Hadoop环境准备
1. 集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
那mapreduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
Hadoop部署方式分三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster mode(群集模式),其中前两种都是在单机部署。
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
我们以3节点为例进行搭建,角色分配如下:
node-01 NameNode DataNode ResourceManager
node-02 DataNode NodeManager SecondaryNameNode
node-03 DataNode NodeManager
2. 服务器准备
本案例使用VMware Workstation Pro虚拟机创建虚拟服务器来搭建HADOOP集群,所用软件及版本如下:
VMware Workstation Pro 15.0
Centos 7.5 64bit
3. 网络环境准备
采用NAT方式联网。
如果创建的是桌面版的Centos系统,可以在安装完毕后通过图形页面进行编辑。如果是mini版本的,可通过编辑ifcfg-eth*配置文件进行配置。
注意BOOTPROTO、GATEWAY、NETMASK。
4. 服务器系统设置
同步时间
#手动同步集群各机器时间
date -s "2017-03-03 03:03:03"
yum install ntpdate
#网络同步时间
ntpdate cn.pool.ntp.org
设置主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node-1
配置IP、主机名映射
vi /etc/hosts
192.168.33.151 node-1
192.168.33.152 node-2
192.168.33.153 node-3
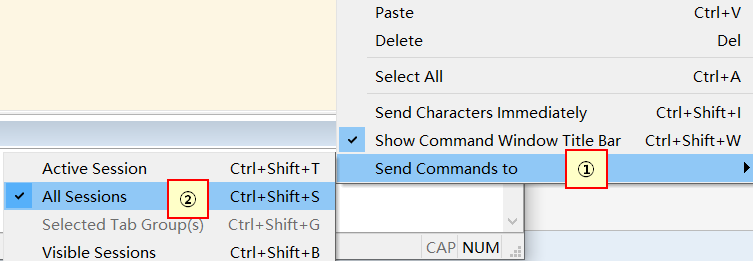
小技巧:使用SecureCRT同时操作3台虚拟机
勾选Command Window

在控制台右键→Send Commands to→All Sessions
配置ssh免密登陆
#生成ssh免登陆密钥(一般配置从主节点到从节点的免密登录)
ssh-keygen -t rsa (四个回车)
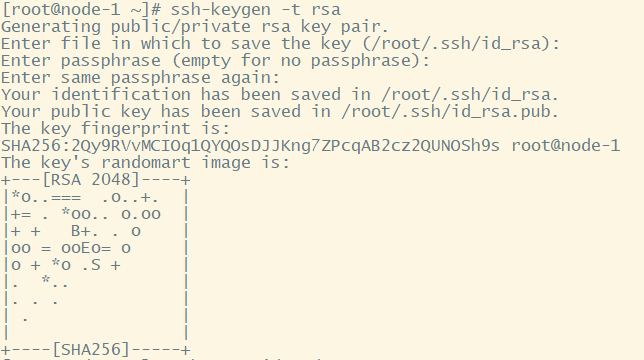
执行完这个命令后,会生成id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id node-2 ssh-copy-id node-3
注意:
在给其他主机配置免密登录时,一定要给本主机配置免密登录
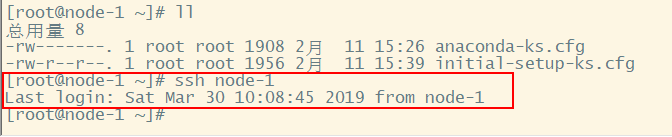
在未配置免密登录时,如下图所示:(系统会提示你输入密码,即root账户密码)

接下来对node-1配置免密登录,先生成ssh免登陆密钥(参考上文),接下来如下操作:

配置后再次登录,配置成功后如下图所示:
同理,在主机node-1中配置node-2、node-3的免密登录
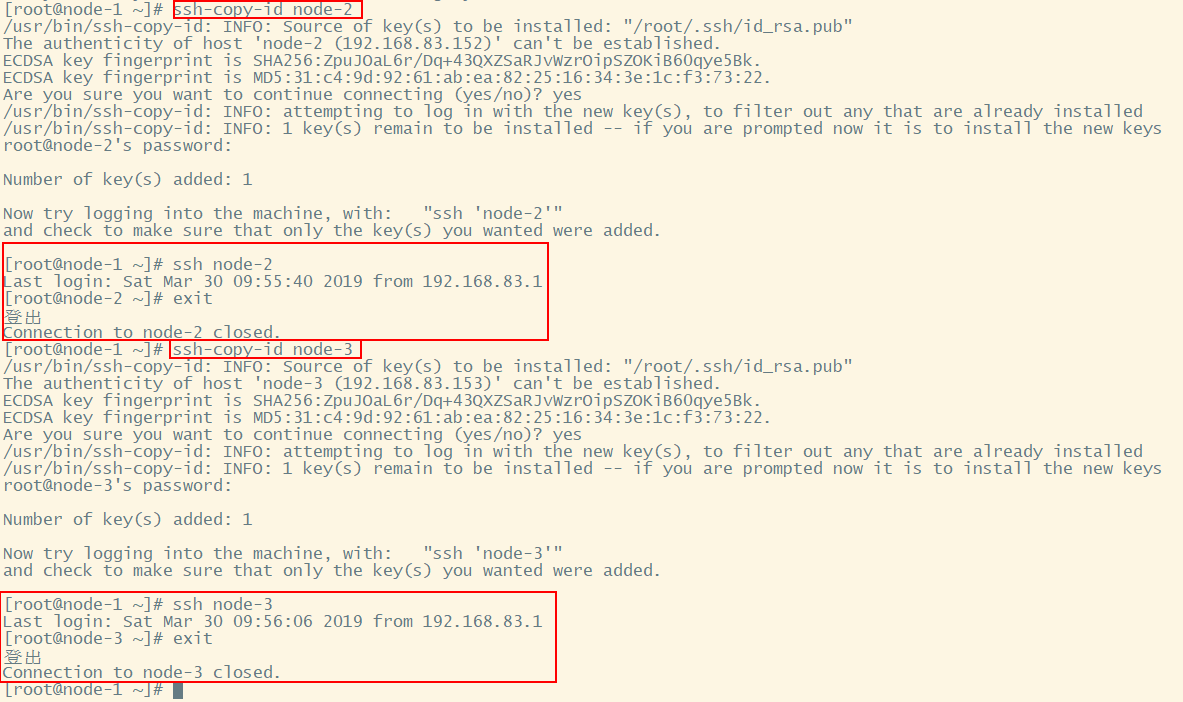
以上操作就完成了node-1到自己(本身)、node-1到node-2、node-1到node-3的免密登录。
那么有的同学可能会问node-2到node-3或者node-3到node-1需要配置吗?
答案是不需要在进行这样的配置。我们后续的操作主要在node-1这台主机上进行,可见node-1这台主机的地位还是比较高的。
配置防火墙
可以选择关闭防火墙
5. JDK环境安装
可以参考我之前的jdk安装教程
至此,前期工作准备完成,接下来就是hadoop的安装了。
Hadoop环境准备的更多相关文章
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- 【Hadoop测试程序】编写MapReduce测试Hadoop环境
我们使用之前搭建好的Hadoop环境,可参见: <[Hadoop环境搭建]Centos6.8搭建hadoop伪分布模式>http://www.cnblogs.com/ssslinppp/p ...
- 【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式
阅读目录 ~/.ssh/authorized_keys 把公钥加到用于认证的公钥文件中,authorized_keys是用于认证的公钥文件 方式2: (未测试,应该可用) 基于空口令创建新的SSH密钥 ...
- hadoop环境安装及简单Map-Reduce示例
说明:这篇博客来自我的csdn博客,http://blog.csdn.net/lxxgreat/article/details/7753511 一.参考书:<hadoop权威指南--第二版(中文 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- 虚拟机搭建hadoop环境
这里简单用三台虚拟机,搭建了一个两个数据节点的hadoop机群,仅供新人学习.零零碎碎,花了大概一天时间,总算完成了. 环境 Linux版本:CentOS 6.5 VMware虚拟机 jdk1.6.0 ...
- 大数据学习系列之一 ----- Hadoop环境搭建(单机)
一.环境选择 1,服务器选择 阿里云服务器:入门型(按量付费) 操作系统:linux CentOS 6.8 Cpu:1核 内存:1G 硬盘:40G ip:39.108.77.250 2,配置选择 JD ...
- hadoop环境配置过程中可能遇到问题的解决方案
Failed to set setXIncludeAware(true) for parser 遇到此问题一般是jar包冲突的问题.一种情况是我们向java的lib目录添加我们自己的jar包导致had ...
- 在本机eclipse中创建maven项目,查看linux中hadoop下的文件、在本机搭建hadoop环境
注意 第一次建立maven项目时需要在联网情况下,因为他会自动下载一些东西,不然突然终止 需要手动删除断网前建立的文件 在eclipse里新建maven项目步骤 直接新建maven项目出了错 ...
- Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)
系统:Centos 7,内核版本3.10 本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件. 一.宿主机准备工作 0.宿主机(Centos7 ...
随机推荐
- apache thrift分析
thrift是一个用来实现跨语言的远程调用(RPC Remote Procedure Call)的软件框架.根据接口定义语言(IDL Interface definition lanuage) 并借助 ...
- aspcms逻辑错误导致后台地址泄露
访问即可跳转后台地址: URL:http://www.xxx.org.cn/plug/oem/AspCms_OEMFun.asp 注入:plug/comment/commentList.asp?id= ...
- CodeForces160D 最小生成树 + dfs
https://cn.vjudge.net/problem/26727/origin 题目大意: 给一个带权的无向图,保证没有自环和重边. 由于最小生成树不唯一,因此你需要确定每一条边是以下三种情况哪 ...
- 16、计算1加到100用两个定义值count=1、sum=0
#!/user/bin/python# -*- coding:utf-8 -*-count = 1sum = 0while count <= 100: sum = sum + count cou ...
- i2c框架
目录 i2c框架 寄存器 主机发送 主机接收 中断处理 程序框架 title: iic框架 tags: ARM date: 2018-11-05 13:44:58 --- i2c框架 寄存器 /* 配 ...
- docker 基础之数据管理
数据卷 一.将本地默认目录挂载到docker容器内指定的目录 #将本地的目录挂在到docker容器内 docker run -it --name container-test -h CONTAINER ...
- hdfs.DataStreamer: Exception in createBlockOutputStream
在上传文件至 HDFS 提示如下信息 [root@h136 jdk1.8.0_202]# hadoop fs -put javafx-src.zip / 19/04/11 23:19:36 INFO ...
- 使用git 上传项目到gitee/github
参考: https://blog.csdn.net/qq944639839/article/details/79864081 注意:在此之前需要设置ssh公匙 详见:Github/github 初始化 ...
- Part-Four
1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12.
- python 单例模式总结
参考 # 第一种方法 new 方法 class Singleton(object): def __new__(cls,*args,**kw): if not hasattr(cls,'_instanc ...