Rethinking the inception architecture for computer vision的 paper 相关知识
这一篇论文很不错,也很有价值;它重新思考了googLeNet的网络结构--Inception architecture,在此基础上提出了新的改进方法;
文章的一个主导目的就是:充分有效地利用computation;
第一部分: 文章提出了四个principles:
原则1:设计网络的时候需要避免 representational bottlenecks; 什么意思呢? 文章中说: 层与层之间进行 information 传递时,要避免这个过程中的数据的extreme compression,也就是说,数据的 scale 不能减小的太快;(数据从输入到输出大致是减少的,这个变化过程一定要gently,而不是快速的, 一定是慢慢的变少。。。。。。) 当数据的维数extreme下降的时候,就相当于引入了 representational bottelneck.
原则2:没有怎么看明白什么意思啊?复制过来。Higher dimensional representations are easier to process locally within a network. Increasing the activations per tile in a convolutional network allows for more
disentangled features. The resulting networks will train faster. (可以结合 figure7 下面的注释, 我感觉: 在高维表示时,对于局部的特征更容易处理,意思就是local 卷积,用1*1啦, 或3*3, 别用太大的)
原则3: spatial aggregation can be done over lower dimensional embedding without much or any loss in representational power. 直接翻译真的不会翻译啊
原则4: 应该均衡网络的宽度与深度;
第二部分:网络的改进方法:
基于以上原则,开始对网络进行改进了。
1. 把大的卷积层分解为小的卷积层,提高计算效率:
第一种:可以把一个5*5的卷积卷积层分解成两个 3*3 的卷积层。 一个细节就是:把底层的 filters 为m 时, 上层的filters 为 n 时,这时两层的小的卷积层的每一个filters 为多少呢? 细节2: 当原来的 激活函数为线性激活函数时,现在变为两层的激活函数如何选择?(文中说明了全部使用 relu 激活函数会好一些)
2. 非对称分解:
把一个 n*n 的卷积层分解为两个 1*N 和 N*1 的卷积层; (文中说了这种分解在网络的开始几层效果垃圾, but is gives very good result on medium grid-sizes)
3. auxiliary classifiers 分类器的真正作用
文章都过实验发现 辅助分类器的真正作用为:regularizer。 意思就是吧,这个辅助分类器并不会加快网络的训练,不会加快 low-level 特征的 evlove , 它只会在最后的时候提高了一点 performance. 文章还说了,如果加上 batch-mormalized 效果更好一些,这也说明了 batch-normalized 也算一种 regularizer吧。
4. 有效的 grid-size 的reduction 的方法 ,即减少 feature map 的size 的方法:
文中出发点:1 ,避免 representational bottleneck ,其实我理解的就是避免 data的 dimension 急剧下降,一定也慢慢的来,别太快了; 2, 提高计算效率;
下图中的两种方法不满足条件:(左边不满足条件1, 右边不满足条件2)
下图的方法为论文中提出来的:
5. Label smoothing Regularization 方法:
这里要涉及到了一些计算过程,用语言说明一下:网络采用softmax分类器以及交叉熵函数作为loss函数时,对于类别 K 的最上层的导数等于:网络实际输出的 类别 K 的后验概率 - 真实的类别 K的后验概率; 而真实的类别 K的后验概率 要么为1,要么为0. 这个容易出一个问题: 1,过拟合,为什么呢?这样会使促使 网络去学习 的实际输出的 类别 K 的后验概率为 1 或0 ,it is not guaranteed to generalize; 2, 这个也限制了导数的变化, 因为吧, 容易上层数为0 啊。。( 自己推导好好理解一下)
所以呢,文中提出了一个方法: 真实的类别 K的后验概率别这个confident (要么为1 要么为0,不好,虽然后验概率就是这样的), 然后引入了:
其中的u(k)是自己引入的, 文章用了均匀分布; 另外文章也建议了使用训练样本中的 k 的分布来表示 u(k), 其实吧,训练样本中的每一个类别的样本可能差不多相同吧,所以呢,用均匀分布也挺合适的;
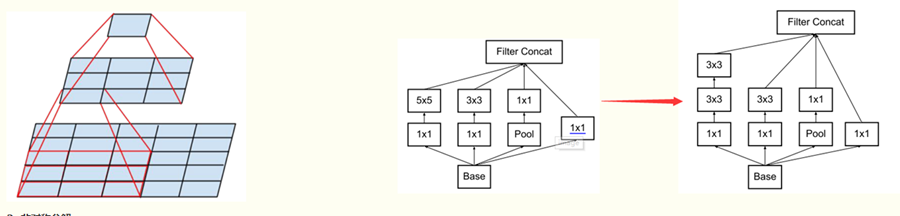
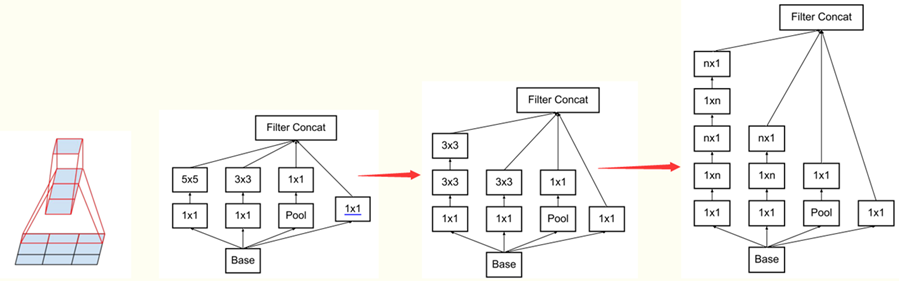
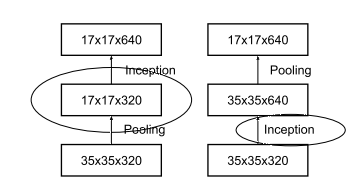
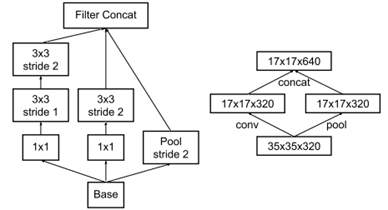
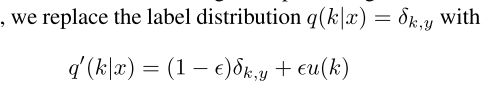
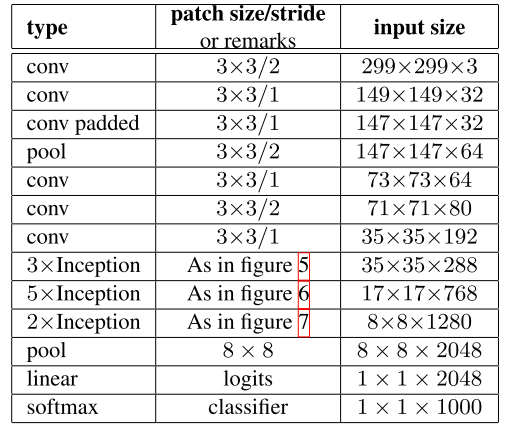
第三部分: Inception V-2网络;
第四部分:训练方法:
看看,参考文献很好;
第五部分:如何处理 small object的分类问题?
由于 object 比较小,所以呢, 像素少, 分辨率低,怎么办?
文中呢,通过试验说明了在计算力相同的情况下,不同的分辨率的输入的效果其实差不多的。
所以呢,当输入的分辨率低时,适当地调节网络的前几层,来保证 computational cost 相同 ,这样的话,最终的 perpormance 其实没有多大的差别的;
第六部分:对比实验:
这一部分对比了其它的实验结果, 注意:Inception-V3.
参考文献:Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 2818-2826.
Rethinking the inception architecture for computer vision的 paper 相关知识的更多相关文章
- inception_v2版本《Rethinking the Inception Architecture for Computer Vision》(转载)
转载链接:https://www.jianshu.com/p/4e5b3e652639 Szegedy在2015年发表了论文Rethinking the Inception Architecture ...
- 图像分类(三)GoogLenet Inception_v3:Rethinking the Inception Architecture for Computer Vision
Inception V3网络(注意,不是module了,而是network,包含多种Inception modules)主要是在V2基础上进行的改进,特点如下: 将滤波器尺寸(Filter Size) ...
- Rethinking the Inception Architecture for Computer Vision
https://arxiv.org/abs/1512.00567 Convolutional networks are at the core of most state-of-the-art com ...
- 【Network architecture】Rethinking the Inception Architecture for Computer Vision(inception-v3)论文解析
目录 0. paper link 1. Overview 2. Four General Design Principles 3. Factorizing Convolutions with Larg ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- (转) WTF is computer vision?
WTF is computer vision? Posted Nov 13, 2016 by Devin Coldewey, Contributor Next Story Someon ...
- Analyzing The Papers Behind Facebook's Computer Vision Approach
Analyzing The Papers Behind Facebook's Computer Vision Approach Introduction You know that company c ...
- 计算机视觉和人工智能的状态:我们已经走得很远了 The state of Computer Vision and AI: we are really, really far away.
The picture above is funny. But for me it is also one of those examples that make me sad about the o ...
- Computer Vision Tutorials from Conferences (3) -- CVPR
CVPR 2013 (http://www.pamitc.org/cvpr13/tutorials.php) Foundations of Spatial SpectroscopyJames Cogg ...
随机推荐
- 转:GestureDetector: GestureDetector 基本使用
Gesture在 ViewGroup中使用 GestureDetector类可以让我们快速的处理手势事件,如点击,滑动等. 使用GestureDetector分三步: 1. 定义GestureDete ...
- Java数据库连接池实现原理
一般来说,Java应用程序访问数据库的过程是: 装载数据库驱动程序: 通过jdbc建立数据库连接: 访问数据库,执行sql语句: 断开数据库连接. public class DBConnection ...
- [CoreOS]CoreOS 实战:CoreOS 及管理工具介绍
转载:http://www.infoq.com/cn/articles/what-is-coreos [编者按]CoreOS是一个基于Docker的轻量级容器化Linux发行版,专为大型数据中心而设计 ...
- LeetCode: Binary Tree Postorder Traversal 解题报告
Binary Tree Postorder Traversal Given a binary tree, return the postorder traversal of its nodes' va ...
- idea Error:(1, 10) java: 需要class, interface或enum, 未结束的字符串文字,Error:(55, 136) java: 非法字符: \65533
1.未结束的字符串文字,Error:(55, 136) java: 非法字符: \65533 这些乱七吧八遭的错误如果很多的话 , 尝试 重新修改下生成目录 修改下语言等级 上述方法都不行 ,还报错 ...
- maven 添加jetty 支持
maven jetty run 即可 配置 <plugin> <groupId>org.mortbay.jetty</groupId> <artifactI ...
- C#学习笔记(20)——使用IComparer(自己写的)
说明(2017-7-25 10:38:37): 1. 参照了上一篇百度文库里的文章. 2. 总结来看,Icomparer就是sort方法的一个参数,用来自定义一个排序规则. 3. 使用方法是,定义一个 ...
- [转]mysql的full join的实现
原文地址:https://blog.csdn.net/qq_1017097573/article/details/52638360 数据库多表查询主要有以下几种 inner join内连接查询,只有两 ...
- [转]java按指定编码写入和读取文件内容的类
读文件: BufferedReader 从字符输入流中读取文本,缓冲各个字符,从而提供字符.数组和行的高效读取. 可以指定缓冲区的大小,或者可使用默认的大小.大多数情况下,默认值就足够大了. 通常,R ...
- ado ole方式访问access的两种方式
OleDbConnection Connection = new OleDbConnection(); OleDbDataAdapter adapter = null; //ConnectiongSt ...