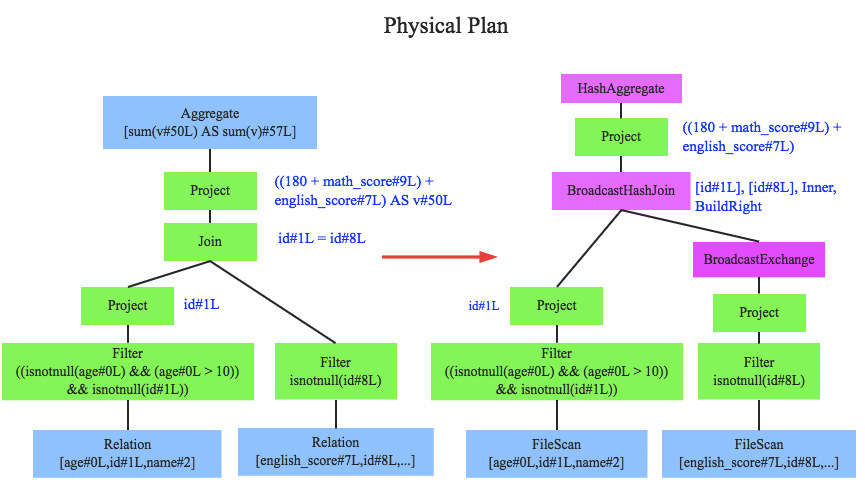
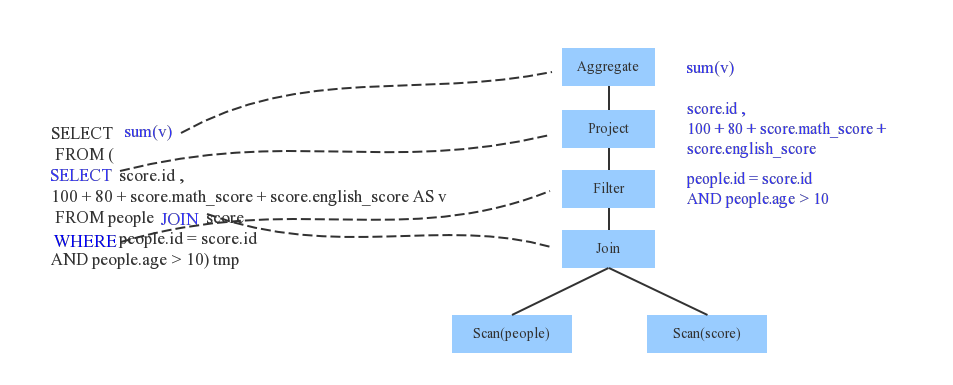
SparkSQL执行计划
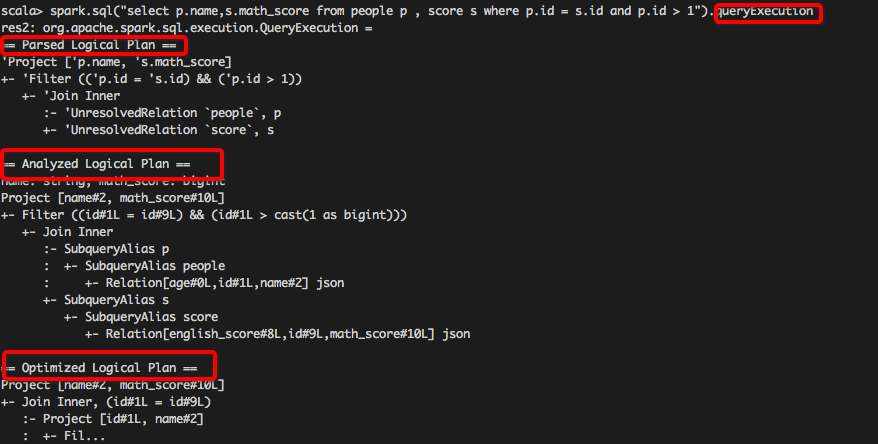
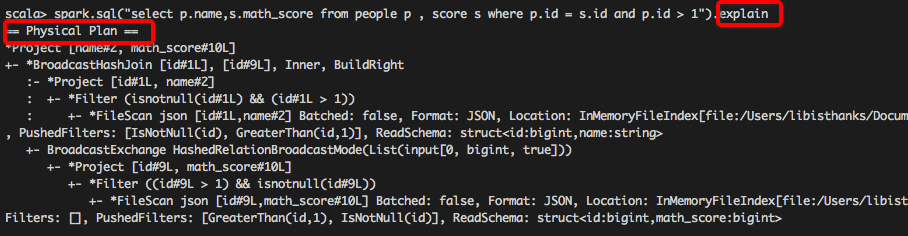
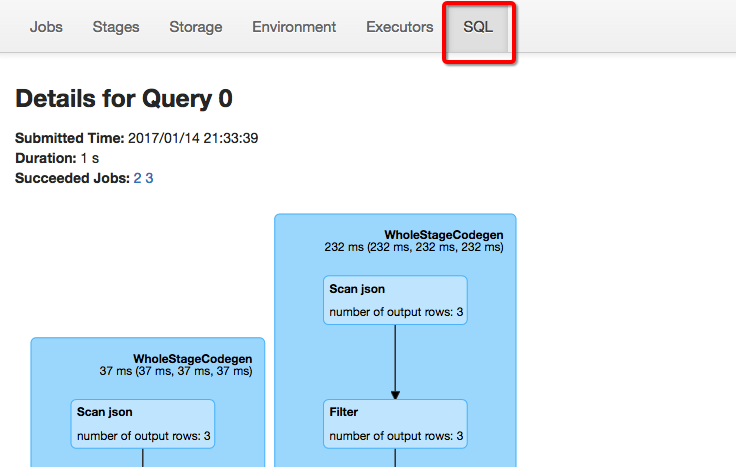
SparkSQL – 从0到1认识Catalyst(转载)的更多相关文章
- Socket的用法——NIO包下SocketChannel的用法 ———————————————— 版权声明:本文为CSDN博主「茶_小哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/ycgslh/article/details/79604074
服务端代码实现如下,其中包括一个静态内部类Handler来作为处理器,处理不同的操作.注意在遍历选择键集合时,没处理完一个操作,要将该请求在集合中移除./*模拟服务端-nio-Socket实现*/pu ...
- Apache Spark 2.2.0新特性介绍(转载)
这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(experimental tag)已经被移除.在流系统中支持对任意状态进行操作:A ...
- mongodb 3.0 WT 引擎性能测试(转载)
网上转载来的测试,仅供参考.原文地址:http://www.mongoing.com/benchmark_3_0 类机器. 测试均在单机器,单实例的情况下进行. 机器A(cache 12G,即内存&g ...
- Cocos2d-x 3.0坐标系详解(转载)
Cocos2d-x 3.0坐标系详解 Cocos2d-x坐标系和OpenGL坐标系相同,都是起源于笛卡尔坐标系. 笛卡尔坐标系 笛卡尔坐标系中定义右手系原点在左下角,x向右,y向上,z向外,OpenG ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载-2)
原文:http://www.cnblogs.com/PurpleDream/p/4510279.html 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群 前言: ...
- do{...}while(0)的意义和用法(转载)
linux内核和其他一些开源的代码中,经常会遇到这样的代码: do{ ... }while(0) 这样的代码一看就不是一个循环,do..while表面上在这里一点意义都没有,那么为什么要这么用呢? 实 ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载)
原文:http://www.open-open.com/lib/view/open1435468300700.html 第一步,确定目标: Tracker 192.168.224.20:22122 ...
- ip地址0.0.0.0与127.0.0.1的区别(转载)
原文链接:http://blog.csdn.net/ttx_laughing/article/details/58586907 最近在项目开发中发现一个奇怪的问题,当服务器与客户端在同一台机器上时,用 ...
- 在Android 5.0中使用JobScheduler(转载)
翻译见:http://blog.csdn.net/bboyfeiyu/article/details/44809395 In this tutorial, you will learn how to ...
随机推荐
- 商家中心FAQ
1.订购的账号为什么不生成子账号,生成了一个主账号,进店铺里面看子账号也没有 原因:授权失败了,数据库没有生成店铺授权信息 解决方案:重新授权
- sql 语句-初级进阶(一)
以下所有的sql语句是根据个人资料进行操作,为方便大家操作联系,附上链接:: 链接:https://pan.baidu.com/s/14LmWyhJPQRzpjURQBKM4mA 提取码:wu1q ...
- c/c++ 用前序和中序,或者中序和后序,创建二叉树
c/c++ 用前序和中序,或者中序和后序,创建二叉树 用前序和中序创建二叉树 //用没有结束标记的char*, clr为前序,lcr为中序来创建树 //前序的第一个字符一定是root节点,然后去中序字 ...
- HTTP与TCP的区别和联系
工作原理(转载): https://www.cnblogs.com/zimohul/p/6506406.html 相信不少初学手机联网开发的朋友都想知道Http与Socket连接究竟有什么区别,希望通 ...
- KVM使用
这里使用的是Ubuntu18.04桌面版虚拟机 关于KVM可以看一下我之前的博客,有一些简单的介绍. 1.在打开虚拟机之前先开启此虚拟机的虚拟化功能. 2.安装KVM及其依赖项 wy@wy-virtu ...
- C3P0连接池温习1
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- 【工具大道】UML的点点滴滴
本文地址 点击关注微信公众号 wenyuqinghuai 分享提纲: 1. 概述 2. UML类图 3. UML时序图 4. 参考资料 1.概述 1.1)百度百科: 又称统 ...
- TOPWAY智能彩色TFT液晶显示模块
TOPWAY 20年来专注工业显示, 以为全球工业用户提供稳定可靠和容易使用的液晶显示模块为己任, 智能彩色TFT液晶显示模块(以下简称智能模块), 就是我们在容易使用TFT 彩色液晶显示方向上为广大 ...
- 阿里云CentOS下nodejs安装
1. 下载node包(包含npm) cd /usr/local/src/ wget https://nodejs.org/dist/v10.11.0/node-v10.11.0-linux-x64.t ...
- WPF调用zxing生成二维码
1.登录http://zxingnet.codeplex.com/,下载对应.net版本的zxing库 2.引入zxing.dll 3.新建界面控件 using System; using Syste ...