机器学习Hands On Lab
fetch_data
fetch_mldata默认路径是在scikit_learn_data路径下,mnist的mat文件其实直接放置到scikit_lean/mldata下面即可通过fetch_mldata中获取;当然路径信息其实是fetch_home函数中定义的;
洗牌训练数据
为了避免数据的有序对于训练的影响,有的时候需要对于数据进行随机排列;比如对于7万个手写数字的样本,前60000个做训练集,这6万个需要通过np.random.permutation(60000)来进行随机重排,也成为洗牌(shuffle)。但是这种洗牌主要用于样本本身不具备顺序性;但是对于一些样本之间具有关联系,比如具有时间排序联系(股票,天气)则尽量避免洗牌操作,因为训练的本身就是具有训练时序性。
唉,在做手写体测试的时候,每次执行从洗牌到训练到验证(sdg_clf.predict([some_digit]))的时候发现经常执行结果不一样,有的时候能够识别some_digit为5,有的则识别不出来。
scores和predict的差别
注意模型的scores和predict的差别,前者其实是对于样本可能是某个值的一种可能值;后者则是直接根据X预测y,在分类算法里面,predict返回的就是分类类别,里面本质上是计算某个用例在各个分类中的概率,选择概率最大的那个;
用decision_function来代替predict,前者返回的内容scores;scores现在我的理解是对于二元/多元计分,通常是根据分值最大的那个分类作为predict的返回值(所以predict在内部实现是是先调用decision_function,然后再自行判断类别),所谓分值的阈值也是判断是否的分割线;那么对于多分类的处理是怎样的呢?
>>> cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
其中分值(scoring)的种类如下表所示:
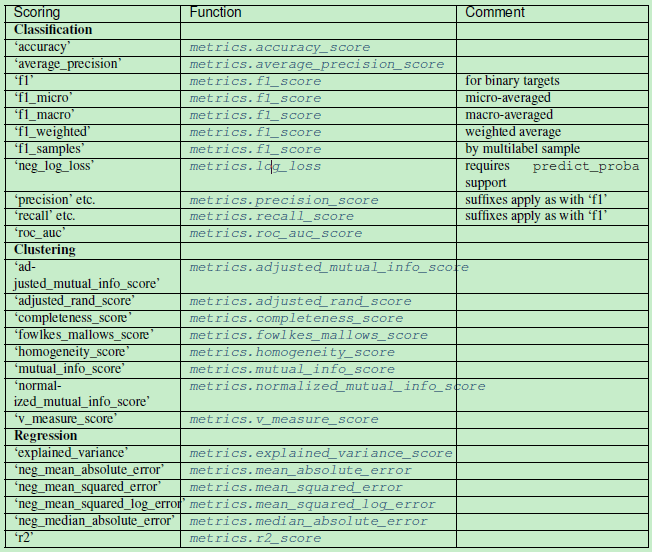
参考:
http://scikit-learn.org/stable/modules/model_evaluation.html
ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42))
这个random_state是做什么的?一个算法只要指定了random_state,就可以保证每次产生的随机数都是一致的,可以保证多次运行产生的模型一致;很多时候是测试阶段为了获取稳定测试效果会如此处理;在生产环境很多场景是需要随记的;主要还是看应用场景,是否需要random_state。
机器学习Hands On Lab的更多相关文章
- 机器学习中jupyter lab的安装方法以及使用的命令
安装JupyterLab使用pip安装: pip install jupyterlab# 必须将用户级目录添加 到环境变量才能启动pip install --userbinPATHjupyter la ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 视觉机器学习------K-means算法
K-means(K均值)是基于数据划分的无监督聚类算法. 一.基本原理 聚类算法可以理解为无监督的分类方法,即样本集预先不知所属类别或标签,需要根据样本之间的距离或相似程度自动进行分类.聚 ...
- paper 118:计算机视觉、模式识别、机器学习常用牛人主页链接
牛人主页(主页有很多论文代码) Serge Belongie at UC San Diego Antonio Torralba at MIT Alexei Ffros at CMU Ce Liu at ...
- 机器学习&数据挖掘笔记_13(用htk完成简单的孤立词识别)
最近在看图模型中著名的HMM算法,对应的一些理论公式也能看懂个大概,就是不太明白怎样在一个具体的机器学习问题(比如分类,回归)中使用HMM,特别是一些有关状态变量.观察变量和实际问题中变量的对应关系, ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- 使用 PM2 管理nodejs进程
pm2 是一个带有负载均衡功能的Node应用的进程管理器. 当你要把你的独立代码利用全部的服务器上的所有CPU,并保证进程永远都活着,0秒的重载, PM2是完美的. 它非常适合IaaS结构,但不要把它 ...
- 使用路径arc-奥运五环
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head> < ...
- Splunk Enterprise architecture——转发器本质上是日志收集client附加负载均衡,indexer是分布式索引,外加一个集中式管理协调的中心节点
Splunk Enterprise architecture and processes This topic discusses the internal architecture and proc ...
- Hash索引和BTree索引
索引是帮助mysql获取数据的数据结构.最常见的索引是Btree索引和Hash索引. 不同的引擎对于索引有不同的支持:Innodb和MyISAM默认的索引是Btree索引:而Mermory默认的索引是 ...
- 获取URL中的链接(可中文也可英文)
//既能获取中文url也能英文function getUrlParam(key) { // 获取参数 var url = window.location.search; // 正则筛选地址栏 var ...
- ehlib 如何用代码,选中checkbox呢?
TDBGridEh = class(TCustomDBGridEh) public property Col; property Row; property Canvas; // property G ...
- MyEclipse移动开发教程:设置所需配置的iOS应用(二)
MyEclipse个人授权 折扣低至冰点!立即开抢>> [MyEclipse最新版下载] 二.创建一个数字证书和私钥 2.2 生成证书签名请求和私钥文件 第一步是使用数字签名实用程序创建证 ...
- xxx/labelKeypoint/utils/qt.py:81: RuntimeWarning: invalid value encountered in double_scalars
原代码: return np.linalg.norm(np.cross(p2 - p1, p1 - p3)) / np.linalg.norm(p2 - p1) 出现报错: xxx/labelKeyp ...
- 【ssm】拦截器的原理及实现
一.背景: 走过了双11,我们又迎来了黑色星期五,刚过了黑五,双12又将到来.不管剁手的没有剁手的,估计这次都要剁手了!虽然作为程序猿的我,没有钱但是我们长眼睛了,我们关注到的是我们天猫.淘宝.支付宝 ...
- NVIDIA GeForce GTX 960 设备是不可移动的,无法弹出
系统环境 系统:win7_x64; matlab版本:matlab2017b试用版: GPU:NVIDIA GeForce GTX 960: 问题描述: 第一次使用深度学习实现代码,运行的是matla ...