VictoriaMetrics源码阅读:极端吝啬,vm序列化数据到磁盘的细节
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢!

背景
- VM使用SSTable(Sorted string table)来存储索引中的所有key。
- 各种类型的索引会被序列化到一个[]byte数组中,每一条数据相当于可以用于索引的key.
- key会被顺序追加到一个64KB的inmemoryBlock中。
- 有N个核就会分配N个内存存储桶。例如16核就会是16个桶。
- 每个桶下面有很多个inmemoryBlock,,每个inmemoryBlock最多64KB
- KEY被顺序的追加到最后一个inmemoryBlock;写满64KB就再申请一个。
- 达到512个inmemoryBlock后(也就是数据总量达到32MB),开始对每个inmemoryBlock进行压缩
本文就是解读inmemoryBlock的压缩过程。
压缩之前,会对inmemoryBlock内的所有KEY进行排序。
入口函数
func (ib *inmemoryBlock) marshalData这个函数实现了以下能力:
- 拷贝一个inmemoryBlock数据块的firstItem(也就是排序后的第一条数据)
- 拷贝一个inmemoryBlock数据块的commonPrefix (所有KEY都有的公共前缀)
- 对所有的KEY进行序列化,并做ZSTD压缩
- 记录所有KEY的长度,对长度进行序列化
下面主要讲述KEY的序列化方法。
SSTable中对KEY的压缩存储方法
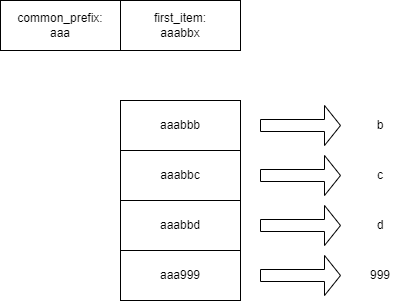
对面对的问题,也可以描述为: 存在N条排好序的字符串,字符串之间存在公共前缀。如何存储才能使得存储空间最优?
我直接说结论:
- 因为所有的字符串计算出了公共前缀,因此每个字符串的公共前缀不需要再存储了。
- 为了便于在块之间索引数据,提前了第一条KEY作为块的索引项。因为第一条数据提取为块的索引,所以数据从第二条开始存储就行了。(连这一点点都要省,所以我采用吝啬来形容)
- 公共前缀是所有KEY的前缀,且公共前缀很可能是空字符串。排序的KEY除了公共前缀外,两两之间还有共同的前缀。因此可以计算出这部分长度,后一个字符串只要存储与前一个字符串前缀以外的内容就行了。
- 两个字符串之间的公共前缀是多长呢?得记录下来。一组长度信息中,前一个值和后一个值可以取异或计算。相当于两个值高位的bit值相同的部分就被置0了,然后就得到了一个较小的值。小的值更容易压缩。
- 对于数值的序列化,这里用了protocol buffers中的一个技巧:用7bit来表示数值的内容,最高位说明后面的一个字节是否也表示长度。这样就可以用变长长度来序列化数值,而不是每个数值都占用固定的长度。
- 最后序列化后的KEY和长度,进行ZSTD压缩。
源码
我对源码进行了详细的注释:
// Preconditions:
// - ib.items must be sorted.
// - updateCommonPrefix must be called. // 序列化数据的函数
func (ib *inmemoryBlock) marshalData(sb *storageBlock, firstItemDst, commonPrefixDst []byte, compressLevel int) ([]byte, []byte, uint32, marshalType) {
if len(ib.items) <= 0 {
logger.Panicf("BUG: inmemoryBlock.marshalData must be called on non-empty blocks only")
}
if uint64(len(ib.items)) >= 1<<32 {
logger.Panicf("BUG: the number of items in the block must be smaller than %d; got %d items", uint64(1<<32), len(ib.items))
}
data := ib.data
firstItem := ib.items[0].Bytes(data)
firstItemDst = append(firstItemDst, firstItem...) // 第一个time series
commonPrefixDst = append(commonPrefixDst, ib.commonPrefix...) // 最大公共前缀
if len(ib.data)-len(ib.commonPrefix)*len(ib.items) < 64 || len(ib.items) < 2 {
// Use plain encoding form small block, since it is cheaper.
ib.marshalDataPlain(sb)
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
}
bbItems := bbPool.Get()
bItems := bbItems.B[:0] //保存目的 items 数据的内存buffer
bbLens := bbPool.Get()
bLens := bbLens.B[:0] // 保存目的 lens 数据的内存buffer
// Marshal items data.
xs := encoding.GetUint64s(len(ib.items) - 1) //??? 为什么要减1 猜测是firstItem单独存储了,所以就没必要在序列化中的数据再存储一次
defer encoding.PutUint64s(xs) // xs 保存两两比较公共前缀后的 异或后的 前缀值
cpLen := len(ib.commonPrefix) // 公共前缀的长度
prevItem := firstItem[cpLen:]
prevPrefixLen := uint64(0)
for i, it := range ib.items[1:] { //从第二个元素开始遍历
it.Start += uint32(cpLen) //偏移到公共前缀之后的位置
item := it.Bytes(data) //这里得到的[]byte就不包含公共前缀的部分
prefixLen := uint64(commonPrefixLen(prevItem, item)) //计算第N项和N-1项的公共前缀
bItems = append(bItems, item[prefixLen:]...) //仅仅只把差异的部分拷贝到目的buffer. 为了节约存储空间,差异的部分不存储进去。牛逼!
xLen := prefixLen ^ prevPrefixLen //第一次,与0异或,还是等于原值。异或后,两个整数值前面相同的部分都为0了,数值变得更短,能够便于压缩。
prevItem = item //上次的除去公共前缀的item
prevPrefixLen = prefixLen //上次计算得到的公共前缀
xs.A[i] = xLen //异或后的公共前缀值
}
bLens = encoding.MarshalVarUint64s(bLens, xs.A) //对N-1个长度进行序列化
sb.itemsData = encoding.CompressZSTDLevel(sb.itemsData[:0], bItems, compressLevel) //压缩后,写入storageBlock
//先两两去掉公共前缀,然后再ZSTD压缩
bbItems.B = bItems
bbPool.Put(bbItems)
// Marshal lens data.
prevItemLen := uint64(len(firstItem) - cpLen)
for i, it := range ib.items[1:] { //前面记录了两两的相对长度,这里记录完整长度.
itemLen := uint64(int(it.End-it.Start) - cpLen) //todo: 完整长度可以推算出来,应该可以不用记录才对
xLen := itemLen ^ prevItemLen
prevItemLen = itemLen
xs.A[i] = xLen
}
bLens = encoding.MarshalVarUint64s(bLens, xs.A) //长度信息包含两种,相对长度和总长度
sb.lensData = encoding.CompressZSTDLevel(sb.lensData[:0], bLens, compressLevel) //对长度信息序列化,然后压缩
bbLens.B = bLens
bbPool.Put(bbLens)
if float64(len(sb.itemsData)) > 0.9*float64(len(ib.data)-len(ib.commonPrefix)*len(ib.items)) {
// Bad compression rate. It is cheaper to use plain encoding.
ib.marshalDataPlain(sb) //压缩率不高的时候,选择不压缩
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
}
// Good compression rate.
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypeZSTD
}
VictoriaMetrics源码阅读:极端吝啬,vm序列化数据到磁盘的细节的更多相关文章
- 【原】AFNetworking源码阅读(四)
[原]AFNetworking源码阅读(四) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇还遗留了很多问题,包括AFURLSessionManagerTaskDe ...
- java8 ArrayList源码阅读
转载自 java8 ArrayList源码阅读 本文基于jdk1.8 JavaCollection库中有三类:List,Queue,Set 其中List,有三个子实现类:ArrayList,Vecto ...
- parseInt的源码阅读
parseInt的源码阅读 Integer.parseInt()这个方法的功能小巧又实用,实现起来困难不大,没有很复杂.这里就来看一下Java的源码是怎么写的吧,走一边大婶写过的代码,应该会有点收获吧 ...
- Three.js源码阅读笔记-5
Core::Ray 该类用来表示空间中的“射线”,主要用来进行碰撞检测. THREE.Ray = function ( origin, direction ) { this.origin = ( or ...
- 转-OpenJDK源码阅读导航跟编译
OpenJDK源码阅读导航 OpenJDK源码阅读导航 博客分类: Virtual Machine HotSpot VM Java OpenJDK openjdk 这是链接帖.主体内容都在各链接中. ...
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- 【JDK1.8】JDK1.8集合源码阅读——HashMap
一.前言 笔者之前看过一篇关于jdk1.8的HashMap源码分析,作者对里面的解读很到位,将代码里关键的地方都说了一遍,值得推荐.笔者也会顺着他的顺序来阅读一遍,除了基础的方法外,添加了其他补充内容 ...
- 【JDK1.8】JDK1.8集合源码阅读——IdentityHashMap
一.前言 今天我们来看一下本次集合源码阅读里的最后一个Map--IdentityHashMap.这个Map之所以放在最后是因为它用到的情况最少,也相较于其他的map来说比较特殊.就笔者来说,到目前为止 ...
- JDK源码阅读(1)_简介+ java.io
1.简介 针对这一个版块,主要做一个java8的源码阅读笔记.会对一些在javaWeb中应用比较广泛的java包进行精读,附上注释.对于容易混淆的知识点给出相应的对比分析. 精读的源码顺序主要如下: ...
- 【转】cJSON 源码阅读笔记
前言 cjson 的代码只有 1000+ 行, 而且只是简单的几个函数的调用. 而且 cjson 还有很多不完善的地方, 推荐大家看完之后自己实现一个 封装好的功能完善的 cjson 程序. json ...
随机推荐
- 【伙伴故事】智慧厨电接入华为云+HarmonyOS,你的未来厨房长这样
摘要:国内集成灶的头部企业-火星人,正是通过华为云IoT接入HarmonyOS生态,打造云端智慧厨房的整体解决方案,为我们描绘出一副未来厨房新趋势的蓝图. 本文分享自华为云社区<[伙伴故事]智慧 ...
- 如何利用 A/B 实验提升产品用户留存? 看字节实战案例给你答案!
技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 产品增长中最为经典的模型为 AARRR 漏斗模型,该模型追求最大化拉新,第一步"获客"(Acqui ...
- Solon 小技巧收集 - 页面跳转(重定向)
@XMapping("/") public void jump(XContext ctx){ ctx.redirect("http://www.noear.org&quo ...
- 使用 🤗 Transformers 优化文本转语音模型 Bark
Transformers 提供了许多最新最先进 (state-of-the-art, SoTA) 的模型,这些模型横跨多个领域及任务.为了使这些模型能以最佳性能运行,我们需要优化其推理速度及内存使用. ...
- 语音顶会 ICASSP 2022 成果分享:基于时频感知域模型的单通道语音增强算法
近日,阿里云视频云音频技术团队与新加坡国立大学李海洲教授团队合作论文 <基于时频感知域模型的单通道语音增强算法 >(Time-Frequency Attention for Monaura ...
- 为什么加了@Transactional注解,事务没有回滚?
在昨天的<事务管理入门>一文发布之后,有读者联系说根据文章尝试,加了@Transactional注解之后,事务并没有回滚.经过一顿沟通排查之后,找到了原因,在此记录一下,给后面如果碰到类似 ...
- OS | 进程和线程基础知识全家桶图文详解✨
前言 先来看看一则小故事 我们写好的一行行代码,为了让其工作起来,我们还得把它送进城(进程)里,那既然进了城里,那肯定不能胡作非为了. 城里人有城里人的规矩,城中有个专门管辖你们的城管(操作系统),人 ...
- Educational Codeforces Round 100 (Rated for Div. 2) 简单记录
最近在写Web大作业和期末复习,可能还会有一段时间不会更新blog了 1463A. Dungeon 题意:有3个血量为a,b,c的敌人,现在你每7发子弹能进行一次范围AOE攻击(即一次能集中三人),每 ...
- CMake学习,我们怎么从零开始狂写大型项目
CMake 说明 cmake的定义是什么 ?-----高级编译配置工具 当多个人用不同的语言或者编译器开发一个项目,最终要输出一个可执行文件或者共享库(dll,so等等)这时候神器就出现了-----C ...
- wxpython窗体之间传递参数
如何界面存在frame1与frame2,通过frame1打开页面frame2,并将frame2的值传递给frame1 可以使用回调函数传值参考具体代码如下: # -*- coding: utf-8 - ...