spark0.9.0安装
利用周末的时间安装学习了下最近很火的Spark0.9.0(江湖传言,要革hadoop命,O(∩_∩)O),并体验了该框架下的机器学习包MLlib(spark解决的一个重点就是高效的运行迭代算法),下面是整个安装过程(图文并茂)
说明:安装环境,centos64位12G的服务器
安装方式,单机伪分布式版
一,安装JDK
由于机器之前已经安装了jdk1.7.0,此步骤略去,网上可以搜到很多安装教程。
二,安装Hadoop
我这里安装的是hadoop2.2.0
第1步,添加hadoop用户(可选)

第2步,ssh免密码登陆
首先,安装Openssh

然后,设置ssh的免密码登陆
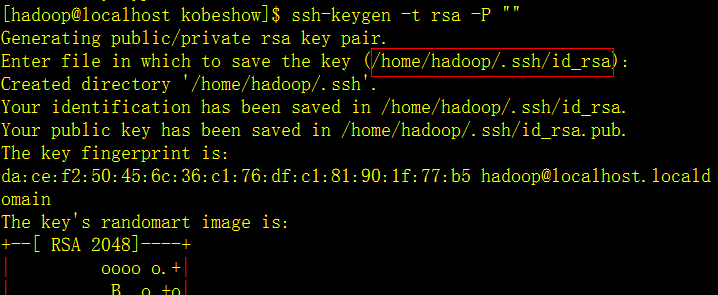
红框的是输入了key存放的路径位置。
然后,cd到这个目录下

输入后,chmod 600 authorized_keys
最后验证,是否可以免密码登陆
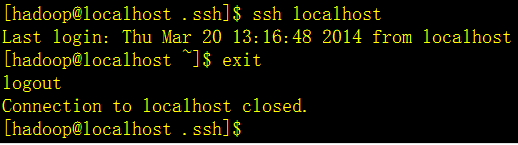
第3步,hadoop2.2.0安装
用户wget命令下载hadoop
$ wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.2.0/hadoop-2.2.0.tar.gz
解压到目录里面(我解压的目录是:/home/hadoop/)
$ vim ~/.bashrc
export HADOOP_PREFIX=/home/hadoop/hadoop-2.2.0
export
HADOOP_COMMON_HOME=$HADOOP_PREFIX
export
HADOOP_HDFS_HOME=$HADOOP_PREFIX
export
HADOOP_MAPRED_HOME=$HADOOP_PREFIX
export
HADOOP_YARN_HOME=$HADOOP_PREFIX
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
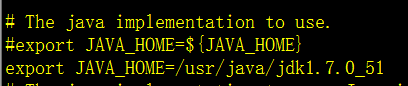
修改配置hadoop-env.sh,把java路径写进去
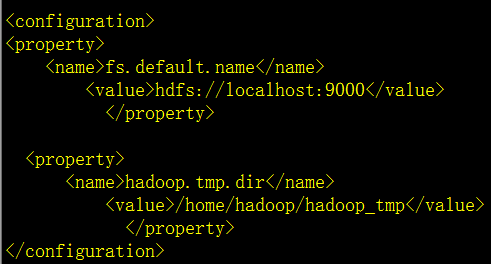
修改配置core-site.xml
修改配置hdfs-site.xml
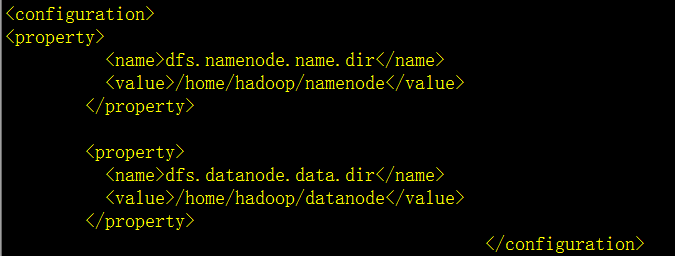
修改配置mapred-site.xml
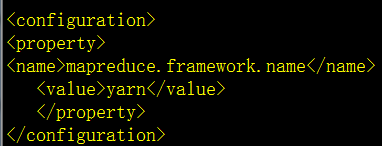
namenode格式化
bin/hdfs namenode -format
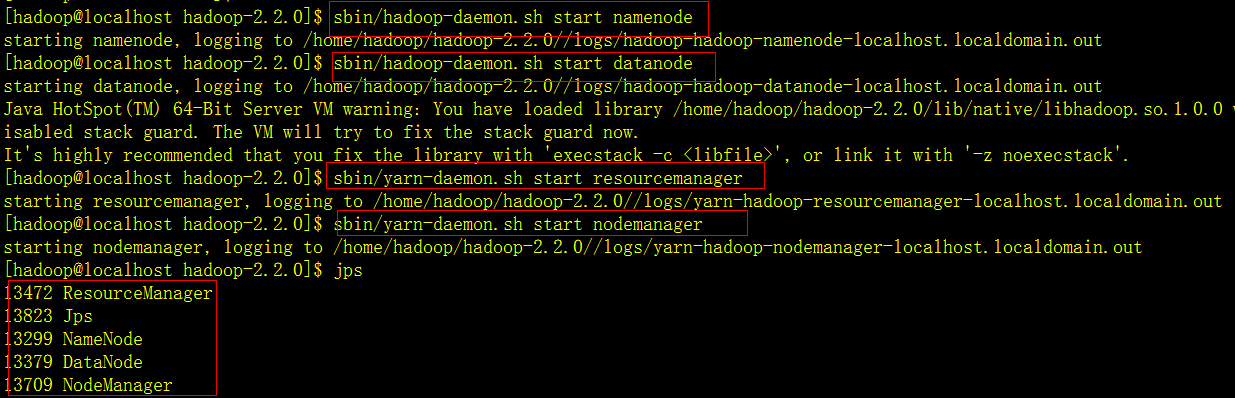
启动namenode,datanode,resourcemanager,nodemanager
第4步,Spark0.9.0安装
第一步,下载安装scala
wget http://www.scala-lang.org/files/archive/scala-2.10.3.tgz
解压scala,放到/usr/lib下面
修改环境变量 vim /etc/profile
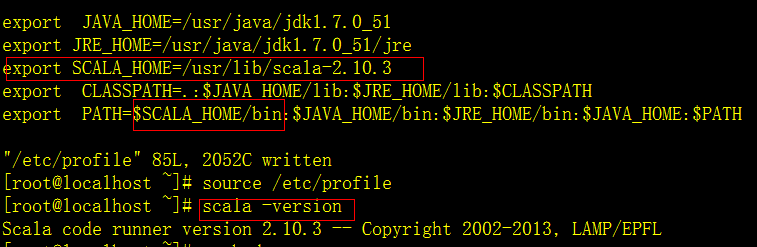
修改完成之后source /etc/profile
第二步,下载安装spark
解压spark,tar -zxvf spark-0.9.0-incubating-bin-hadoop2.tgz
修改环境变量,在/etc/profile里面加上spark目录 
修改完后,source /etc/profile
打开hadoop,namenode,datanode,resourcemanager,nodemanager
打开spark里面sbin下面的start-all.sh
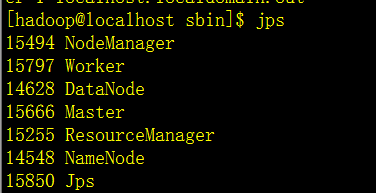
至此,单机版的spark环境已经搭建完成了,下面体验下spark自带的例子,计算圆周率pi
在bin目录下,执行./run-example org.apache.spark.examples.SparkPi
运行结果如下
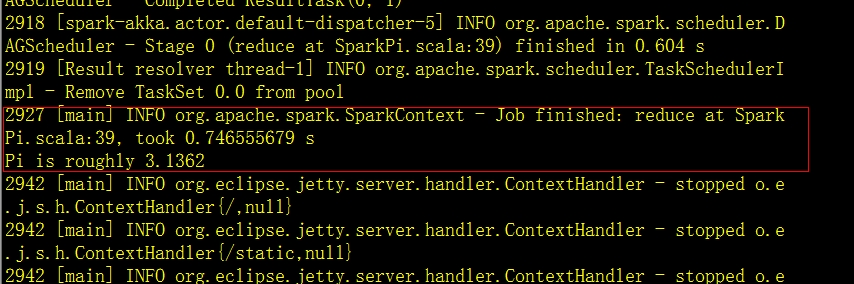
算出来pi=3.1362
体验MLlib
MLlib目前包括分类(LR,SVM,NB)、聚类(Kmeans)、推荐(ALS,MF)三大模块,关于这些算法,官网也给了些例子,目前包含有scala,java,python三种API,http://spark.apache.org/docs/0.9.0/mllib-guide.html,先试试LR
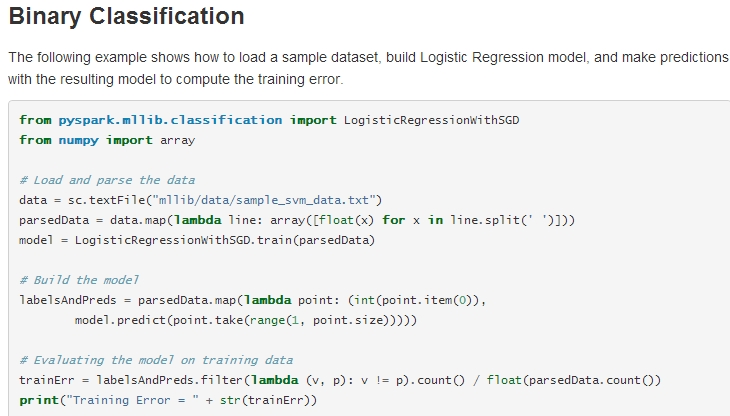
第一种方法是:可以在pyspark shell 上一行一行运行,如下图所示
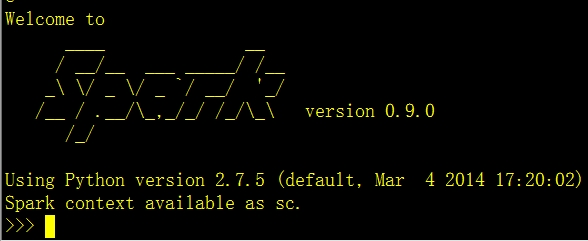
类似跟python shell一样,一行一行执行,不过要注意的地方就是,上面代码中的sc.textFile(),最好写本文文件的全路径
还有一种方法是:把代码写成*.py文件,然后通过bin/pyspark *.py的方式来执行
from pyspark.mllib.classification import LogisticRegressionWithSGD
from numpy import array
from pyspark.context import SparkContext
#一定要创建sparkcontext(该类定义请参考文档),上一个方法因为在pyspark shell上,已经自定了SparkContext
sc=SparkContext('local','test')
# Load and parse the data
data = sc.textFile("/home/hadoop/spark-0.9.0/mllib/data/sample_svm_data.txt")
parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')]))
model = LogisticRegressionWithSGD.train(parsedData) # Build the model
labelsAndPreds = parsedData.map(lambda point: (int(point.item(0)),
model.predict(point.take(range(1, point.size))))) # Evaluating the model on training data
trainErr = labelsAndPreds.filter(lambda (v, p): v != p).count() / float(parsedData.count())
print("Training Error = " + str(trainErr))
执行的结果如下所示,

给出了逻辑回归里面的回归系数跟截距项,最后分类结果如下

得到的训练错误率为39.8%,可以看到用的时间还是非常快的,OK,其他的算法,也可以通过类似的方式体验了,整个MLlib使用起来还是相当的简单,代码量也小,接下来,学习下里面的机器学习算法源代码(现实使用需要结合业务特点,去修改里面的一些源码)。
本篇完
spark0.9.0安装的更多相关文章
- spark0.8.0安装与学习
spark0.8.0安装与学习 原文地址:http://www.yanjiuyanjiu.com/blog/20131017/ 环境:CentOS 6.4, Hadoop 1.1.2, J ...
- Spark0.8.0的安装配置
1.profile export SCALA_HOME=/home/hadoop/scala-2.9.3SPARK_080=/home/hadoop/spark-0.8.0export SPARK_H ...
- 记:MySQL 5.7.3.0 安装 全程截图
前言: 下一个班快讲MySQL数据库了,正好把服务器里面的MySQL卸了重装了一下. 截个图,作为笔记.也正好留给需要的朋友们. 目录: 下载软件 运行安装程序 安装程序欢迎界面 许可协议 查找更新 ...
- 烂泥:zabbix3.0安装与配置
本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanniweb 这个月又快过完了,最近也比较忙,没时间写文章,今天挤点时间把zabbix3.0安装与配置 ...
- CentOS 7.0安装配置Vsftp服务器
一.配置防火墙,开启FTP服务器需要的端口 CentOS 7.0默认使用的是firewall作为防火墙,这里改为iptables防火墙. 1.关闭firewall: systemctl stop fi ...
- elasticsearch5.0.0 安装插件及配置过程
elasticsearch5.0.0 安装插件及配置过程 由于es5.0是里程碑式的更新,所以很多变化的地方,暂时我就插件安装遇到的问题记录一下. 插件安装命令 2.3版本的安装命令 安装Marvel ...
- IIS和4.0安装到底有没有先后顺序解答
在很多人或许很多技术大神都会觉得IIS的安装和4.0没得先后顺序的.其错误弊端在与IIS没有注册到4.0上. 经过今天遇到了服务器安装服务端发觉报错[无法识别的属性“targetFramework”. ...
- Hadoop2.6.0安装 — 集群
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6034187.html 这里写点 Hadoop2.6.0集群的安装和简单配置,一方面是为自 ...
- zabbix3.0安装部署文档
zabbix v3.0安装部署 摘要: 本文的安装过程摘自http://www.ttlsa.com/以及http://b.lifec-inc.com ,和站长凉白开的<ZABBIX从入门到精通v ...
随机推荐
- Vue-router(vue2.0)用法示例
一.新建3个组件 1./src/components/post.vue <template> <div> hello world! this is POST! </div ...
- Linux组件封装(一)中互斥锁MutexLock的封装
本文对Linux中的pthread_mutex_t做一个简易的封装. 互斥锁主要用于互斥,互斥是一种竞争关系,主要是某一个系统资源或一段代码,一次做多被一个线程访问. 条件变量主要用于同步,用于协调线 ...
- 浏览器网页推断手机是否安装IOS/Androidclient程序
IOS 原理例如以下: 为HTML页面中的超链接点击事件添加一个setTimeout方法. 假设在iPhone上面500ms内,本机有应用程序能解析这个协议并打开程序,则这个回调方法失效. 假设本机没 ...
- ubuntu12.04 下安装nodejs
liunx里面安装nodejs我也找了非常多文章,貌似对非常多liunx新手来讲不是非常清楚,以下是我结合一些文章,亲自实践得到的安装步骤.同一时候还有大家关心的与seajs紧密相关的spm模块的安装 ...
- ecplise内存配置
-server -Xms256m -Xmx512m -XX:PermSize=128M -XX:MaxPermSize=256m -XX:+UseG1GC
- JUnit编写单元测试代码注意点小结
用eclipse编写单元测试的时候,可以直接选中某个类,然后右键new新疆一个junit case,界面如下图1所示: 图1:新建test case 选 择图1中的JUnit Test Case,然后 ...
- Docker DevOps实战: 一分钟搭建Hexo博客
原文地址:https://yq.aliyun.com/articles/53772 Hexo博客 Hexo 是一个快速.简洁且高效的博客框架.Hexo 使用 Markdown解析文章,在几秒内,即可利 ...
- Linux Mint (应用软件— 虚拟机:Virtualbox)
近期想自己折腾一下Linux系统本身.比方Linux裁减或者移植.裁减或者移植Linux是一件麻烦的事情.而且出错后会影响到当前的系统.怎样才干不影响当前机器上的系统呢,于是便想到了虚拟机.在当前系统 ...
- ie8下面版本号(包含ie8)的浏览器不支持html5标签属性解决方式(Modernizr 2.6.2插件的使用)
我这边申明下:我写这篇日志主要是想然ie8可以支持html5的个别标签闭合,并不能让ie全然支持html5.我之前写的可能会误导非常多同学.希望大家能明确. 今天脑抽想用html5标签设计一个网页.我 ...
- org.springframework.beans.factory.UnsatisfiedDependencyException
© 版权声明:本文为博主原创文章,转载请注明出处 1.问题描述: 搭建SSH框架,启动时报错如下: 严重: Context initialization failed org.springframew ...