python多线程之threading、ThreadPoolExecutor.map
背景:
(多线程执行同一个函数任务)某个应用场景需要从数据库中取出几十万的数据时,需要对每个数据进行相应的操作。逐个数据处理过慢,于是考虑对数据进行分段线程处理:
方法一:使用threading模块
代码:
# -*- coding: utf-8 -*-
import math
import random
import time
from threading import Thread _result_list = [] def split_df():
# 线程列表
thread_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
thread = Thread(target=work, args=(item, _list,))
thread_list.append(thread)
# 在子线程中运行任务
thread.start()
count += split_count # 线程同步,等待子线程结束任务,主线程再结束
for _item in thread_list:
_item.join() def work(df, _list):
"""
每个线程执行的任务,让程序随机sleep几秒
:param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
_result_list.append(df) if __name__ == '__main__':
split_df()
print(len(_result_list), _result_list)
测试结果:

方法二:使用ThreadPoolExecutor.map
代码:
# -*- coding: utf-8 -*-
import math
import random
import time
from concurrent.futures import ThreadPoolExecutor def split_list():
# 线程列表
new_list = []
count_list = []
# 需要处理的数据
_l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 每个线程处理的数据大小
split_count = 2
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
new_list.append(_list)
count_list.append(count)
count += split_count
return new_list, count_list def work(df, _list):
""" 线程执行的任务,让程序随机sleep几秒
:param df:
:param _list:
:return:
"""
sleep_time = random.randint(1, 5)
print(f'count is {df},sleep {sleep_time},list is {_list}')
time.sleep(sleep_time)
return sleep_time, df, _list def use():
new_list, count_list = split_list()
with ThreadPoolExecutor(max_workers=len(count_list)) as t:
results = t.map(work, new_list, count_list) # 或执行如下两行代码
# pool = ThreadPoolExecutor(max_workers=5)
# 使用map的优点是 每次调用回调函数的结果不用手动的放入结果list中
# results = pool.map(work, new_list, count_list) # map返回一个迭代器,其中的回调函数的参数 最好是可以迭代的数据类型,如list;如果有 多个参数 则 多个参数的 数据长度相同;
# 如: pool.map(work,[[1,2],[3,4]],[0,1]]) 中 [1,2]对应0 ;[3,4]对应1 ;其实内部执行的函数为 work([1,2],0) ; work([3,4],1)
# map返回的结果 是 有序结果;是根据迭代函数执行顺序返回的结果
print(type(results))
# 如下2行 会等待线程任务执行结束后 再执行其他代码
for ret in results:
print(ret)
print('thread execute end!') if __name__ == '__main__':
use()
测试结果:
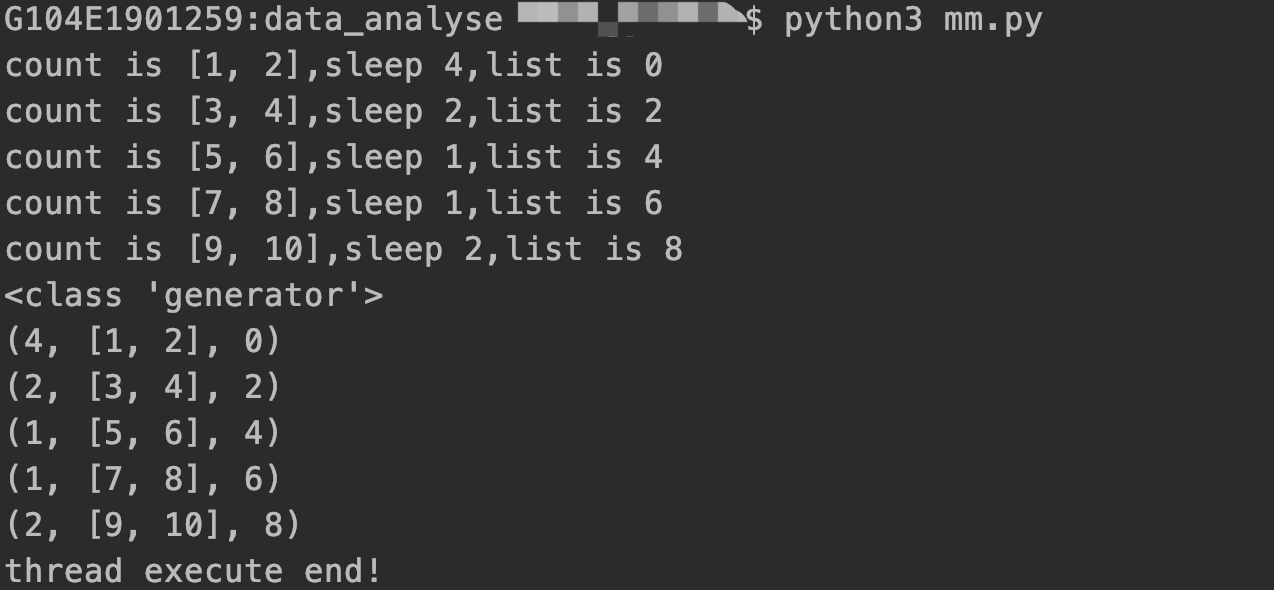
参考链接:https://www.cnblogs.com/rgcLOVEyaya/p/RGC_LOVE_YAYA_1103_3days.html
python多线程之threading、ThreadPoolExecutor.map的更多相关文章
- python多线程之Threading
什么是线程? 线程是操作系统内核调度的基本单位,一个进程中包含一个或多个线程,同一个进程内的多个线程资源共享,线程相比进程是“轻”量级的任务,内核进行调度时效率更高. 多线程有什么优势? 多线程可以实 ...
- “死锁” 与 python多线程之threading模块下的锁机制
一:死锁 在死锁之前需要先了解的概念是“可抢占资源”与“不可抢占资源”[此处的资源可以是硬件设备也可以是一组信息],因为死锁是与不可抢占资源有关的. 可抢占资源:可以从拥有他的进程中抢占而不会发生副作 ...
- python多线程之threading模块
threading模块中的对象 其中除了Thread对象以外,还有许多跟同步相关的对象 threading模块支持守护线程的机制 Thread对象 直接调用法 import threading imp ...
- python 线程之 threading(四)
python 线程之 threading(三) http://www.cnblogs.com/someoneHan/p/6213100.html中对Event做了简单的介绍. 但是如果线程打算一遍一遍 ...
- python 线程之 threading(三)
python 线程之 threading(一)http://www.cnblogs.com/someoneHan/p/6204640.html python 线程之 threading(二)http: ...
- python并发编程之threading线程(一)
进程是系统进行资源分配最小单元,线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.进程在执行过程中拥有独立的内存单元,而多个线程共享内存等资源. 系列文章 py ...
- python利用(threading,ThreadPoolExecutor.map,ThreadPoolExecutor.submit) 三种多线程方式处理 list数据
需求:在从银行数据库中取出 几十万数据时,需要对 每行数据进行相关操作,通过pandas的dataframe发现数据处理过慢,于是 对数据进行 分段后 通过 线程进行处理: 如下给出 测试版代码,通过 ...
- python多线程之Condition(条件变量)
#!/usr/bin/env python # -*- coding: utf-8 -*- from threading import Thread, Condition import time it ...
- python多线程之semaphore(信号量)
#!/usr/bin/env python # -*- coding: utf-8 -*- import threading import time import random semaphore = ...
随机推荐
- scrum例会报告+燃尽图01
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2019fall/homework/9954 一.小组情况 组长:贺敬文组员:彭思雨 王志文 位军营 徐丽君队名 ...
- NP-Hard问题和NP-Complete问题
对 NP-Hard问题和NP-Complete问题的一个直观的理解就是指那些很难(很可能是不可能)找到多项式时间算法的问题.因此一般初学算法的人都会问这样一个问题:NP-Hard和NP-Complet ...
- Scala学习(四)——模式匹配与函数组合
函数组合 让我们创建两个函数: def f(s: String) = "f(" + s + ")" def g(s: String) = "g(&qu ...
- python问题笔记
1.for...in...:和while...:循环末端都可以有一个else:语句,但他仅在循环不是由break语句退出时才会被运行 2.input raw input区别 一. 可以看到:这两个函数 ...
- python - lambda 函数使用
# if we need it only once and it's quite simple def make_incrementor(n): return lambda x: x + n f = ...
- fiddler配置会话框菜单栏
1.添加会话框菜单:鼠标移至会话框菜单的左上角“#”位置,右键>Customize column,Collection下拉菜单选择"Miscellaneous",Field ...
- apache配置静态缓存
配置静态缓存:节省带宽,加快访问速度,提高用户体验.<IfModule mod_expires.c> ExpiresActive on ExpiresByType image/gif &q ...
- ListView控件,表格模式下,如何调整行高
参考说明: https://www.codeproject.com/Articles/1401/Changing-Row-Height-in-an-owner-drawn-Control 如果所有项的 ...
- Mysql事务特性
事务概念 事务可由一条sql或者一组sql组成.事务是访问并更新数据库中各种数据项的一个程序执行单元. 事务会把数据库从一种一致状态转换为另一种一致状态.在数据提交工作时,可以确保要么所有修改都已经保 ...
- SVM的推导和理解
主要记录了SVM思想的理解,关键环节的推导过程,主要是作为准备面试的需要. 1.准备知识-点到直线距离 点\(x_0\)到超平面(直线)\(w^Tx+b=0\)的距离,可通过如下公式计算: \[ d ...