安装Hadoop单节点伪分布式集群
安装Hadoop单节点伪分布式集群
操作系统:Ubuntu server 20.04
参考文档:http://apache.github.io/hadoop/hadoop-project-dist/hadoop-common/SingleCluster.html
系统准备
开启SSH
系统支持SSH远程登陆.
如未安装可使用下面命令安装:
sudo apt-get install ssh
安装JDK
参考网址:https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
官方文档:
- Apache Hadoop 3.3 and upper supports Java 8 and Java 11 (runtime only)
- Please compile Hadoop with Java 8. Compiling Hadoop with Java 11 is not supported: HADOOP-16795 - Java 11 compile support OPEN
- Apache Hadoop from 3.0.x to 3.2.x now supports only Java 8
- Apache Hadoop from 2.7.x to 2.10.x support both Java 7 and 8
根据官方文档,目前支持JDK8和JDK11,我们安装JDK8即可
操作步骤如下:
# 更新软件包
sudo apt-get update
sudo apt-get upgrade
# 安装JDK8
sudo apt install openjdk-8-jdk
# 验证是否安装成功
java -version
# 输出
openjdk version "1.8.0_362"
OpenJDK Runtime Environment (build 1.8.0_362-8u372-ga~us1-0ubuntu1~22.04-b09)
OpenJDK 64-Bit Server VM (build 25.362-b09, mixed mode)
查看JAVA安装信息
# 查看安装目录
which java
# 输出:/usr/bin/java
# 查看具体路径
ll /usr/bin/java
# 输出:... /usr/bin/java -> /etc/alternatives/java*
设置JAVA_HOME
# 查找系统中可用的JAVA版本
update-alternatives --config java
# 输出:
# There is only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
# Nothing to configure.
# 通过上面输出信息安装路径为:/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
# 编辑profile文件
vim /etc/profile
# 在文件中添加下面代码
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
# 生效环境变量
source /etc/profile
# 验证是否设置成功
echo $JAVA_HOME
# 到这里如果停的话,就会出现一种情况,每次打开终端,就需要source /etc/profile一下才能使用java环境,所以参考博客https://blog.csdn.net/RABCDXB/article/details/123243868 做法如下:
# 输入vim ~/.bashrc,在对应文件中输入上面相同的配置数据。
安装Hadoop
下载
目前最新版本为:3.3.6,安装最新版本,可从官网下载。
下载地址:https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# 进入软件下载目录,如果该目录不存在则可创建此目录
cd /root/software
# 下载安装包
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
准备启动
# 将软件复制到安装目录,如果该目录不存在可创建
cd /root/program
# 复制安装包
cp /root/software/hadoop-3.3.6.tar.gz .
# 解压
tar -zxvf hadoop-3.3.6.tar.gz
# 设置JavaHome
vim /root/program/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
# 修改JAVA_HOME变量,大约在54行
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 保存后测试启动
cd /root/program/hadoop-3.3.6
bin/hadoop
# 此命令输出相关操作说明
接下来,将有三种启动模式部署:
Local (Standalone) Mode:单机模式
Pseudo-Distributed Mode:伪分布式
Fully-Distributed Mode:分布式
下面以伪分布式模式进行说明,其他模式部署方式请参考官方文档。
伪分布式模式安装
Hadoop可以以伪分布式的方式部署在一台机器上。
配置
配置core-site.xml文件.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim etc/hadoop/core-site.xml
# 在文件的configuration节点添加下面配置文件(第19行):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
配置etc/hadoop/hdfs-site.xml文件.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim etc/hadoop/hdfs-site.xml
# 在文件的configuration节点添加下面配置文件(第19行):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置sbin/start-dfs.sh文件中启动用户为root.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim sbin/start-dfs.sh
# 文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置sbin/stop-dfs.sh文件中启动用户为root.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim sbin/stop-dfs.sh
# 文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置sbin/start-yarn.sh文件中启动用户为root.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim sbin/start-yarn.sh
# 文件顶部添加以下参数
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置sbin/stop-yarn.sh文件中启动用户为root.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim sbin/stop-yarn.sh
# 文件顶部添加以下参数
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配饰SSH免密登录本机
# 检查是否已支持免密登录
ssh localhost
# 如果未配置,可使用下面命令配置,注意当前登录用户为root
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
测试启动
截至到目前配置,可以测试启动Hadoop,此种方式可手动执行MapReduce任务,该部分仅验证是否可正常启动。
后面将会介绍Yarn配置,并使用Yarn运行任务。
# 进入应用安装目录
cd /root/program/hadoop-3.3.6
# 文件系统格式化
bin/hdfs namenode -format
# 启动NameNode和DataNode
sbin/start-dfs.sh
# 浏览器打开终端进行查看运行状态,注意防火墙端口是否打开,NameNode网址如下:
http://192.168.40.134:9870/
# 现状状态 Active 即为运行成功
# 停止NameNode和DataNode
sbin/stop-dfs.sh
单节点安装YARN
在保证上面测试启动运行正常情况下,可以按照下面步骤配置启动YARN.
配置etc/hadoop/mapred-site.xml文件.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim etc/hadoop/mapred-site.xml
# 在文件的configuration节点添加下面配置文件(第19行):
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
配置etc/hadoop/yarn-site.xml文件.
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 编辑配置文件
vim etc/hadoop/yarn-site.xml
# 在文件的configuration节点添加下面配置文件(第16行):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
服务启动与停止:
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 服务启动
sbin/start-yarn.sh
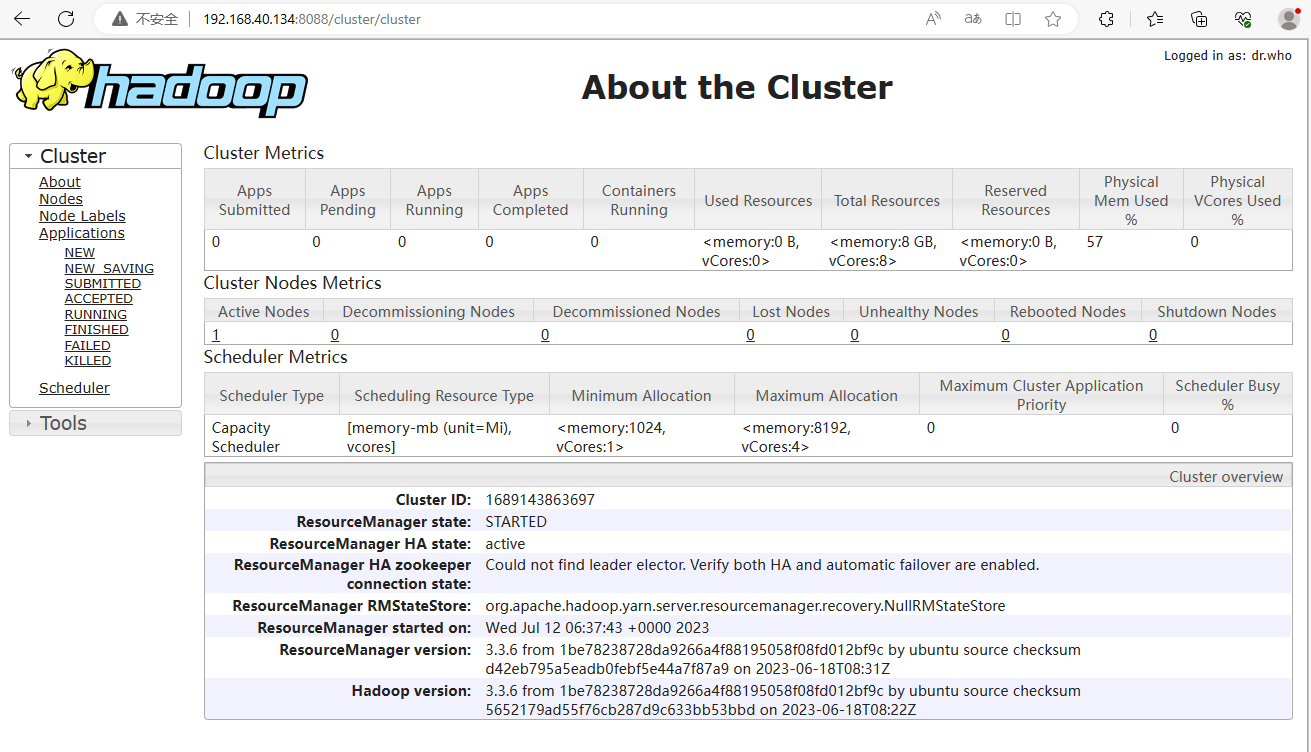
# 浏览器打开终端进行查看运行状态,注意防火墙端口是否打开,资源管理网址如下:
http://192.168.40.134:8088/
# 服务停止
sbin/stop-yarn.sh
伪分布式集群启动与停止
# 进入Hadoop软件目录
cd /root/program/hadoop-3.3.6
# 启动,注意顺序
sbin/start-dfs.sh
sbin/start-yarn.sh
# 停止,注意顺序
sbin/stop-dfs.sh
sbin/stop-yarn.sh

安装Hadoop单节点伪分布式集群的更多相关文章
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- Hadoop 单节点(或集群)基本配置信息
1. 默认配置文件: 存放于Hadoop对应的jar包中 core-default.xml hdfs-default.xml yarn-default.xml mapred-default.xml 2 ...
- Win10环境下Hadoop(单节点伪分布式)的安装与配置--bug(yarn的8088端口打不开+)
一.本文思路 [1].配置java环境–JDK12(Hadoop的底层实现语言是java,hadoop运行需要JDK环境) [2].安装Hadoop 1.解压hadop 2.配置hadoop环境变量 ...
- 单节点伪分布集群(weekend110)的HBase子项目启动顺序
伪分布模式下,如(weekend110)hbase-env.sh配置文档中的HBASE_MANAGES_ZK的默认值是true,它表示HBase使用自身自带的Zookeeper实例.但是,该实例只能为 ...
- CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2) https://hadoop.apache.org/releases.html 准备工作 关闭防火墙 (也可放行) # 停止防火墙 systemctl stop f ...
- 在Ubuntu14.10中部署Hadoop2.6.0单节点伪分布集群
1. 环境信息如下: ubuntu:14.10 jdk:openjdk-1.7.0 hadoop:2.6.0 2. 下载hadoop2.6.0, http://apache.fayea.com/had ...
- 单节点伪分布集群(weekend110)的Hive子项目启动顺序
因为,我的mysql是用root用户,在/home/hadoop/app/目录下,创建的. 第一步:开启mysql服务 第二步:启动hive [hadoop@weekend110 app]$ su r ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装
实验目的 了解java的安装配置 学习配置对自己节点的免密码登陆 了解hdfs的配置和相关命令 了解yarn的配置 实验原理 1.Hadoop安装 Hadoop的安装对一个初学者来说是一个很头疼的事情 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
随机推荐
- Java语言在Spark3.2.4集群中使用Spark MLlib库完成朴素贝叶斯分类器
一.贝叶斯定理 贝叶斯定理是关于随机事件A和B的条件概率,生活中,我们可能很容易知道P(A|B),但是我需要求解P(B|A),学习了贝叶斯定理,就可以解决这类问题,计算公式如下: P(A)是A的先验概 ...
- docker 容器操作、应用部署、mysql,redis,nginx、迁移与备份、Dockerfile
容器操作 # 启动容器 docker start 容器id # 停止容器 docker stop 容器id # 文件拷贝 先创建文件 mkdir:文件夹 vi vim touch:文件 # 容器的文件 ...
- Git提交代码仓库的两种方式
目录 一: 两种本地与远程仓库同步 1 git 远程仓库 提交本地版本库操作 提交到远程版本库操作 1.Git 全局设置: 2.增加一个远程仓库地址 3.查询当前存在的远程仓库 5.本地版本库内容提交 ...
- Restless API 与 Restful API
Restful API: 1.CURD(增删改查) 由请求方式决定 2.请求方式有:get/post/delete/put 3.同一个路径可以进行多个操作 Restless API 1.CURD(增 ...
- 通过重构来加深理解——DDD
上部分模型驱动设计的构造块为维护模型和实现之间的关系打下了基础.在开发过程中使用一系列成熟的基本构造块并运用一致的语言,能够使开发工作更加清晰而有条理. 我们面临的真正挑战是找到深层次的模型,这个模型 ...
- 阿里云交互式建模(DSW)的探索和踩坑
前言 自己的笔记本炼丹还是太吃力了些,风扇嘶吼有点心疼,看到阿里云出了一些免费试用的资源,想着能白嫖一下高端显卡跑一跑自制模型还挺有趣,于是有了下面的一些操作,其实没啥难度的,大胆的按文档来做基本就可 ...
- boot-admin开源项目中有关后端参数校验的最佳实践
我们在项目开发中,经常会对一些参数进行校验,比如非空校验.长度校验,以及定制的业务校验规则等,如果使用if/else语句来对请求的每一个参数一一校验,就会出现大量与业务逻辑无关的代码,繁重不堪且繁琐的 ...
- 【Linux】文本处理及Shell编程
1.统计出/etc/passwd文件中其默认shell为非/sbin/nologin的用户个数,并将用户都显示出来 [root@CentOS8 ~]# cat /etc/passwd root:x:0 ...
- [SWPUCTF 2021 新生赛]PseudoProtocols
[SWPUCTF 2021 新生赛]PseudoProtocols 一.题目 二.WP 1.打开题目,发现提示我们是否能找到hint.php,并且发现URL有参数wllm.所以我们尝试利用PHP伪协议 ...
- AcWing 3956. 截断数组
给定一个长度为 n 的数组 a1,a2,-,an. 现在,要将该数组从中间截断,得到三个非空子数组. 要求,三个子数组内各元素之和都相等. 请问,共有多少种不同的截断方法? 输入格式 第一行包含整数 ...