【大数据应用技术】作业九|安装关系型数据库MySQL 安装大数据处理框架Hadoop
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
1.安装MySql
按ctrl+alt+t打开终端窗口,安装mysql需要输入命令:sudo apt-get install mysql-server
输入命令:service mysql start #启动mysql
输入命令:sudo netstat -tap | grep mysql #查看mysql是否启动成功,mysql结点处于LISTEN状态表明启动成功
如下图所示:

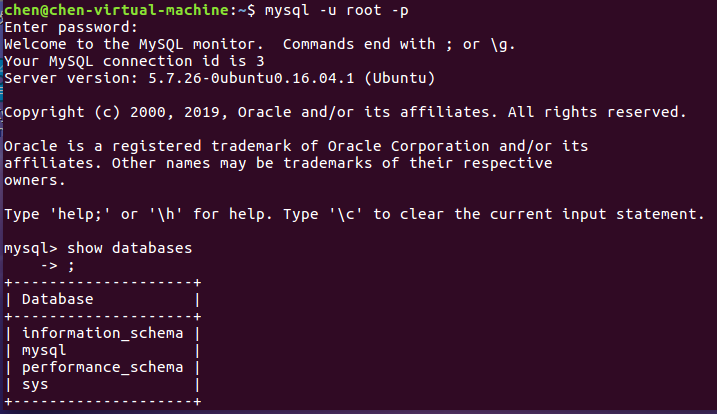
输入命令:mysql -u root -p #进入mysql shell界面
输入命令:show databases; #显示数据库
如下图所示:
2.windows 与 虚拟机互传文件
为了使windows与虚拟机互传文件,所以需要安装vmware tools工具,安装步骤可见后面部分:https://blog.csdn.net/weixin_42305895/article/details/89879220
如图所示,已经成功安装vmware tools工具。
3.安装Hadoop
我已经成功安装了hadoop,伪分布式hadoop的安装教程可见:https://blog.csdn.net/weixin_42305895/article/details/89925119
启动hadoop,如下图所示。
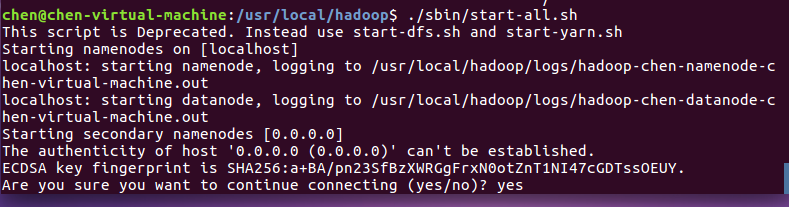
输入jps可查看hadoop是否启动成功,如果启动成功则会出现如下进程:“NameNode”,“DataNode”,“SecondaryNameNode”,如下图所示。

关闭hadoop,如下图所示。

4. 简述Hadoop平台的起源、发展历史与应用现状。
(1)起源
(2)发展历史
(3)应用现状
hadoop的应用现状很广泛,这里我就不一一描述了,大家可以去看国外、国内Hadoop的应用现状,描述的比较详细。
【大数据应用技术】作业九|安装关系型数据库MySQL 安装大数据处理框架Hadoop的更多相关文章
- 安装关系型数据库MySQL和大数据处理框架Hadoop
1. 简述Hadoop平台的起源.发展历史与应用现状.列举发展过程中重要的事件.主要版本.主要厂商:国内外Hadoop应用的典型案例. (1)Hadoop的介绍: Hadoop最早起源于Nutch,N ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 【大数据】安装关系型数据库MySQL安装大数据处理框架Hadoop
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1. 简述Hadoop平台的起源.发展历史与应用现状. 列举发展过 ...
- 【大数据】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.安装Mysql 使用命令 sudo apt-get ins ...
- 安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.Hadoop的介绍 Hadoop最早起源于Nutch.Nut ...
- 作业——09 安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 简述Hadoop平台的起源.发展历史与应用现状. 起源: 2 ...
- AI加持的阿里云飞天大数据平台技术揭秘
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛.资深专家徐晟来为我们分享<AI加持的阿里云飞天大数据平台技术揭秘>.本文主要讲了三大部分,一是原创技术优 ...
- 中国大数据六大技术变迁记(CSDN)
大会召开前期,特别梳理了历届大会亮点以记录中国大数据技术领域发展历程,并立足当下生态圈现状对即将召开的BDTC 2014进行展望: 追本溯源,悉大数据六大技术变迁 伴随着大数据技术大会的发展,我们亲历 ...
- 大数据 --> 大数据关键技术
大数据关键技术 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来源单一,且存 ...
随机推荐
- Bootstrap-实现简单的网站首页
html: <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset=" ...
- Linux内核:关于中断你需要知道的
1.中断处理程序与其他内核函数真正的区别在于,中断处理程序是被内核调用来相应中断的,而它们运行于中断上下文(原子上下文)中,在该上下文中执行的代码不可阻塞.中断就是由硬件打断操作系统. 2.异常与中断 ...
- 【DATAGUARD】物理dg的failover切换(六)
[DATAGUARD]物理dg的failover切换(六) 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你 ...
- Keystore Problem: Cannot convert COMBINED of type class java.lang.String to class org.jivesoftware.openfire.spi.ConnectionType
go to: Server Manager -> System Properties Search for "xmpp.socket.ssl.client.keypass" ...
- Linux 系统安全相关
本篇关于Linux的一些安全知识,主要就是与账号相关的安全. 账户文件锁定 当服务器中的用户账号已经固定,不在进行更改,可锁定账户文件.锁定后,无法添加.删除账号,也无法更改密码等. 锁定账户文件 c ...
- 快速部署ldap服务
快速部署ldap服务 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.LDAP概述 .什么是目录服务 ()目录是一类为了浏览和搜索数据二十几的特殊的数据库,例如:最知名的的微软公 ...
- node基础学习——操作文件系统fs
操作文件系统fs 1.在Node.js中,使用fs模块来实现所有有关文件及目录的创建.写入及删除.在fs模块中,所有对文件及目录的操作都可以使用同步与异步两种方法,具有Sync后缀的方法均为同步方法. ...
- git拉取远程分支并切换到该分支
整理了五种方法,我常用最后一种,这五种方法(除了第4中已经写了fetch的步骤)执行前都需要执行git fetch来同步远程仓库 (1)git checkout -b 本地分支名 origin/远程分 ...
- P1972 [SDOI2009]HH的项链[离线+树状数组/主席树/分块/模拟]
题目背景 无 题目描述 HH 有一串由各种漂亮的贝壳组成的项链.HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义.HH 不断地收集新的贝壳,因此,他的项链 ...
- 2019-2020-1 20199301《Linux内核原理与分析》第八周作业
第七章 可执行程序工作原理 ELF概述: 目标平台:它决定了编译器使用的机器命令集. ABI(目标文件) 目标文件和目标平台是二进制兼容的,即该目标文件已经是适应某一种CPU体系结构的二进制指令. E ...