【大数据应用技术】作业九|安装关系型数据库MySQL 安装大数据处理框架Hadoop
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
1.安装MySql
按ctrl+alt+t打开终端窗口,安装mysql需要输入命令:sudo apt-get install mysql-server
输入命令:service mysql start #启动mysql
输入命令:sudo netstat -tap | grep mysql #查看mysql是否启动成功,mysql结点处于LISTEN状态表明启动成功
如下图所示:

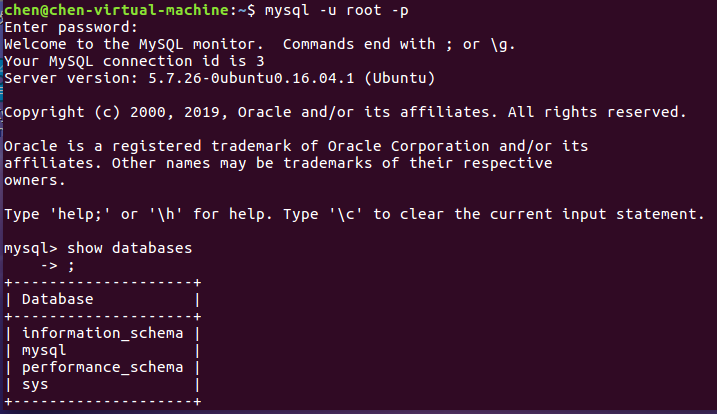
输入命令:mysql -u root -p #进入mysql shell界面
输入命令:show databases; #显示数据库
如下图所示:
2.windows 与 虚拟机互传文件
为了使windows与虚拟机互传文件,所以需要安装vmware tools工具,安装步骤可见后面部分:https://blog.csdn.net/weixin_42305895/article/details/89879220
如图所示,已经成功安装vmware tools工具。
3.安装Hadoop
我已经成功安装了hadoop,伪分布式hadoop的安装教程可见:https://blog.csdn.net/weixin_42305895/article/details/89925119
启动hadoop,如下图所示。
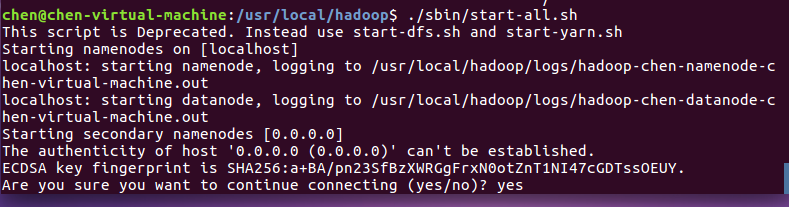
输入jps可查看hadoop是否启动成功,如果启动成功则会出现如下进程:“NameNode”,“DataNode”,“SecondaryNameNode”,如下图所示。

关闭hadoop,如下图所示。

4. 简述Hadoop平台的起源、发展历史与应用现状。
(1)起源
(2)发展历史
(3)应用现状
hadoop的应用现状很广泛,这里我就不一一描述了,大家可以去看国外、国内Hadoop的应用现状,描述的比较详细。
【大数据应用技术】作业九|安装关系型数据库MySQL 安装大数据处理框架Hadoop的更多相关文章
- 安装关系型数据库MySQL和大数据处理框架Hadoop
1. 简述Hadoop平台的起源.发展历史与应用现状.列举发展过程中重要的事件.主要版本.主要厂商:国内外Hadoop应用的典型案例. (1)Hadoop的介绍: Hadoop最早起源于Nutch,N ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 【大数据】安装关系型数据库MySQL安装大数据处理框架Hadoop
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1. 简述Hadoop平台的起源.发展历史与应用现状. 列举发展过 ...
- 【大数据】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.安装Mysql 使用命令 sudo apt-get ins ...
- 安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 1.Hadoop的介绍 Hadoop最早起源于Nutch.Nut ...
- 作业——09 安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 简述Hadoop平台的起源.发展历史与应用现状. 起源: 2 ...
- AI加持的阿里云飞天大数据平台技术揭秘
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛.资深专家徐晟来为我们分享<AI加持的阿里云飞天大数据平台技术揭秘>.本文主要讲了三大部分,一是原创技术优 ...
- 中国大数据六大技术变迁记(CSDN)
大会召开前期,特别梳理了历届大会亮点以记录中国大数据技术领域发展历程,并立足当下生态圈现状对即将召开的BDTC 2014进行展望: 追本溯源,悉大数据六大技术变迁 伴随着大数据技术大会的发展,我们亲历 ...
- 大数据 --> 大数据关键技术
大数据关键技术 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来源单一,且存 ...
随机推荐
- 虚拟Dom详解 - (二)
第一篇文章中主要讲解了虚拟DOM基本实现,简单的回顾一下,虚拟DOM是使用json数据描述的一段虚拟Node节点树,通过render函数生成其真实DOM节点.并添加到其对应的元素容器中.在创建真实DO ...
- angularJs指令的Scope(作用域)
每当一个指令被创建的时候,都会有这样一个选择,是继承自己的父作用域(一般是外部的Controller提供的作用域或者根作用域($rootScope)),还是创建一个新的自己的作用域,当然Angular ...
- react新旧生命周期
React16.3.0之前生命周期 16.3开始建议使用新的生命周期
- cs/bs架构的区别
Client/Server是建立在局域网的基础上的,基于客户端/服务器,安全,响应快,维护难度大,不易拓展,用户面固定,需要相同的操作系统. Browser/Server是建立在广域网的基础上的,基于 ...
- SolarWinds-改变端口
Solarwinds配置文件,修改为80端口(默认为8123) C:\Program Files\SolarWinds\DPA\iwc\tomcat\conf\server.xml
- Python面向对象三要素-封装(Encapsulation)
Python面向对象三要素-封装(Encapsulation) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.封装概述 将数据和操作组织到类中,即属性和方法 将数据隐藏起来,给 ...
- linux卸载mysql误删mysql.pm
操作步骤如下 linux卸载mysql:yum remove mysql 查找mysql所有的文件并删除: 查找:find / -name mysql 删除:rm -rf xxx 误操作删除mysql ...
- python学习之多窗口切换
多窗口切换: from selenium import webdriver d = webdriver.Firefox() d.window_handles #显示所有的窗口 d.current_wi ...
- 使用 xpath helper 提取网页链接
需求是这样的,公司某个部门不会爬虫,不懂任何技术性的东西,但是希望去提取网页的一个分享链接,老大要求去开发谷歌浏览器插件,但一时半会也搞不定这个啊, 想到用 xpath helper 作为一个临时的替 ...
- hak的使用
autohotkey简称ahk 它是一款轻量级的脚本语言文件,它可以干任何事情,如做dnf的连发脚本,类似按键精灵的自动化点击,按键自动打开文件一系列事情,文件需要按照ahk自己的语言,实现自定义的脚 ...