spak数据倾斜解决方案
数据倾斜解决方案
数据倾斜的解决,跟之前讲解的性能调优,有一点异曲同工之妙。
性能调优中最有效最直接最简单的方式就是加资源加并行度,并注意RDD架构(复用同一个RDD,加上cache缓存)。相对于前面,shuffle、jvm等是次要的。
6.1、原理以及现象分析
6.1.1、数据倾斜怎么出现的
在执行shuffle操作的时候,是按照key,来进行values的数据的输出、拉取和聚合的。
同一个key的values,一定是分配到一个reduce task进行处理的。
多个key对应的values,比如一共是90万。可能某个key对应了88万数据,被分配到一个task上去面去执行。
另外两个task,可能各分配到了1万数据,可能是数百个key,对应的1万条数据。
这样就会出现数据倾斜问题。
想象一下,出现数据倾斜以后的运行的情况。很糟糕!
其中两个task,各分配到了1万数据,可能同时在10分钟内都运行完了。另外一个task有88万条,88 * 10 = 880分钟 = 14.5个小时。
大家看,本来另外两个task很快就运行完毕了(10分钟),但是由于一个拖后腿的家伙,第三个task,要14.5个小时才能运行完,就导致整个spark作业,也得14.5个小时才能运行完。
数据倾斜,一旦出现,是不是性能杀手?!
6.1.2、发生数据倾斜以后的现象
Spark数据倾斜,有两种表现:
1、你的大部分的task,都执行的特别特别快,(你要用client模式,standalone client,yarn client,本地机器一执行spark-submit脚本,就会开始打印log),task175 finished,剩下几个task,执行的特别特别慢,前面的task,一般1s可以执行完5个,最后发现1000个task,998,999 task,要执行1个小时,2个小时才能执行完一个task。
出现以上loginfo,就表明出现数据倾斜了。
这样还算好的,因为虽然老牛拉破车一样非常慢,但是至少还能跑。
2、另一种情况是,运行的时候,其他task都执行完了,也没什么特别的问题,但是有的task,就是会突然间报了一个OOM,JVM Out Of Memory,内存溢出了,task failed,task lost,resubmitting task。反复执行几次都到了某个task就是跑不通,最后就挂掉。
某个task就直接OOM,那么基本上也是因为数据倾斜了,task分配的数量实在是太大了!所以内存放不下,然后你的task每处理一条数据,还要创建大量的对象,内存爆掉了。
这样也表明出现数据倾斜了。
这种就不太好了,因为你的程序如果不去解决数据倾斜的问题,压根儿就跑不出来。
作业都跑不完,还谈什么性能调优这些东西?!
6.1.3、定位数据倾斜出现的原因与出现问题的位置
根据log去定位
出现数据倾斜的原因,基本只可能是因为发生了shuffle操作,在shuffle的过程中,出现了数据倾斜的问题。因为某个或者某些key对应的数据,远远的高于其他的key。
1、你在自己的程序里面找找,哪些地方用了会产生shuffle的算子,groupByKey、countByKey、reduceByKey、join
2、看log
log一般会报是在你的哪一行代码,导致了OOM异常。或者看log,看看是执行到了第几个stage。spark代码,是怎么划分成一个一个的stage的。哪一个stage生成的task特别慢,就能够自己用肉眼去对你的spark代码进行stage的划分,就能够通过stage定位到你的代码,到底哪里发生了数据倾斜。
1、使用Hive ETL预处理数据
方案适用场景:
如果导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:
此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
方案实现原理:
这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
2、过滤少数导致倾斜的key
方案适用场景:
如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
方案实现思路:
如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
方案实现原理:
将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生数据倾斜。
3、提高shuffle操作的并行度
方案实现思路:
在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很多场景来说都有点过小。
方案实现原理:
增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个不同的key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。
4、双重聚合
方案适用场景:
对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
方案实现思路:
这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案实现原理:
将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。如果一个RDD中有一个key导致数据倾斜,同时还有其他的key,那么一般先对数据集进行抽样,然后找出倾斜的key,再使用filter对原始的RDD进行分离为两个RDD,一个是由倾斜的key组成的RDD1,一个是由其他的key组成的RDD2,那么对于RDD1可以使用加随机前缀进行多分区多task计算,对于另一个RDD2正常聚合计算,最后将结果再合并起来。
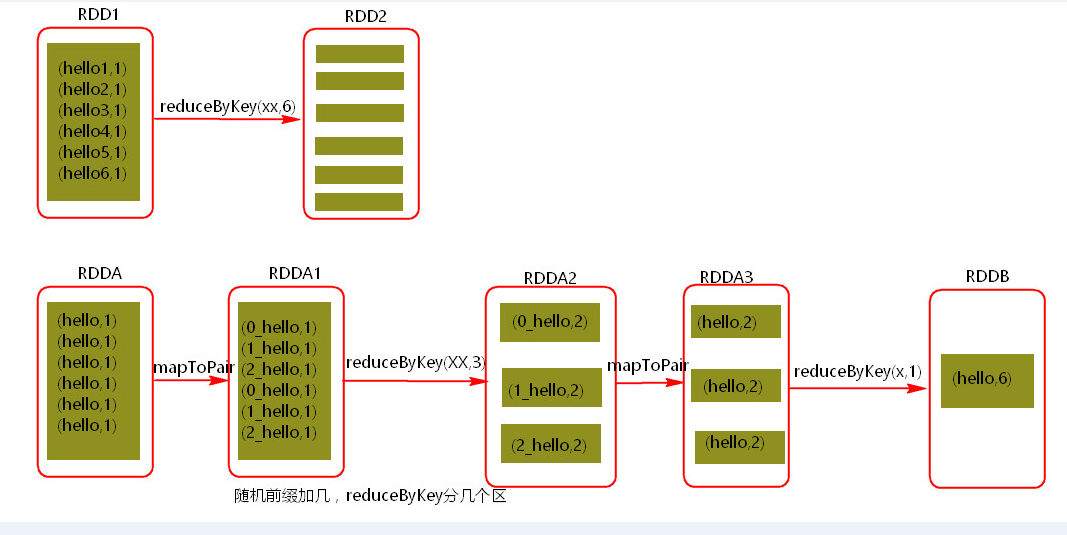
随机前缀加几,ReduceByKey分几个区。
5、将reduce join转为map join(彻底避免数据倾斜)
BroadCast+filter(或者map)
方案适用场景:
在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:
不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
方案实现原理:
普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
6、采样倾斜key并分拆join操作
方案适用场景:
两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。而另外两个普通的RDD就照常join即可。最后将两次join的结果使用union算子合并起来即可,就是最终的join结果 。
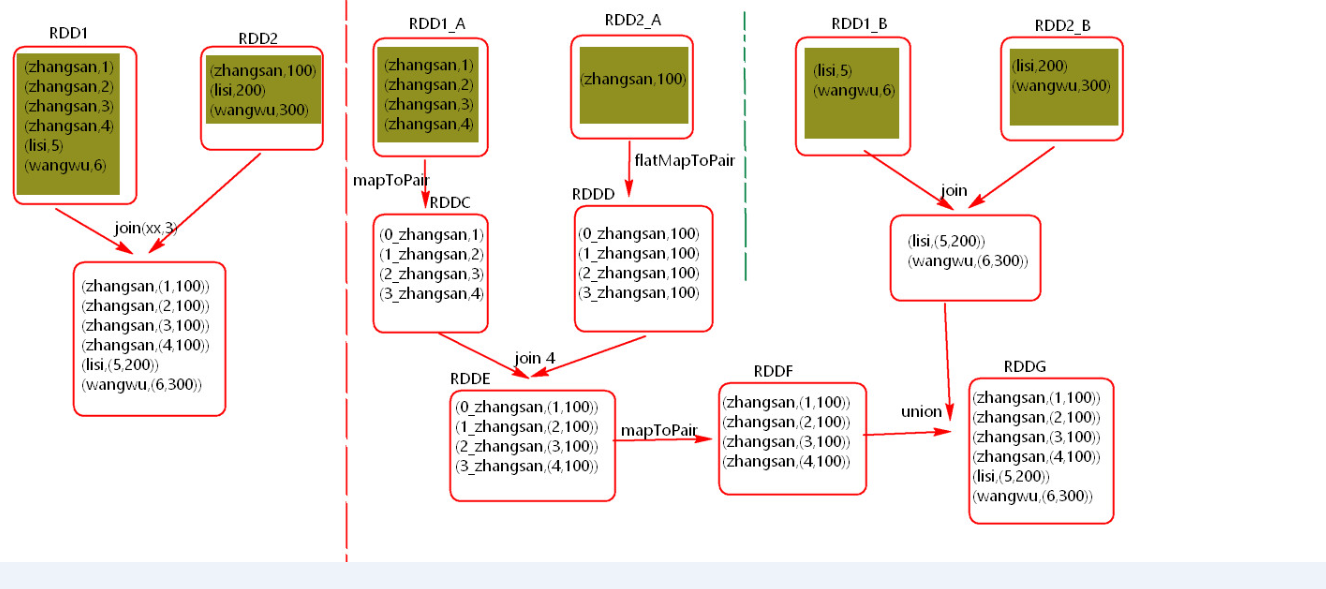
7、使用随机前缀和扩容RDD进行join
方案适用场景:
如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路:
该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。然后将该RDD的每条数据都打上一个n以内的随机前缀。同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。最后将两个处理后的RDD进行join即可。
spak数据倾斜解决方案的更多相关文章
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- 最完整的数据倾斜解决方案(spark)
一.了解数据倾斜 数据倾斜的原理: 在执行shuffle操作的时候,按照key,来进行values的数据的输出,拉取和聚合.同一个key的values,一定是分配到一个Reduce task进行处理. ...
- spark中数据倾斜解决方案
数据倾斜导致的致命后果: 1 数据倾斜直接会导致一种情况:OOM. 2 运行速度慢,特别慢,非常慢,极端的慢,不可接受的慢. 搞定数据倾斜需要: 1.搞定shuffle 2.搞定业务场景 3 搞定 c ...
- spark完整的数据倾斜解决方案
1.数据倾斜的原理 2.数据倾斜的现象 3.数据倾斜的产生原因与定位 在执行shuffle操作的时候,大家都知道,我们之前讲解过shuffle的原理. 是按照key,来进行values的数据的输出.拉 ...
- Spark数据倾斜解决方案及shuffle原理
数据倾斜调优与shuffle调优 数据倾斜发生时的现象 1)个别task的执行速度明显慢于绝大多数task(常见情况) 2)spark作业突然报OOM异常(少见情况) 数据倾斜发生的原理 在进行shu ...
- Spark数据倾斜解决方案(转)
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/skew/ Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势 发表于 2017 ...
- Hive的HQL语句及数据倾斜解决方案
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://blog.csdn.net/sdksdk0/article/details/51675005 作者: 朱培 ID ...
随机推荐
- 自己实现HashSet
HashSet的实现相对比较简单.它强依赖于HashMap,包括底层数据实际上就是存储于HashMap,由于HashMap在哈希碰撞下,如果value值相同,那么将会覆盖该value,HashSet正 ...
- Python学习—数据库篇之SQL补充
一.SQL注入问题 在使用pymysql进行信息查询时,推荐使用传参的方式,禁止使用字符串拼接方式,因为字符串拼接往往会带来sql注入的问题 # -*- coding:utf-8 -*- # auth ...
- phpstorm界面不停的indexing,不停的闪烁
选择 File->Invalidate Caches / Restart...->Invalidate and Restart,就行了!
- js实现接口隔离
昨天公司培训了接口隔离,简单说一下 接口隔离:类间的依赖关系应该建立在最小的接口上.接口隔离原则将非常庞大.臃肿的接口拆分成更小具体的接口,这样客户讲会只需要知道他们感兴趣的方法. 接口隔离原则的目的 ...
- 从Excel获取请求体
Excel文件 .py文件---------------------- import xlrdimport re def fetch_body(path,sheet,name,adict): ...
- 校赛F
问题描述 例如对于数列[1 2 3 4 5 6],排序后变为[6 1 5 2 4 3].换句话说,对于一个有序递增的序列a1, a2, a3, ……, an,排序后为an, a1, an-1, a2, ...
- Android自动化之Monkey环境搭建(一)
从事测试行业两年了,一直很喜欢研究新技术,但是最近有点慵懒.正好公司新出了产品,督促我学习monkey用来测其稳定性. 网上搜索了很久,内容总是很零散,通常需要找几篇文章才能搭好环境.特写此文,一篇文 ...
- 使用SpringBoot搭建一个简单的web工程
最近在学习SpringBoot,想写在博客园上记录一下,如有错误之处还望指出. 首先创建一个maven工程,不用勾选骨架. 在pom.xml文件中添加如下内容,使工程变成Springboot应用. & ...
- EasyPOI校验实现返回错误信息及行号
IExcelModel 获取错误信息 public class ExcelVerifyEntity implements IExcelModel { private String errorMsg; ...
- Python 3.6安装yaml时报"AttributeError: module 'pip' has no attribute 'main'"和“Non-zero exit code”错误
1.Python 3.6安装yaml时一开始报AttributeError: module 'pip' has no attribute错误,根据网上提供的解决方法修改Pycharm安装目录D:\Pr ...