LevelDB Cache机制
【LevelDB Cache机制】
对于levelDb来说,读取操作如果没有在内存的memtable中找到记录,要多次进行磁盘访问操作。假设最优情况,即第一次就在level 0中最新的文件中找到了这个key,那么也需要读取2次磁盘,一次是将SSTable的文件中的index部分读入内存,这样根据这个index可以确定key是在哪个block中存储;第二次是读入这个block的内容,然后在内存中查找key对应的value。
levelDb中引入了两个不同的Cache:Table Cache和Block Cache。其中Block Cache是配置可选的,即在配置文件中指定是否打开这个功能。
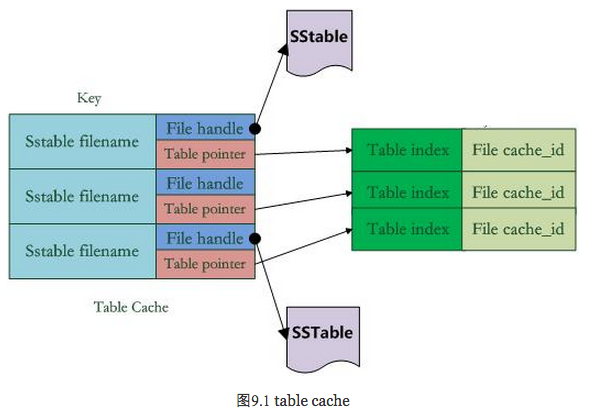
图9.1是table cache的结构。在Cache中,key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个是指向内存中这个SSTable文件对应的Table结构指针,table结构在内存中,保存了SSTable的index内容以及用来指示block cache用的cache_id ,当然除此外还有其它一些内容。
比如在get(key)读取操作中,如果levelDb确定了key在某个level下某个文件A的key range范围内,那么需要判断是不是文件A真的包含这个KV。此时,levelDb会首先查找Table Cache,看这个文件是否在缓存里,如果找到了,那么根据index部分就可以查找是哪个block包含这个key。如果没有在缓存中找到文件,那么打开SSTable文件,将其index部分读入内存,然后插入Cache里面,去index里面定位哪个block包含这个Key 。如果确定了文件哪个block包含这个key,那么需要读入block内容,这是第二次读取。
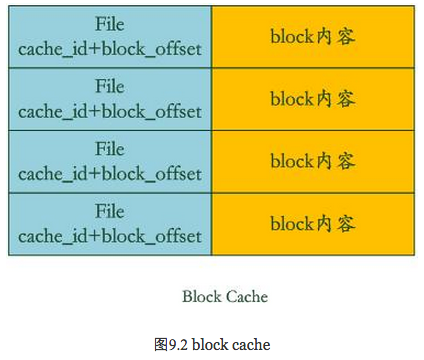
Block Cache是为了加快这个过程的,图9.2是其结构示意图。其中的key是文件的cache_id加上这个block在文件中的起始位置block_offset。而value则是这个Block的内容。
如果levelDb发现这个block在block cache中,那么可以避免读取数据,直接在cache里的block内容里面查找key的value就行,如果没找到呢?那么读入block内容并把它插入block cache中。levelDb就是这样通过两个cache来加快读取速度的。从这里可以看出,如果读取的数据局部性比较好,也就是说要读的数据大部分在cache里面都能读到,那么读取效率应该还是很高的,而如果是对key进行顺序读取效率也应该不错,因为一次读入后可以多次被复用。但是如果是随机读取,您可以推断下其效率如何。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
LevelDB Cache机制的更多相关文章
- LevelDB Cache实现机制分析
几天前淘宝量子恒道在博客上分析了HBase的Cache机制,本篇文章,结合LevelDB 1.7.0版本的源码,分析下LevelDB的Cache机制. 概述 LevelDB是Google开源的持久化K ...
- jQuery的XX如何实现?——3.data与cache机制
往期回顾: jQuery的XX如何实现?——1.框架 jQuery的XX如何实现?——2.show与链式调用 -------------------------- 源码链接:内附实例代码 jQuery ...
- 受教了,memcache比较全面点的介绍,受益匪浅,适用memcached的业务场景有哪些?memcached的cache机制是怎样的?在设计应用时,可以通过Memcached缓存那些内容?
基本问题 1.memcached的基本设置 1)启动Memcache的服务器端 # /usr/local/bin/memcached -d -m 10 -u root -l 192.168.0.200 ...
- [转帖]CPU Cache 机制以及 Cache miss
CPU Cache 机制以及 Cache miss https://www.cnblogs.com/jokerjason/p/10711022.html CPU体系结构之cache小结 1.What ...
- 艺多不压身 -- 常用缓存Cache机制的实现
常用缓存Cache机制的实现 缓存,就是将程序或系统经常要调用的对象存在内存中,以便其使用时可以快速调用,不必再去创建新的重复的实例. 这样做可以减少系统开销,提高系统效率. 缓存主要可分为二大类: ...
- Java中各类Cache机制实现解决方案[来自CSDN]
摘要:在Java中,不同的类都有自己单独的Cache机制,实现的方法也可能有所不同,文章列举了Java中常见的各类Cache机制的实现方法,同时进行了综合的比较. 在Java中,不同的类都有自己单独的 ...
- Linux内存管理Swap和Buffer Cache机制
Linux内存管理Swap和Buffer Cache机制 一个完整的Linux系统主要有存储管理,内存管理,文件系统和进程管理等几方面组成,贴出一些以前学习过的一个很好的文章.与大家共享!以下主要说明 ...
- LevelDB Cache
[LevelDB Cache] The contents of the database are stored in a set of files in the filesystem and each ...
- docker build 的 cache 机制
cache 机制注意事项 可以说,cache 机制很大程度上做到了镜像的复用,降低存储空间的同时,还大大缩短了构建时间.然而,不得不说的是,想要用好 cache 机制,那就必须了解利用 cache 机 ...
随机推荐
- PHP Startup: Unable to load dynamic library '/usr/lib64/php/modules/phalcon.so' - /usr/lib64/php/mod
这个警告可能是,扩展在php.d里面加载了一遍,然后又在php.ini里写了一遍导致的
- 利用 Create React Native App 快速创建 React Native 应用
本文介绍的 Create-React-Native-App 是非常 Awesome 的工具,而其背后的 Expo 整个平台也让笔者感觉非常的不错.笔者目前公司是采用 APICloud 进行移动应用开发 ...
- IO综合练习--文件切割和文件合并
有时候一个视频文件或系统文件太大了,上传和下载可能会受到限制,这时可以用文件切割器把文件按大小切分为文件碎片, 等到要使用这个文件了,再把文件碎片合并成原来的文件即可.下面的代码实现了文件切割和文件合 ...
- salesforce linghtning component 自动添加标准style css样式
Your app automatically gets Lightning Design System styles if it extends force:slds <aura:applic ...
- 使用nginx-vod-module hls &&dash &&Thumbnail 处理
备注: 以前写过使用ffmpeg 转换为m3u8进行hls 视频处理,实际上有一个开源的很强大的工具,我们基本不用什么代码就可以实现hls. dash.Thumbnail ,很强大 安装 使用源码 ...
- Oracle按时间段分组统计
想要按时间段分组查询,首先要了解level,connect by,oracle时间的加减. 关于level这里不多说,我只写出一个查询语句: ----level 是一个伪例 ---结果: 关于conn ...
- ffmpeg C++程序编译时报__cxa_end_catch错误
解决方法在编译sh中加上 -lsupc++ 即可. 2.STL模块函数找不到,链接失败stdc++/include/bits/stl_list.h:466: error: undefined refe ...
- const T & 的适用范围
我们往往在类中的函数体,重载操作中看到 const T & 的影子,以前还是比较纳闷. 对于非内部数据类型的参数而言,象void Func(A a) 这样声明的函数注定效率比较底.因为函数体内 ...
- 基数排序算法-python实现
#-*- coding: UTF-8 -*- import numpy as np def RadixSort(a): i = 0 #初始为个位排序 n = 1 #最小的位数置为1(包含0) max ...
- Ubuntu 16.04 natural scrolling
http://ubuntuhandbook.org/index.php/2016/05/install-ubuntu-tweak-in-ubuntu-16-04/ download ubuntu-tw ...