企业搜索引擎开发之连接器connector(二十四)
本人在上文中提到,连接器实现了两种事件依赖的机制 ,其一是我们手动操作连接器实例时;其二是由连接器的自动更新机制
上文中分析了连接器的自动更新机制,即定时器执行定时任务
那么,如果我们手动操作连接器实例时,是怎么发出事件更新连接器实例的呢
通过eclipse开发工具,追踪调用ChangeDetector接口的detect()方法的方法
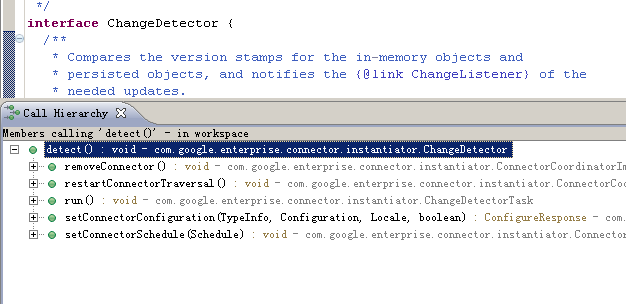
ChangeDetectorTask类的run方法里面调用我们再上文中已经分析了,其他方法便是ConnectorCoordinatorImpl实例对象的方法
即ConnectorCoordinatorImpl实例对象的如下方法,分别调用了ChangeDetector接口的detect()方法
/**
* 移除连接器实例
* Removes this {@link Connector} instance. Halts traversals,
* removes the Connector instance from the known connectors,
* and removes the Connector's on-disk representation.
*/
/* @Override */
public void removeConnector() {
synchronized(this) {
resetBatch();
if (instanceInfo != null) {
instanceInfo.removeConnector();
}
}
// This must not be called while holding the lock.
changeDetector.detect();
} /**
* 重启遍历
* Retraverses the {@link Connector}'s content from scratch.
* Halts any traversal in progress and removes any saved traversal state,
* forcing the Connector to retraverse the Repository from its start.
*/
/* @Override */
public void restartConnectorTraversal() throws ConnectorNotFoundException {
// To avoid deadlock, this method calls InstanceInfo's getters and setters,
// rather than the local ones.
synchronized(this) {
resetBatch(); // Halt any traversal.
getInstanceInfo().setConnectorState(null); // Discard the checkpoint. // If Schedule was 'run-once', re-enable it to run again. But watch out -
// empty disabled Schedules could look a bit like a run-once Schedule.
Schedule schedule = getInstanceInfo().getConnectorSchedule();
if (schedule != null && schedule.isDisabled() &&
schedule.getRetryDelayMillis() == -1 &&
schedule.nextScheduledInterval() != -1) {
schedule.setDisabled(false);
getInstanceInfo().setConnectorSchedule(schedule);
}
} // TODO: Remove this if we switch completely to JDBC PersistentStore.
// FileStore doesn't notice the deletion of a file that did not exist.
if (lister != null) {
connectorCheckpointChanged(null);
} // This must not be called while holding the lock.
changeDetector.detect();
} /**
* 设置配置信息
* Sets the {@link Configuration} for this {@link ConnectorCoordinator}.
* If this {@link ConnectorCoordinator} supports persistence this will
* persist the new Configuration.
*/
/* @Override */
public ConfigureResponse setConnectorConfiguration(TypeInfo newTypeInfo,
Configuration configuration, Locale locale, boolean update)
throws ConnectorNotFoundException, ConnectorExistsException,
InstantiatorException {
LOGGER.info("Configuring connector " + name);
String typeName = newTypeInfo.getConnectorTypeName();
Preconditions.checkArgument(typeName.equals(configuration.getTypeName()),
"TypeInfo must match Configuration type");
ConfigureResponse response = null;
synchronized(this) {
resetBatch();
if (instanceInfo != null) {
if (!update) {
throw new ConnectorExistsException();
}
if (typeName.equals(typeInfo.getConnectorTypeName())) {
configuration =
new Configuration(configuration, getConnectorConfiguration());
response = resetConfig(instanceInfo.getConnectorDir(), typeInfo,
configuration, locale);
} else {
// An existing connector is being given a new type - drop then add.
// TODO: This shouldn't be called from within the synchronized block
// because it will kick the change detector.
removeConnector();
response = createNewConnector(newTypeInfo, configuration, locale);
if (response != null) {
// TODO: We need to restore original Connector config. This is
// necessary once we allow update a Connector with new ConnectorType.
// However, when doing so consider: createNewConnector could have
// thrown InstantiatorException as well. Also, you need to kick
// the changeDetector (but not in this synchronized block).
LOGGER.severe("Failed to update Connector configuration.");
// + " Restoring original Connector configuration.");
}
}
} else {
if (update) {
throw new ConnectorNotFoundException();
}
response = createNewConnector(newTypeInfo, configuration, locale);
}
}
if (response == null) {
// This must not be called while holding the lock.
changeDetector.detect();
} else {
return new ExtendedConfigureResponse(response, configuration.getXml());
}
return response;
} /**
* 设置定时调度
* Sets the traversal {@link Schedule} for the {@link Connector}.
*
* @param connectorSchedule Schedule to store or null to unset any existing
* Schedule.
* @throws ConnectorNotFoundException if the connector is not found
*/
/* @Override */
public void setConnectorSchedule(Schedule connectorSchedule)
throws ConnectorNotFoundException {
synchronized(this) {
// Persistently store the new schedule.
getInstanceInfo().setConnectorSchedule(connectorSchedule);
}
// This must not be called while holding the lock.
changeDetector.detect();
}
接下来ChangeDetector接口的detect()方法其实又调用了自身的实现ConnectorCoordinatorImpl实例对象的实现ChangeHandler接口的方法
ConnectorCoordinatorImpl-->ChangeDetector的detect()-->ChangeListener的相关方法-->ChangeHandler(ConnectorCoordinatorImpl实例对象)的相关方法
所以手动操作与自动更新机制实际上是殊途同归,最后都是调用了ChangeHandler(ConnectorCoordinatorImpl实例对象)的相关方法
---------------------------------------------------------------------------
本系列企业搜索引擎开发之连接器connector系本人原创
转载请注明出处 博客园 刺猬的温驯
本人邮箱: chenying998179@163#com (#改为.)
本文链接 http://www.cnblogs.com/chenying99/p/3776515.html
企业搜索引擎开发之连接器connector(二十四)的更多相关文章
- 企业搜索引擎开发之连接器connector(十九)
连接器是基于http协议通过推模式(push)向数据接收服务端推送数据,即xmlfeed格式数据(xml格式),其发送数据接口命名为Pusher Pusher接口定义了与发送数据相关的方法 publi ...
- 企业搜索引擎开发之连接器connector(十八)
创建并启动连接器实例之后,连接器就会基于Http协议向指定的数据接收服务器发送xmlfeed格式数据,我们可以通过配置http代理服务器抓取当前基于http协议格式的数据(或者也可以通过其他网络抓包工 ...
- 企业搜索引擎开发之连接器connector(十六)
本人有一段时间没有接触企业搜索引擎之连接器的开发了,连接器是涉及企业搜索引擎一个重要的组件,在数据源与企业搜索引擎中间起一个桥梁的作用,类似于数据库之JDBC,通过连接器将不同数据源的数据适配到企业搜 ...
- 企业搜索引擎开发之连接器connector(二十九)
在哪里调用监控器管理对象snapshotRepositoryMonitorManager的start方法及stop方法,然后又在哪里调用CheckpointAndChangeQueue对象的resum ...
- 企业搜索引擎开发之连接器connector(二十八)
通常一个SnapshotRepository仓库对象对应一个DocumentSnapshotRepositoryMonitor监视器对象,同时也对应一个快照存储器对象,它们的关联是通过监视器管理对象D ...
- 企业搜索引擎开发之连接器connector(二十六)
连接器通过监视器对象DocumentSnapshotRepositoryMonitor从上文提到的仓库对象SnapshotRepository(数据库仓库为DBSnapshotRepository)中 ...
- 企业搜索引擎开发之连接器connector(二十五)
下面开始具体分析连接器是怎么与连接器实例交互的,这里主要是分析连接器怎么从连接器实例获取数据的(前面文章有涉及基于http协议与连接器的xml格式的交互,连接器对连接器实例的设置都是通过配置文件操作的 ...
- 企业搜索引擎开发之连接器connector(二十二)
下面来分析线程执行类,线程池ThreadPool类 对该类的理解需要对java的线程池比较熟悉 该类引用了一个内部类 /** * The lazily constructed LazyThreadPo ...
- 企业搜索引擎开发之连接器connector(二十)
连接器里面衔接数据源与数据推送对象的是QueryTraverser类对象,该类实现了Traverser接口 /** * Interface presented by a Traverser. Used ...
随机推荐
- Data_Structure03-栈和队列
一.学习总结 1.写出你认为本周学习中比较重要的知识点关键词 ·抽象数据类型 ·栈和队列 2.思维导图 二.PTA实验作业 选题: 1.7-1 jmu-字符串是否对称(20 分) 2.7-4(选做) ...
- Spark在Windows下的环境搭建
本文转载自:http://blog.csdn.net/u011513853/article/details/52865076 由于Spark是用Scala来写的,所以Spark对Scala肯定是原生态 ...
- struts1的一个简单登陆功能
Login.jsp: <form action="<%= request.getContextPath() %>/login.do" method="p ...
- canvas合成和裁剪
canvas合成和裁剪 属性 globalCompositeOperation=type 设置覆盖类型 source-over 源覆盖在目标上 source-in 源覆盖在目标上的公共部分(只取源图形 ...
- 学习了django对于sqlite3进行了了解,谈谈看法
学习了django对于sqlite3进行了了解,谈谈看法 由于django默认使用的是sqlite3,写了几个建表语句, 然后数据做下迁移,其实就是建表语句的执行. 一直对sqlite3没有一个直观的 ...
- 好记性不如烂笔头-linux学习笔记2kickstart自动化安装和cacti
kickstart自动化安装的逻辑梳理 主要是安装tftp nfs dhcp 然后配置kickstart 原来就是先安装tftp 可实现不同机器的文件下载 然后在安装nfs 就是主服务器的文件系统 然 ...
- WPF DataGrid实现分页显示
主要代码如下 /// <summary> /// 读取指定页面的数据 /// </summary> /// <param name="pagePerCount& ...
- mybatis 需要注意的点 MyBatis 插入空值时,需要指定JdbcType (201
转自:https://blog.csdn.net/snakemoving/article/details/76052875 前天遇到一个问题 异常显示如下: 引用 Exception in threa ...
- 深入了解 JPA
转载自:http://www.cnblogs.com/crawl/p/7703679.html 前言:谈起操作数据库,大致可以分为几个阶段:首先是 JDBC 阶段,初学 JDBC 可能会使用原生的 J ...
- 可视化库-Matplotlib-盒图(第四天)
盒图由五个数值点组成,最小观测值,下四分位数,中位数,上四分位数,最大观测值 IQR = Q3 - Q1 Q3表示上四分位数, Q1表示下四分位数,IQR表示盒图的长度 最小观测值 min =Q1 ...