Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.数据倾斜简介
1>.什么是数据倾斜
答:大量数据涌入到某一节点,导致此节点负载过重,此时就产生了数据倾斜。
2>.处理数据倾斜的两种方案
第一:重新设计key;
第二:设计随机分区;
二.模拟数据倾斜
screw.txt 文件内容
1>.App端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.srew; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class ScrewApp {
public static void main(String[] args) throws Exception {
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。
conf.set("fs.defaultFS","file:///");
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//创建一个任务对象job,别忘记把conf穿进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("WordCount");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(ScrewApp.class);
//指定map的类名,这里指定咱们自定义的map程序即可
job.setMapperClass(ScrewMapper.class);
//指定reduce的类名,这里指定咱们自定义的reduce程序即可
job.setReducerClass(ScrewReduce.class);
//设置输出key的数据类型
job.setOutputKeyClass(Text.class);
//设置输出value的数据类型
job.setOutputValueClass(IntWritable.class);
Path localPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out");
if (fs.exists(localPath)){
fs.delete(localPath,true);
}
//设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径
FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\screw.txt"));
//设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径
FileOutputFormat.setOutputPath(job,localPath);
//设置Reduce的个数为2.
job.setNumReduceTasks();
//等待任务执行结束,将里面的值设置为true。
job.waitForCompletion(true);
}
}
ScrewApp.java 文件内容
2>.Reduce端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.srew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class ScrewReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = ;
for (IntWritable value : values) {
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
ScrewReduce.java 文件内容
3>.Mapper端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.srew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class ScrewMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString(); String[] arr = line.split(" "); for (String word : arr) {
context.write(new Text(word),new IntWritable());
}
}
}
ScrewMapper.java 文件内容
执行以上代码,查看数据如下:
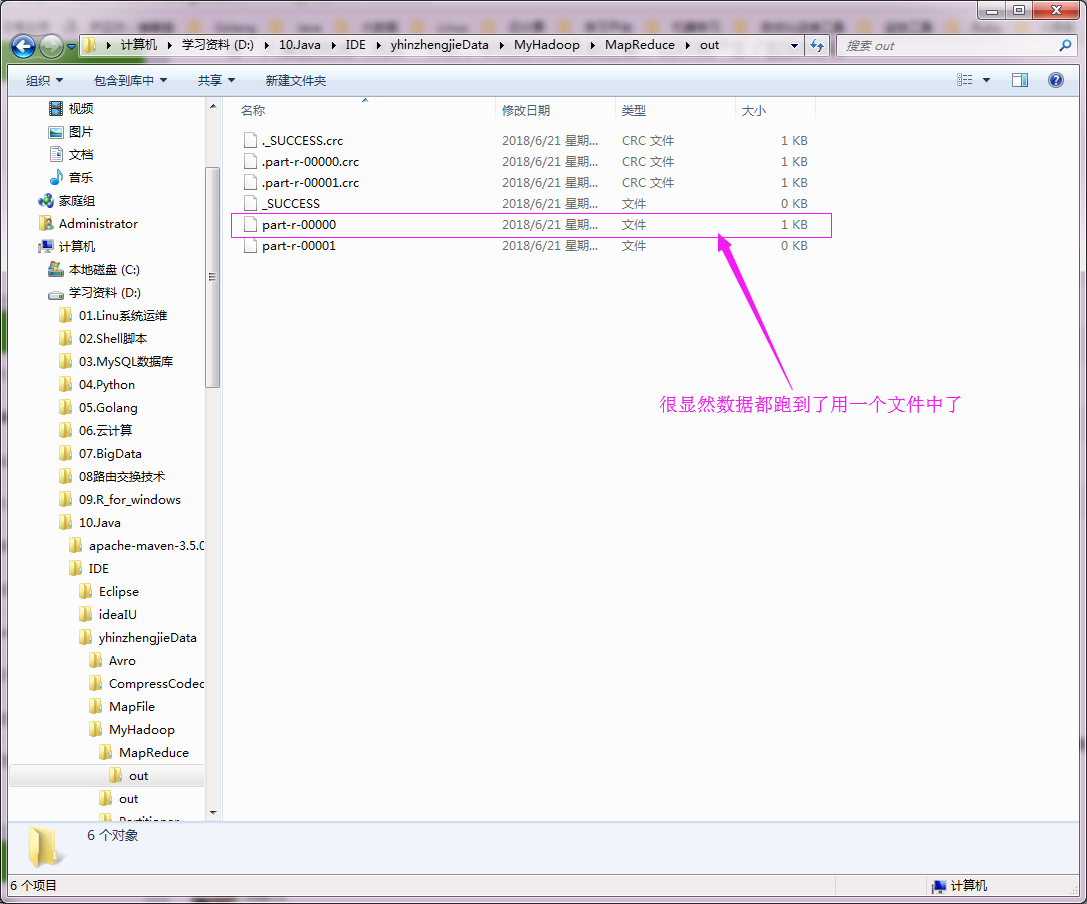
三.解决数据倾斜方案之重新设计key
1>.具体代码如下
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.srew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Random; public class ScrewMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//定义一个reduce变量
int reduces;
//定义一个随机数生成器变量
Random r;
/**
* setup方法是用于初始化值
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//通过context.getNumReduceTasks()方法获取到用户配置的reduce个数。
reduces = context.getNumReduceTasks();
//生成一个随机数生成器
r = new Random();
} @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
for (String word : arr) {
//从reducs的范围中获取一个int类型的随机数赋值给randVal
int randVal = r.nextInt(reduces);
//重新定义key
String newWord = word+"_"+ randVal;
//将自定义的key赋初始值为1发给reduce端
context.write(new Text(newWord), new IntWritable(1));
}
}
}
ScrewMapper.java 文件内容
package cn.org.yinzhengjie.srew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class ScrewMapper2 extends Mapper<LongWritable,Text,Text,IntWritable> { //处理的数据类似于“1_1 677”
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//
String[] arr = line.split("\t"); //newKey
String newKey = arr[0].split("_")[0]; //newVAl
int newVal = Integer.parseInt(arr[1]); context.write(new Text(newKey), new IntWritable(newVal)); }
}
ScrewMapper2.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.srew; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class ScrewReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
ScrewReducer.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.srew; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class ScrewApp {
public static void main(String[] args) throws Exception {
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。
conf.set("fs.defaultFS","file:///");
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//创建一个任务对象job,别忘记把conf穿进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("WordCount");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(ScrewApp.class);
//指定map的类名,这里指定咱们自定义的map程序即可
job.setMapperClass(ScrewMapper.class);
//指定reduce的类名,这里指定咱们自定义的reduce程序即可
job.setReducerClass(ScrewReducer.class);
//设置输出key的数据类型
job.setOutputKeyClass(Text.class);
//设置输出value的数据类型
job.setOutputValueClass(IntWritable.class);
Path localPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out");
if (fs.exists(localPath)){
fs.delete(localPath,true);
}
//设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径
FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\screw.txt"));
//设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径
FileOutputFormat.setOutputPath(job,localPath);
//设置Reduce的个数为2.
job.setNumReduceTasks(2);
//等待任务执行结束,将里面的值设置为true。
if (job.waitForCompletion(true)) {
//当第一个MapReduce结束之后,我们这里又启动了一个新的MapReduce,逻辑和上面类似。
Job job2 = Job.getInstance(conf);
job2.setJobName("Wordcount2");
job2.setJarByClass(ScrewApp.class);
job2.setMapperClass(ScrewMapper2.class);
job2.setReducerClass(ScrewReducer.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class);
Path p2 = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out2");
if (fs.exists(p2)) {
fs.delete(p2, true);
}
FileInputFormat.addInputPath(job2, localPath);
FileOutputFormat.setOutputPath(job2, p2);
//我们将第一个MapReduce的2个reducer的处理结果放在新的一个MapReduce中只启用一个MapReduce。
job2.setNumReduceTasks(1);
job2.waitForCompletion(true);
}
}
}
ScrewApp.java 文件内容
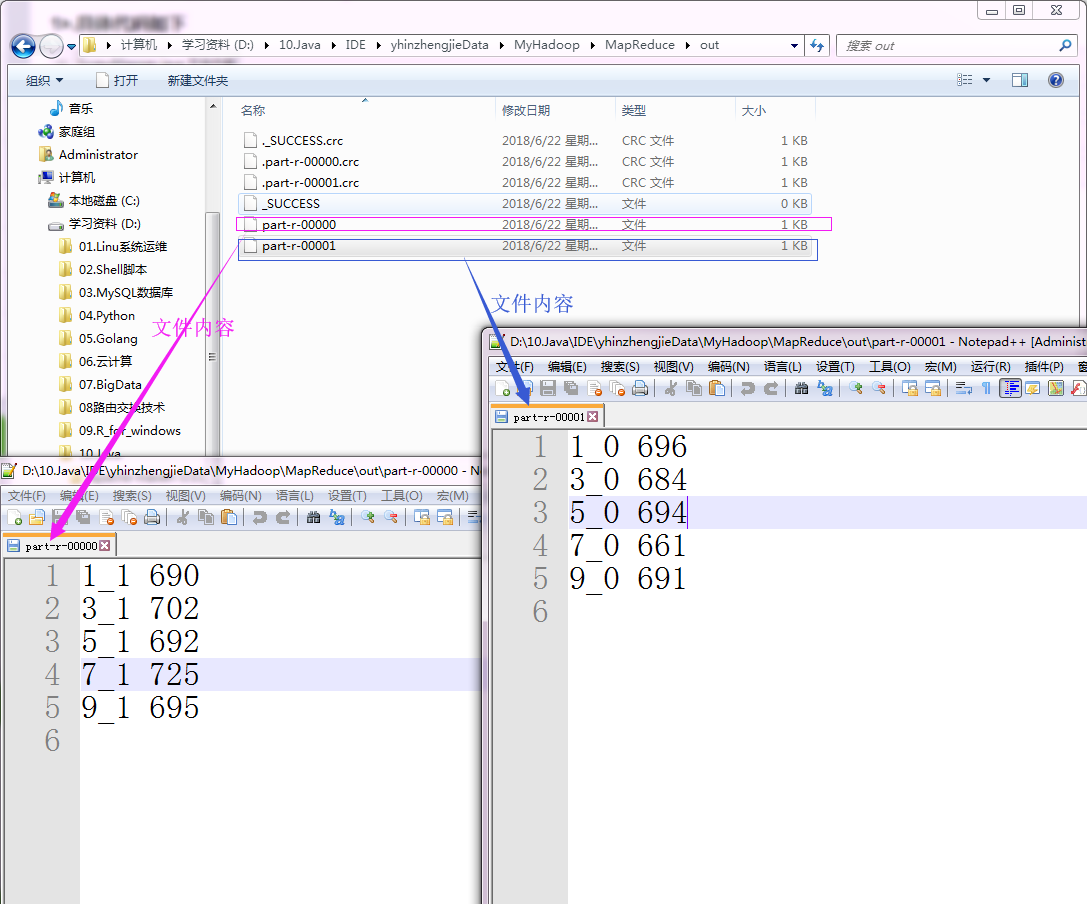
2>.检测实验结果
“D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out” 目录内容如下:
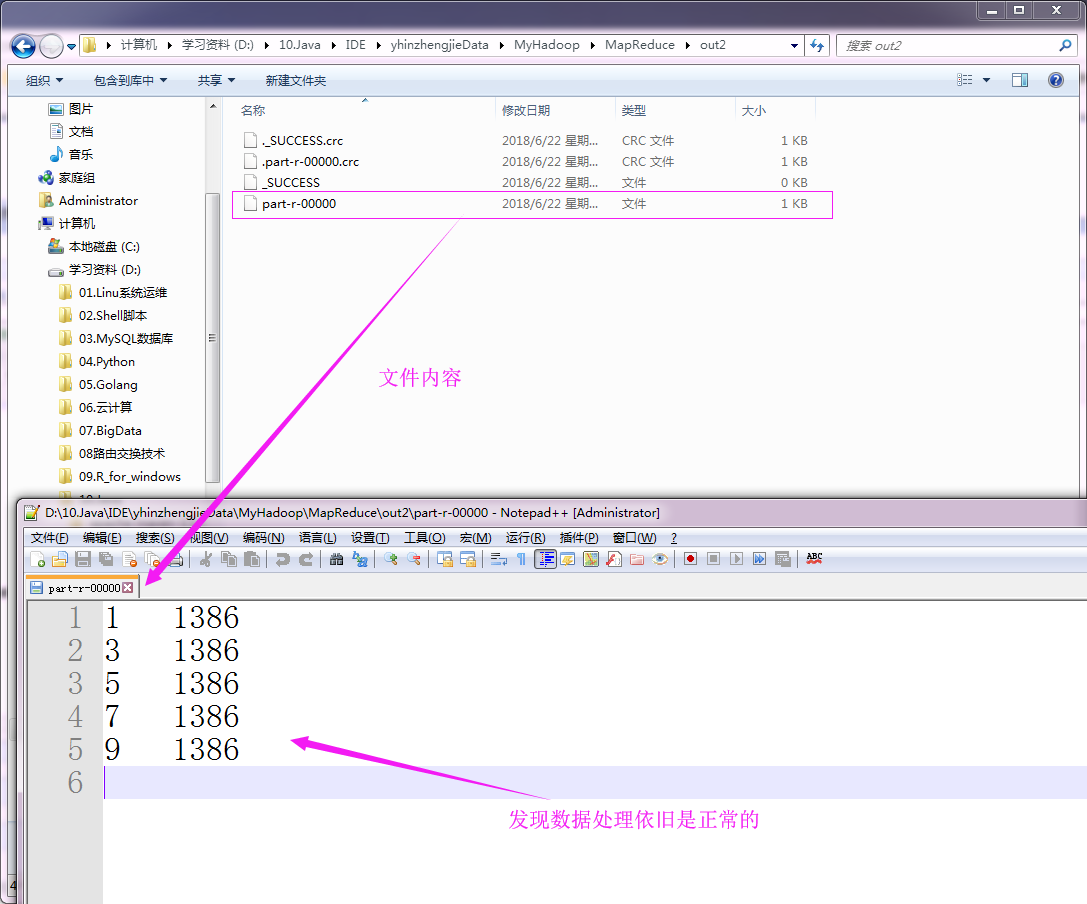
“D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out2” 目录内容如下:
四.解决数据倾斜方案之使用随机分区
1>.具体代码如下
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.screwpartition; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class Screw2Mapper extends Mapper<LongWritable,Text,Text,IntWritable> { @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] arr = line.split(" "); for(String word : arr){
context.write(new Text(word), new IntWritable(1)); } }
}
Screw2Mapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.screwpartition; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; import java.util.Random; public class Screw2Partition extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
Random r = new Random();
//返回的是分区的随机的一个ID
return r.nextInt(numPartitions);
}
}
Screw2Partition.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.screwpartition; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class Screw2Reducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value : values){
sum += value.get();
}
context.write(key,new IntWritable(sum));
}
}
Screw2Reducer.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.screwpartition; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Screw2App {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "file:///");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJobName("Wordcount");
job.setJarByClass(Screw2App.class);
job.setMapperClass(Screw2Mapper.class);
job.setReducerClass(Screw2Reducer.class);
job.setPartitionerClass(Screw2Partition.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path p = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out");
if (fs.exists(p)) {
fs.delete(p, true);
}
FileInputFormat.addInputPath(job, new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\screw.txt"));
FileOutputFormat.setOutputPath(job, p);
job.setNumReduceTasks(2);
job.waitForCompletion(true);
}
}
Screw2App.java 文件内容
2>.检测实验结果
“D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out” 目录内容如下:

“D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\MapReduce\\out2” 目录内容如下:
Hadoop基础-MapReduce的数据倾斜解决方案的更多相关文章
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.连接操作Map端Join(适合处理小表+大表的情况) no001 no002 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- spak数据倾斜解决方案
数据倾斜解决方案 数据倾斜的解决,跟之前讲解的性能调优,有一点异曲同工之妙. 性能调优中最有效最直接最简单的方式就是加资源加并行度,并注意RDD架构(复用同一个RDD,加上cache缓存).相对于前面 ...
随机推荐
- metasploit-smb扫描获取系统信息
1.msfconsle 2.use auxiliary/scanner/smb/smb_version 3. msf auxiliary(smb_version) > set RHOSTS 17 ...
- 前端页面loading效果(CSS实现)
当首页内容或图片比较多时,加载时间会比较长,此时可能出现页面白屏的情况,用户体验较差.所以,在页面完全加载出来之前,可以考虑加入loading效果,当页面完全加载完后,是loading消失即可. 1. ...
- [BZOJ4851][JSOI2016]位运算[矩阵快速幂]
题意 给定长度为 \(\rm |S|\) 的 \(\rm 01\) 串并将其倍长 \(k\) 次得到一个 \(\rm|S|\times k\) 位的二进制数 \(R\) ,求有多少种在 \([0,R- ...
- Java 中的 try catch 影响性能吗?
前几天在 code review 时发现有一段代码中存在滥用try catch的现象.其实这种行为我们也许都经历过,刚参加工作想尽量避免出现崩溃问题,因此在很多地方都想着 try catch一下. 但 ...
- More Effective C++ Item14:明智运用exception specifications
使用exception specifications你必须非常仔细去确保,函数调用的子函数.注册的回调函数不会违背约定.而设计模板内部的异常更难确保. 设计回调机制的时候,如果调用方规定了不抛出异常, ...
- Azure : 通过 SendGrid 发送邮件
SendGrid 是什么? SendGrid 是架构在云端的电子邮件服务,它能提供基于事务的可靠的电子邮件传递.并且具有可扩充性和实时分析的能力.常见的用例有:1. 自动回复用户的邮件2. 定期发送信 ...
- Jmeter(四)_16个逻辑控制器详解
循环控制器: 指定其子节点运行的次数,可以使用具体的数值,也可以设置为变量 1:勾选永远:表示一直循环下去 2:如果同时设置了线程组的循环次数和循环控制器的循环次数,那循环控制器的子节点运行的次数为两 ...
- WebSplider在线爬虫
WebSplider是什么? WebSplider在线爬虫是一个结合Web技术与爬虫技术的项目. WebSplider支持Web页面进行爬虫配置,提交配置到服务器后,服务器端爬虫程序进行数据抓取,最后 ...
- 《杜增强讲Unity之Tanks坦克大战》4-坦克的移动和旋转
4 坦克移动和旋转 本节课的目标是实现同时wsad和上下左右控制两个坦克分别移动和旋转 4.1 本节代码预览 image 将上节课场景s2另存为s3. 4.2 添加车轮扬沙效果 从Prefabs里 ...
- idou老师教你学Istio 17 : 通过HTTPS进行双向TLS传输
众所周知,HTTPS是用来解决 HTTP 明文协议的缺陷,在 HTTP 的基础上加入 SSL/TLS 协议,依靠 SSL 证书来验证服务器的身份,为客户端和服务器端之间建立“SSL”通道,确保数据运输 ...