Highgo 瀚高数据库的简单搭建以及处理参数等.
1. 获取一个瀚高数据库的安装文件
我这边只获取了 瀚高的 2.0.4 的windows x64 版本的.
来源: 同事从供应商那里获取的.
2. windows上面简单安装
很简单 exe 一路next 即可 注意设置密码.
3. 设置参数文件
这一个与postgresql 一模一样..
具体文件位置
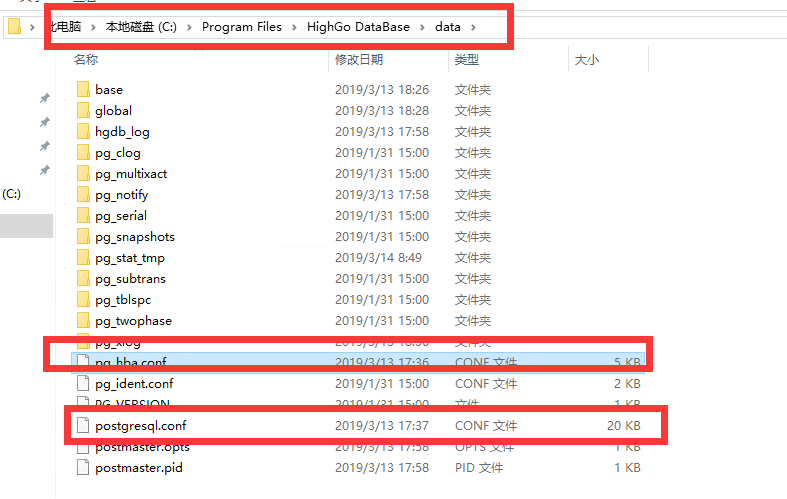
类似修改
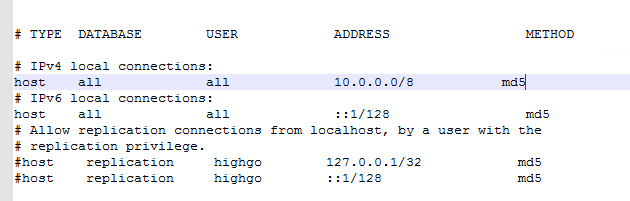
注意端口选项:
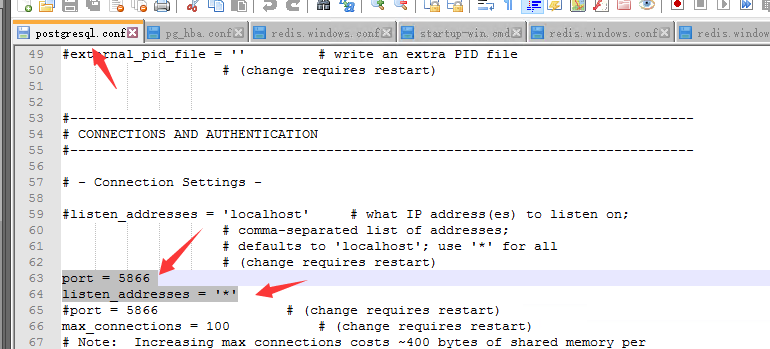
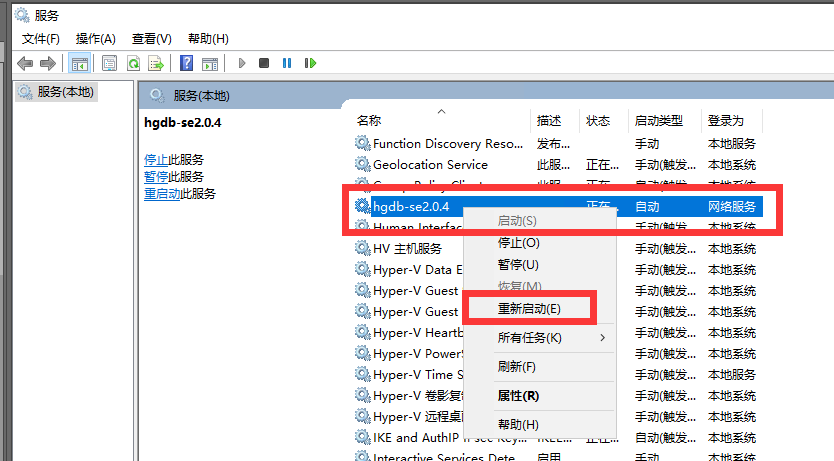
4. 注意修改完参数 需要重启一下服务 有时候他的控制台不好用 可以在service 里面执行重启
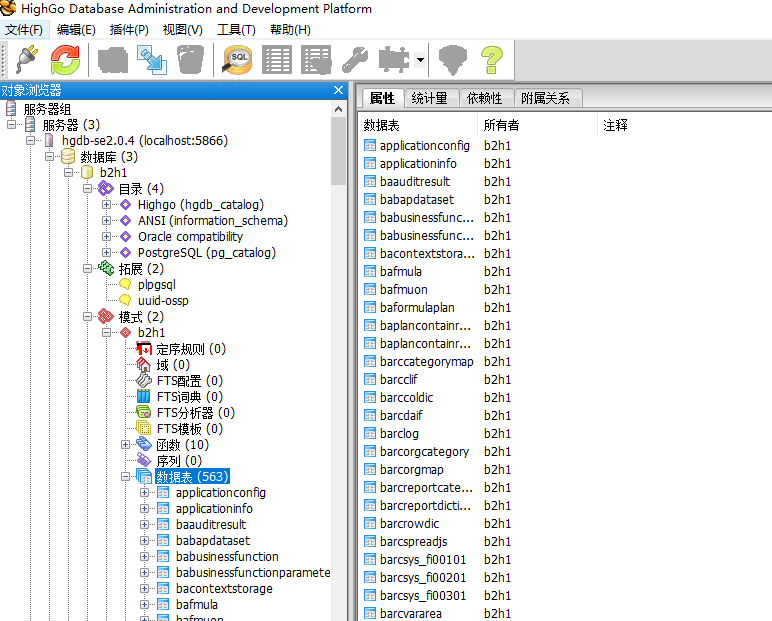
5. 可以简单看一下 highgo的控制台:
Highgo 瀚高数据库的简单搭建以及处理参数等.的更多相关文章
- HighGo瀚高数据库4.3版本安装说明
1. 通过与瀚高同事沟通, 获取到安装文件(点赞一下瀚高的同事, 效率很高并且说明的很完整) 瀚高是基于postgresql数据库做的深度定制开发的国产数据库. 不仅仅支持x86 也支持龙芯等全国产安 ...
- 龙芯PG10 安装uuid-ossp 的方法 复用瀚高数据库的 so文件
接着上一篇blog 当时在中标麒麟 龙芯上面安装了postgresql10.10 的版本 但是没搞定 uuid 当时遇到的问题: 0. 只安装postgresql数据库会报错如图示: 我验证了下 安 ...
- ARM 版本 瀚高 数据库的启动命令
1. 在瀚高安装目录下面执行路径 安装目录为: /opt/HighGoDB-4.3.4.3/ bin下./pg_ctl restart -D ../data 本次的密码是: highgo123 2 ...
- [转帖]瀚高数据库创建uuid的方法
使用syssso登录,并执行下列语句 highgo=> select set_secure_level('off'); set_secure_level -------------------- ...
- solr 简单搭建 数据库数据同步(待续)
原来在别的公司负责过文档检索模块的维护(意思就是不是俺开发的啦). 所以就略微接触和研究了下文档检索. 文档检索事实上是全文检索.是通过一种技术把N多文档进行一定规律的分割归类,然后创建易于搜索的索引 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- 【转载】Redis Sentinel 高可用服务架构搭建
作者:田园里的蟋蟀 出处:http://www.cnblogs.com/xishuai/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接. 阅读 ...
- MHA 高可用集群搭建(二)
MHA 高可用集群搭建安装scp远程控制http://www.cnblogs.com/kevingrace/p/5662839.html yum install openssh-clients mys ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
随机推荐
- python入门练习题
1.使用while循环输入 1 2 3 4 5 6 8 9 10 num = 1 while num<=10: if num ==7: num += 1 continue print(n ...
- 12个 Linux 中 grep 命令的超级用法实例
12个 Linux 中 grep 命令的超级用法实例 你是否遇到过需要在文件中查找一个特定的字符串或者样式,但是不知道从哪儿开始?那么,就请grep来帮你吧. grep是每个Linux发行版都预装的一 ...
- Python:Day15 函数
函数参数补充: 还可以这样传参: def f(*args): print(args) f(*[1,3,4,5]) #输出结果:(1, 3, 4, 5) 注意这是一个元组 def f2(**kwargs ...
- 【html】使ifram搭建的项目,新页面跳出框架
方法一: <a href="<?php echo $baseUrl . '#/study/order';?>" target="_parent" ...
- matlab 整局-部视知觉实验(读取excel点阵设计图替换数据)
-------给我那编程盲的女盆友,我怎么感觉是我选了一门课???做了这么多次作业,还是整理出来吧,要知道双鸭山大学心理系单身妹子还是很多啊. 整体-局部范式是心理学的经典实验之一.请尝试利用 MAT ...
- classmethod 和 staticmethod
我一般很少用到. Talk is cheap, show you the code. #!/usr/bin/env python # -*- coding: utf-8 -*- ########### ...
- AI Haar特征
Haar特征,也叫矩形特征,有四种特征(模板):边缘特征.线性特征.中心特征.对角线特征.每种模板都包含黑白两种区域. 模板的特征值=白色区域的像素和-黑色区域的像素和,反映的是图像的灰度变化情况. ...
- 简述DDOS攻击的工作原理
1.DDOS攻击:大量的肉鸡对服务器的不同端口发送巨型流量的UDP报文,无法通关关闭端口的方式来进行隔离,破坏力极强,严重会造成服务器当机. SYN/ACK Flood攻击:经典最有效的DDOS方法. ...
- 有关Web常用字体的研究?
Windows自带字体: 黑体:SimHei 宋体:SimSun 新宋体:NSimSun 仿宋:FangSong 楷体:KaiTi 仿宋GB2312:FangSongGB2312 楷体GB2312:K ...
- 史上最全面的Docker容器引擎使用教程
目录 1.Docker安装 1.1 检查 1.2 安装 1.3 镜像加速 1.4 卸载Docker 2.实战Nginx 3.Docker命令小结 4.DockerFile创建镜像 4.1 Docker ...