Real-time ‘Actor-Critic’ Tracking
Real-time ‘Actor-Critic’ Tracking
2019-07-15 10:49:16
Code: https://github.com/bychen515/ACT
1. Background and Motivation:
本文提出一种利用 “连续” 动作空间的强化学习算法来进行跟踪。之前的 MDNET 是随机采样,然后进行打分的;而 ADNet 是 “离散”的动作选择,即:通过一系列离散的动作选择,实现 BBox 的移动,来完成跟踪。下图展示了本文方法与这两种方法的不同:

本文的贡献点在于:
1). 该算法是首次探索了连续的动作 (continuous actions) 进行跟踪,仅通过 Actor model 进行一次动作选择,即可完成动作的定位;
2). 该算法也是首次利用 “Actor-Critic” 跟踪框架。
3). 在速度达到实时的同时,精度也比不错。
2. Tracking via the "Actor-Critic" Network:
2.1 Problem Settings:
本文将跟踪问题看做是序列决策问题(Decision-making problem)。基础的马尔科夫决策过程包括如下几个元素:State,Action,State transition functions,Reward。
在本文中,tracker 被当做是 agent,并且来预测每一帧目标物体的准确位置。该智能体与环境进行交互,通过观察 s,执行动作 a,并且得到奖励 r。在第 t 帧中,智能体根据当前的状态 s,给出了连续的动作 a,得到了跟踪结果 s'。动作 a 被定义为:the relative motion of the tracked object,表明在当前帧,应该怎么直接移动 BBOX。与 ADNET 不同的是,该算法仅仅执行一个连续的动作,来定位目标物体,使得该算法更加高效。具体各个元素的定义如下:
State:
在该工作中,作者定义状态 s 为:在BBox内部的观察到的图像块。给定视频帧 F 和 BBox b = [x, y, h, w],作者首先用预处理函数 s 来处理得到该图像块。
Action and State Transition:
为了进行连续的控制,动作空间被假设为连续的,即:如何直接移动该 BBox。此处,作者用 $a = [\Delta x, \Delta y, \Delta s]$ 来描绘跟踪物体的相对运动,$\Delta x, \Delta y$ 表明了物体水平和竖直方向的变换,$\Delta s$ 表明了尺寸的相对变换。考虑到跟踪物体时序上的连续性,作者加了如下的约束来控制 BBox 的变化幅度:$-1 <= \Delta x <= 1, -1 <= \Delta y <= 1, -0.05 <= \Delta s <= 0.05$。通过对上一帧的 BBox 进行这样动作的变换,可以得到一个新的 BBox b' = [x' y' h' w']:
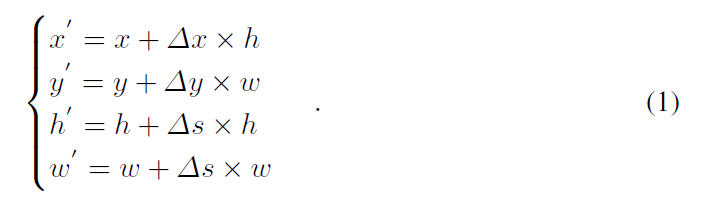
然后,状态转移过程 $s' = f(s, a)$ 可以隐式的通过预处理函数来实现。
Reward:
奖励函数 r(s, a) 描述了定位的准确性,所以,其可以按照重合度的方法进行度量:
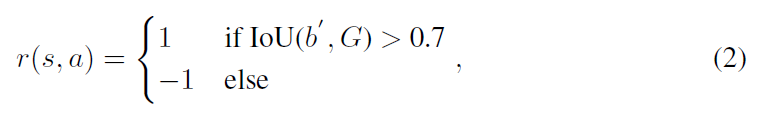
每次执行一个 action,都会产生一个奖励,然后被用于离线训练的深度网络更新 (to update the deep networks in offline learning)。
2.2 Offline Training:
Network Architecture:
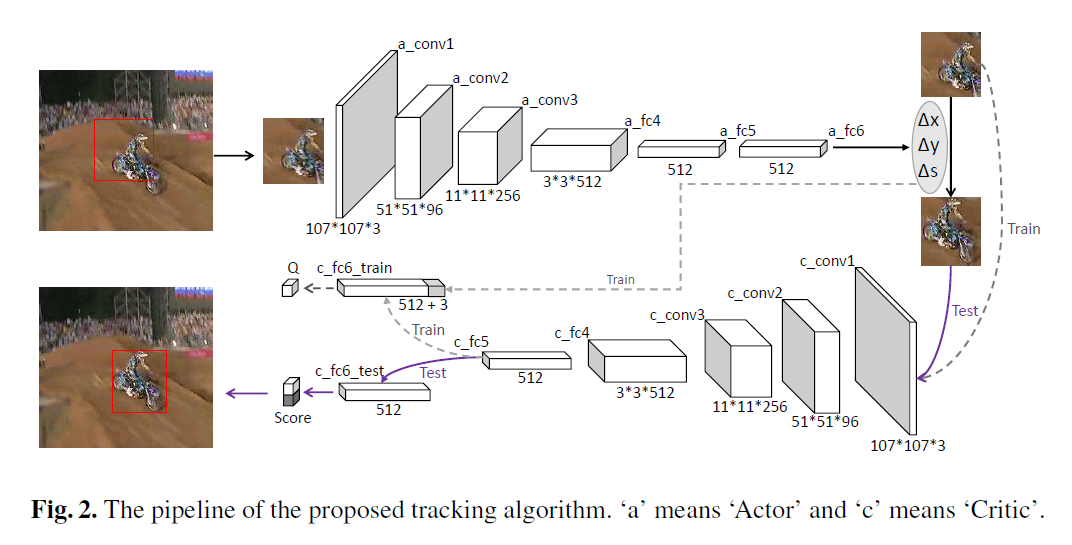
本文的网络结构如上图所示。可以看到 Actor network 是将上一帧的跟踪结果的 image patch 作为输入,输出是三维的数字,即对应了 水平,竖直 和 尺寸上的变换。在 offline training中,还有一个是 Critic network,该网络的结构跟 Actor 类似,但是用途是不同的。该网络要求的输入是:根据当前的状态,将三维 action vector 组合后的结果,以得到 Q-value,并用于动作的评价。
Training via DDPG:
本文采用 DDPG 方法来训练该 “Actor-Critic Network”,核心的思想是:迭代的训练 “Critic” 和 “Actor” 模型。给定 N 个经验 (si, ai, ri, si'),Critic model 可以利用贝尔曼方程来进行学习。通过目标网络,学习可以通过最小化下面的损失来实现:
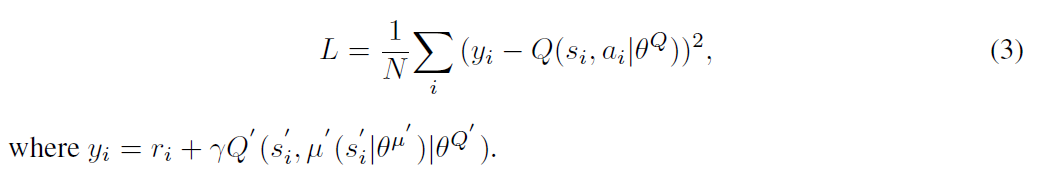
然后,Actor 模型可以通过链式法则进行更新:
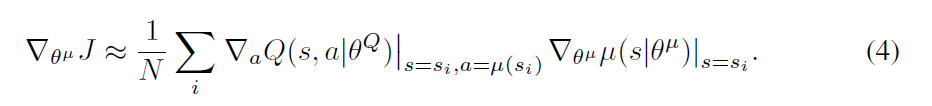
在训练迭代中,作者随机的选择一个训练序列及其 GT。在此之后,作者将跟踪器在选择的序列上得到了训练 pair (st, at, rt, st') 。

Experimental Results:
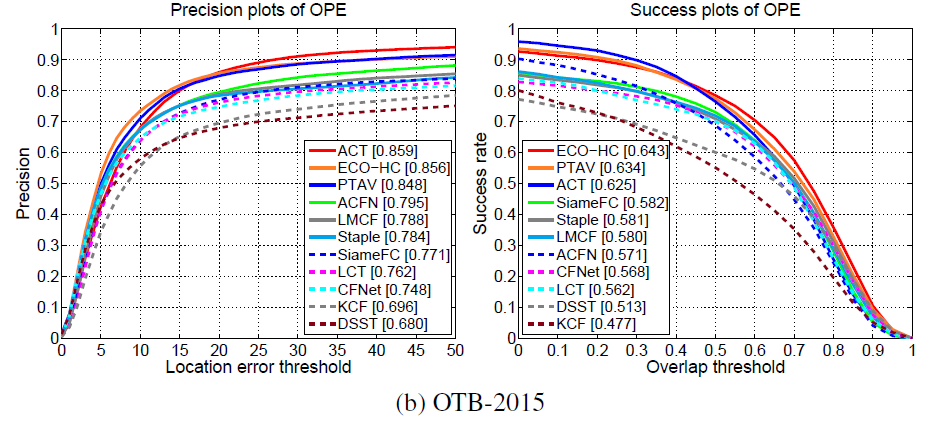
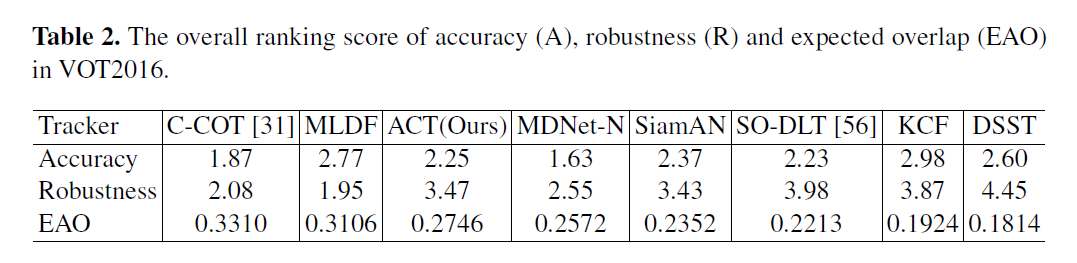
==
Real-time ‘Actor-Critic’ Tracking的更多相关文章
- 深度增强学习--Actor Critic
Actor Critic value-based和policy-based的结合 实例代码 import sys import gym import pylab import numpy as np ...
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor 20 ...
- TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- DRL 教程 | 如何保持运动小车上的旗杆屹立不倒?TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- Awesome TensorFlow
Awesome TensorFlow A curated list of awesome TensorFlow experiments, libraries, and projects. Inspi ...
- (转) Using the latest advancements in AI to predict stock market movements
Using the latest advancements in AI to predict stock market movements 2019-01-13 21:31:18 This blog ...
- 学习笔记TF053:循环神经网络,TensorFlow Model Zoo,强化学习,深度森林,深度学习艺术
循环神经网络.https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/re ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 强化学习--Actor-Critic---tensorflow实现
完整代码:https://github.com/zle1992/Reinforcement_Learning_Game Policy Gradient 可以直接预测出动作,也可以预测连续动作,但是无 ...
- 论文笔记:Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments 2017-10-25 16:38:23 [Proj ...
随机推荐
- C#对MongDB取数据的常用代码
1.使用聚合取最新的实时数据(每一个测站有多条数据,取日期最新的数据.也就是每个测站取最新的值) var group = new BsonDocument { {"_id",new ...
- PHP生成小程序二维码
/** * [生成小程序二维码] * @return [type] [description] */ public function makeMiniQrcode_do() { begin: $id ...
- centos 宝塔 使用命令行快速导入数据库sql
先将sql文件上传到服务器,例如上传到www文件夹 然后打开命令行工具 输入 mysql -u 数据库用户名 -p 然后复制密码进去 然后输入 use 数据库名 回车 然后输入 source /www ...
- PCB Layout设计规范——PCB布线与布局
1.PCB布线与布局隔离准则:强弱电流隔离.大小电压隔离,高低频率隔离.输入输出隔离,分界标准为相差一个数量级.隔离方法包括:空间远离.地线隔开. 2. 晶振要尽量靠近IC,且布线要较粗 ...
- go语言笔记1
Go语言学习整理 本文基于菜鸟教程,对于自己不明白的点加了点个人注解,对于已明确的点做了删除,可能结构不太清晰,看官们可移步Go语言教程 1 Go语言结构当标识符(包括常量.变量.类型.函数名. ...
- Four subspaces - Prof. Strang
相应地,用映射的观点考察映射σ的kernal space与image space,得到的就是下面这张图啦 Ref: Introduction to Linear Algebra 5th Edition ...
- PAT甲级1002水题飘过
#include<iostream> #include<string.h> using namespace std; ]; int main(){ int n1, n2; wh ...
- 项目Alpha冲刺--10/10
项目Alpha冲刺--10/10 作业要求 这个作业属于哪个课程 软件工程1916-W(福州大学) 这个作业要求在哪里 项目Alpha冲刺 团队名称 基于云的胜利冲锋队 项目名称 云评:高校学生成绩综 ...
- django-列表分页和排序
视图函数views.py # 种类id 页码 排序方式 # restful api -> 请求一种资源 # /list?type_id=种类id&page=页码&sort=排序方 ...
- Open Source Isn't A Business Model, It's A Market Strategy
https://www.forbes.com/sites/quora/2017/09/29/open-source-isnt-a-business-model-its-a-market-strateg ...