Python-爬虫-针对有frame框架的页面
有的页面会使用frame 框架,使用Selenium + PhantomJS 后并不会加载iframe 框架中的网页内容。iframe 框架相当于在页面中又加载了一个页面,需要使用Selenium 的 switch_to.frame() 方法加载
(官网给的方法是switch_to_frame(),但是IDE提醒使用前面的方法替代该方法)。
比如:
driver.switch_to.frame('g_iframe')
一、介绍
本例子用Selenium +phantomjs爬取流媒体(http://www.lmtw.com/search.php?show=title%2Ckeyboard%2Cwriter&searchget=1&keyboard=%E7%94%B5%E8%A7%86)的资讯信息,输入给定关键字抓取资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
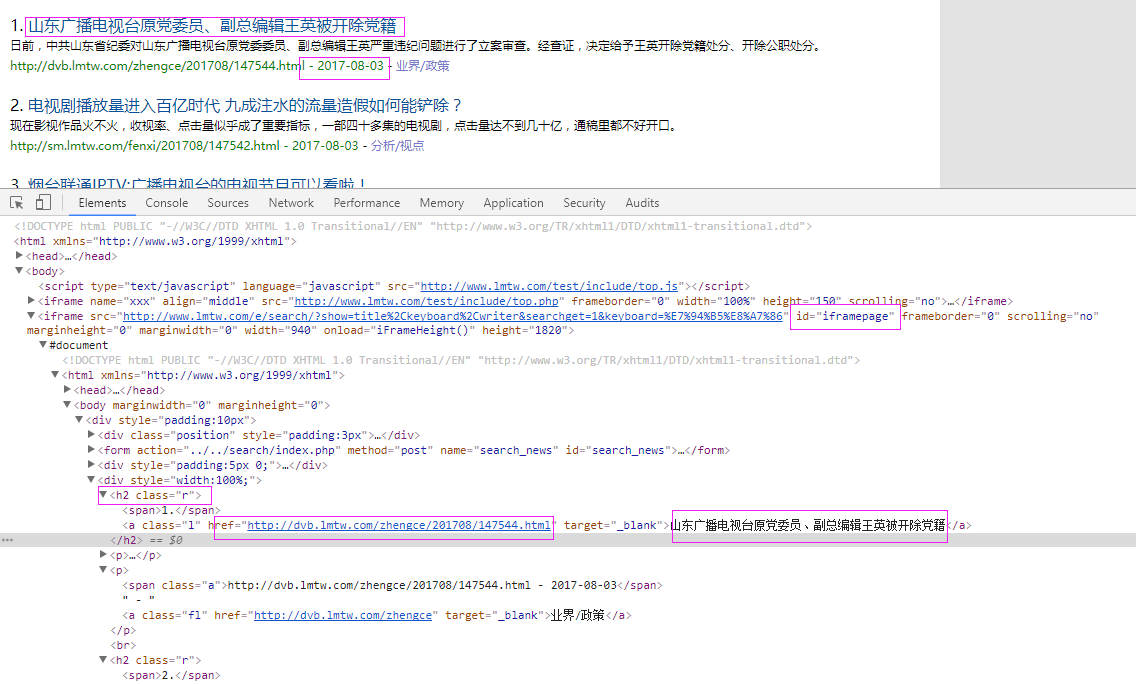
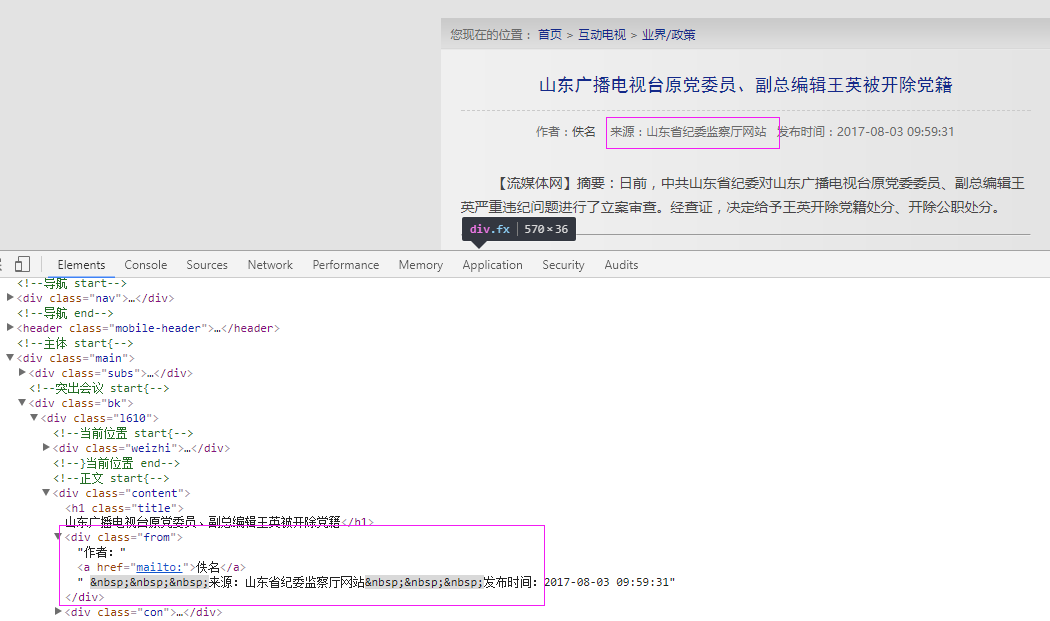
二、网站信息
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc('h2[class="r"]')
2、抓取标题
抓取代码:title = element.find('a').text().encode('utf8').strip()
3、抓取链接
抓取代码:url = element.find('a').attr('href')
4、抓取日期
抓取代码:dateElements = doc('span[class="a"]')
5、抓取来源
抓取代码:strSources = dochtml('div[class="from"]').text().encode('utf8').strip()
四、完整代码
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
import datetime
from pyquery import PyQuery as pq
import LogFile
import mongoDB
import urllib
class lmtwSpider(object):
def __init__(self,driver,log,keyword_list,websearch_url,valid,filter):
''' :param driver: 驱动
:param log: 日志
:param keyword_list: 关键字列表
:param websearch_url: 搜索网址
:param valid: 采集参数 0:采集当天;1:采集昨天
:param filter: 过滤项,下面这些内容如果出现在资讯标题中,那么这些内容不要,过滤掉
'''
self.log = log
self.driver = driver self.webSearchUrl_list = websearch_url.split(';')
self.keyword_list = keyword_list
self.db = mongoDB.mongoDbBase()
self.valid = valid self.start_urls = []
# 过滤项
self.filter = filter for keyword in keyword_list:
url = websearch_url + urllib.quote(keyword)
self.start_urls.append(url) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: '2017-06-20 10:22 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
strDate = re.findall(datePattern, strDateText) if len(strDate) == 1:
if self.valid == 0 and self.Comapre_to_days(currentDate, strDate[0])==0:
return True, currentDate
elif self.valid == 1 and self.Comapre_to_days(currentDate, strDate[0])==1:
return True,str(datetime.datetime.now() - datetime.timedelta(days=1))[0:10]
elif self.valid == 2 and self.Comapre_to_days(currentDate, strDate[0]) == 2:
return True,str(datetime.datetime.now() - datetime.timedelta(days=2))[0:10]
return False, '' def log_print(self, msg):
'''
# 日志函数
# :param msg: 日志信息
# :return:
# '''
print '%s: %s' % (time.strftime('%Y-%m-%d %H-%M-%S'), msg) def scrapy_date(self):
try:
strsplit = '------------------------------------------------------------------------------------'
# isbreak = False
keywordIndex = 0
for link in self.start_urls:
self.driver.get(link)
self.driver.switch_to.frame('iframepage')
keyword = self.keyword_list[keywordIndex]
keywordIndex += 1 selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = [] self.log.WriteLog(strsplit)
self.log_print(strsplit)
Elements = doc('h2[class="r"]')
dateElements = doc('span[class="a"]')
index = 0
for element in Elements.items():
date = dateElements[index].text
index += 1
flag,strDate = self.date_isValid(date)
if flag:
title = element.find('a').text().encode('utf8').strip() # 考虑过滤项
if title.find(self.filter)>-1:
continue
if title.find(keyword) > -1:
url = element.find('a').attr('href')
dictM = {'title': title, 'date': strDate,
'url': url, 'keyword': keyword, 'introduction': title}
infoList.append(dictM)
if len(infoList) > 0:
for item in infoList:
item['sourceType']=1
url = item['url']
self.driver.get(url)
# self.driver.switch_to.frame('iframepage')
htext = self.driver.execute_script("return document.documentElement.outerHTML")
dochtml = pq(htext)
strSources = dochtml('div[class="from"]').text().encode('utf8').strip()
txtsource = strSources[strSources.find('来源:') + 9:]
item['source']=txtsource[0:txtsource.find(' ')] self.log.WriteLog('title:%s' % item['title'])
self.log.WriteLog('url:%s' % item['url'])
self.log.WriteLog('date:%s' % item['date'])
self.log.WriteLog('source:%s' % item['source'])
self.log.WriteLog('kword:%s' % item['keyword'])
self.log.WriteLog(strsplit) self.log_print('title:%s' % item['title'])
self.log_print('url:%s' % item['url'])
self.log_print('date:%s' % item['date'])
self.log_print('source:%s' % item['source'])
self.log_print('kword:%s' % item['keyword'])
self.log_print(strsplit)
self.db.SaveInformations(infoList)
except Exception,e:
self.log.WriteLog('lmtwSpider:'+ e.message)
finally:
pass
Python-爬虫-针对有frame框架的页面的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- js实现frame框架部分页面的刷新
一.先来看一个简单的例子: 下面以三个页面分别命名为frame.html.top.html.bottom.html为例来具体说明如何做. frame.html 由上(top.html)下(bottom ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
随机推荐
- [poj] 2074 Line of Sight || 直线相交求交点
原题 给出一个房子(线段)的端点坐标,和一条路的两端坐标,给出一些障碍物(线段)的两端坐标.问在路上能看到完整房子的最大连续长度是多长. 将障碍物按左端点坐标排序,然后用房子的右端与障碍物的左端连线, ...
- 怎么用tomcat对socket接口的程序进行调试
对socket(套接字)的demo方法大多都是用main方法进行测试的,那如何用tomcat进行测试呢? 这里需要借助一个工具:工具的名字是:Sockettool.exe .下图是该工具的内容.连上监 ...
- linux--lsof
lsof(list open files)是一个列出当前系统打开文件的工具.在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件.所以如传输控制协议 ...
- XmlSerializer使用
XmlSerializer是对xml进行序列化操作的对象.写了一个Order的序列化方法供留念. 序列化针对有get,set的属性:属性必须是public方式:对象顺序和序列化的顺序一致. 对象定义 ...
- Html5学习进阶四 表单元素和表单属性
HTML5 的新的表单元素: HTML5 拥有若干涉及表单的元素和属性. 本章介绍以下新的表单元素: datalist keygen output 浏览器支持 Input type IE Firefo ...
- 整数拆分问题_C++
一.问题背景 整数拆分,指把一个整数分解成若干个整数的和 如 3=2+1=1+1+1 共2种拆分 我们认为2+1与1+2为同一种拆分 二.定义 在整数n的拆分中,最大的拆分数为m,我们记它的方案数 ...
- 花匠(NOIP2013)(神奇纯模拟)
原题传送门 这是道很奇怪的题目,真不知道为什么要放到T2. 也许是T1太水了 首先先看题, 题目要求一个数列中下标为偶数的点比临近的下表为奇数的点更大或更小 其实就是说在原数组中找到一个最长的波动数列 ...
- 戴文的Linux内核专题:03 驱动程序【转】
转自:http://www.lai18.com/content/432194.html 驱动程序是使内核能够沟通和操作硬件或协议(规则和标准)的小程序.没有驱动程序,内核不知道如何与硬件沟通或者处理协 ...
- qt include无法自动补齐
原因一: 检查cmake有没有include_directories 原因二: CmakeList.txt放错位置 原因三: 没有用qt new file来创建头文件
- ef code first commad
PM> enable-migrations 已在项目“EasyWeChat.Data”中启用迁移.若要覆盖现有迁移配置,请使用 -Force 参数. PM> add-migration 位 ...