人工智能导论——机器人自动走迷宫&强化学习
一、问题重述
强化学习是机器学习中重要的学习方法之一,与监督学习和非监督学习不同,强化学习并不依赖于数据,并不是数据驱动的学习方法,其旨在与发挥智能体(Agent)的主观能动性,在当前的状态(state)下,通过与环境的交互,通过对应的策略,采用对应的行动(action),获得一定的奖赏(reward),通过奖赏来决定自己下一步的状态。
强化学习的几个重要的组分是:
- 环境,即智能体所处的外来环境,环境可以提供给智能体对应的状态信息,并且基于智能体一定的奖赏或者乘法。
- 智能体:智能体是强化学习中的学习和决策主体,他可以通过与环境的交互来学习改进其在当前环境下采取的决策策略。
- 状态:用于描述当前环境与智能体的情况,或者所观测的具体的变量。
- 行动:智能体基于观察到的状态所采取的操作或者决策
- 奖励:环境根据智能体所采取的行动和当前的状态给与其的反馈。
强化学习的目标是通过学习,不断优化自己的决策策略,使得对于任意一个状态下,智能体所采取的行动,都能够获得最大的奖励,值得注意的是,这种奖励是长期奖励,而非眼前奖励。我们为了实现这一目标,通常会引入价值函数和动作-价值函数来评估行为的好坏,同时使用一定的算法和方法来不断迭代价值函数,在优化迭代价值函数同时,我们实际上就是在优化智能体的决策策略,这是因为事实上价值函数就是表示智能体在时刻t处于状态s时,按照策略π采取行动时所获得回报的期望。价值函数衡量了某个状态的好坏程度,反映了智能体从当前状态转移到该状态时能够为目标完成带来多大“好处”。我们通过迭代价值函数,就可以不断的迭代自己的行动策略π。
机器人走迷宫问题是一个经典的强化学习的基本问题,我们可以将机器人看做是智能体,将迷宫看做环境,将机器人所处的地方视为状态,机器人的行动称之为动作,机器人根据当前的迷宫周围的环境所采取的动作称之为策略,每次移动是否合法,是否到达迷宫终点视为环境给予的奖励。
二、设计思想
我们考察机器人走迷宫问题,由于迷宫是有限范围的迷宫,迷宫的状态是有限的,针对这种情况,我们可以采用深度优先搜素或宽度优先搜索实现对状态的穷举,然后探索出一条符合条件的路径。针对宽度优先搜索,题中已经给出了对应的代码,构建了一颗搜索树,然后通过层次遍历的办法来搜索,我们在这里考虑使用深度优先搜索。
深度优先搜索的实现方法是递归与堆栈,可以看做“一条路走到黑,不见黄河不回头,不见棺材不落泪”,他会沿着一条路径一直走,直到走到不合法死胡同为止。我们在当前状态下,可以通过函数得到可以走的路径,然后从中选择一个,进行递归传参,然后继续这个过程,直到走到死胡同或者路径终点为止。不过值得注意的是,我们需要用到回溯算法:回溯算法的本质是,我们这次搜索不希望对于下一次搜索产生影响,所以想要完全消除掉本次搜索对于环境的影响,在这里我们采用了一个vis数组来判定该状态是否被遍历过,采用了一个path数组来存储每次采取的动作是什么,我们回溯的思路便是在搜索完或者走到死胡同后往回走,将当前搜索完的path删掉,同时vis数组置0,这种算法的正确性是显然的,并不会陷入无穷的遍历过程,因为对于每一个状态,我们采取的动作都是唯一的,我们在每一个状态都会遍历对应的动作,而不会往回遍历,回溯的目的并不是回溯动作,而是删除当前搜索对于未来搜索的影响。这便是我们深度优先搜索的设计思想。
接下来我们考虑实现非搜索算法,即使用强化学习的方法:强化学习首先需要明确优化的对象即价值函数和动作价值函数:
我们不妨假设环境所给智能体的奖赏为:
maze.set_reward(reward={
"hit_wall": -10.,
"destination": 50.,
"default": -0.1,
})
即撞墙的奖赏为-10,到达重点奖赏为50,正常情况下的奖赏为-0.1,撞墙需要提供一定的惩罚是显然的,而且惩罚力度要尽可能的大,以鼓励智能体去探索可行的路径。
接下来我们考虑优化价值函数和动作价值函数,我们考虑采取Q-learning算法进行迭代。Q-learning是一个值迭代算法,而不是策略迭代算法,下面简要介绍一下值迭代和策略迭代之间的差异:
值迭代是一种基于迭代更新价值函数的方法,旨在找到最优的价值函数和策略。它通过反复迭代计算每个状态的值函数,直到值函数收敛到最优值函数。具体而言,值迭代的步骤如下:
- 初始化所有状态的值函数为任意值。
- 对于每个状态,根据当前值函数和当前策略,计算其更新后的值函数。
- 重复步骤2,直到值函数收敛到最优值函数。
- 根据最优值函数,得到最优策略。
而策略迭代是一种同时优化价值函数和策略的方法。它交替进行策略评估和策略改进的步骤,直到策略收敛到最优策略。具体而言,策略迭代的步骤如下:
- 初始化策略为任意策略。
- 策略评估:根据当前策略计算每个状态的值函数。
- 策略改进:根据当前值函数选择每个状态的最优行动,更新策略。
- 重复步骤2和步骤3,直到策略收敛到最优策略。
值迭代和策略迭代都可以用于找到最优的策略,但它们在算法的执行方式和收敛性质上有所不同。值迭代通常需要更多的迭代次数来达到收敛,但每次迭代的计算量较小。策略迭代在每次迭代中都需要进行策略评估和策略改进的步骤,计算量较大,但通常收敛更快。
我们在此处采取Q-learning算法进行值迭代。Q-learning算法会将状态和动作构成一张表来存储Q值,如下所示:

Q值为动作价值函数,具体的计算公式为

也就是说,当前状态下,采取动作a的Q值为环境即时的奖赏以及到达下一个状态后,执行任意行动后所获得的最大奖赏的γ倍,此处的γ为折扣因子,换句话说,当前状态的Q值取决于环境的即时奖赏和未来的长期奖励,其中长期奖励的定义方法是递归定义。
我们的Q-learning的本质就是维护一个Q表,在Q表收敛后,根据Q表进行决策,由于强化学习是一个马尔科夫过程,当前时刻的奖赏与事件无关,只与状态和采取的行动有关,所以我们可以在某一个状态下,找到Q表中对应获得奖赏最大的动作进行行动,然后根据行动后到达的状态继续行动,以此类推,直到到达目标点。
如何根据Q表进行决策的过程我们已经说明,接下来我们考虑如何对Q表进行维护:维护Q表是通过不断更新Q值实现的,具体来说,我们对于每一个时间步的状态,会选择一个动作a,值得注意的是,该动作的选择并不是通过简单的贪心找最大实现的,我们通常会使用贪心策略,即在某一个状态下,有的概率选择其余的部分进行探索,有1-的概率选择最高的奖赏进行迭代,是超参数,为了平衡利用和探索,类似于MCT中的超参数c。在选择完动作a后,观察到奖励和下一个状态,根据我们的更新规则对Q表的Q值进行更新,然后跳转到下一个状态,以此类推。
值得注意的是,我们更新Q表的Q值,采用较为保守的策略进行更新,引入松弛变量α,具体而言,公式如下:
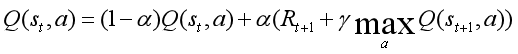
也就是说,我们的值并不完全通过计算的新Q值得到,而是通过新Q值和旧Q值线性加权得到的。
我们考虑基本的Q-learning有一个问题:我们的Q值取决于动作价值函数,动作价值函数就与状态耦合,如果状态过多,有些状态可能始终无法采样到,因此对这些状态的q函数进行估计是很困难的,并且,当状态数量无限时,不可能用一张表(数组)来记录q函数的值。我们考虑多层感知机(MLP)是一个通用的函数逼近器,可以以任意精度逼近任意多项式函数,所以我们考虑采用深度神经网络来拟合Q函数,而不是通过值迭代的方法对Q值进行计算。这便是我们的DQN(Deep-Q-Learning)
- 初始化q函数的参数θ
- 循环
- 初始化s为初始状态
- 循环
采样a∼ϵ−greedy_π(s;θ)
执行动作a,观察奖励R和下一个状态s′
损失函数
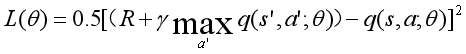
根据梯度∂L(θ)∕∂θ更新参数θ
s←s′
- 直到s是终止状态
- 直到q_π收敛
- 循环
我们的损失函数一般而言是MSE损失函数,主要刻画了当前神经网络拟合的Q值与我们计算出的Q值之间的差异,通过不断优化减少损失函数来更新神经网络的参数。
值得注意的是,我们有一些小tricks例如经验重现,经验重现是指我们建立一个经验缓冲区,用于存储过去的状态,所采取的动作,获得的奖励和更新后的状态,这样做的动机是,如果我们只使用当前的经验来更新模型参数,容易受到样本的相关性和序列效应的影响,导致不稳定的学习和收敛困难。
我们考虑使用经验缓冲区对神经网络进行优化,每次随机选取一定量的样本进行更新迭代,这样做就可以避免样本的相关性的影响。
接下来我们考虑损失函数,在损失函数中,q函数的值既用来估计目标值,又用来计算当前值。现在这两处的q函数通过θ有所关联,可能导致优化时不稳定,我们考虑让损失函数中的两个q函数使用不同的参数计算。
- 用于计算估计值的q使用参数θ−计算,这个网络叫做目标网络
- 用于计算当前值的q使用参数θ计算
- 保持θ−的值相对稳定,例如θ每更新多次后才同步两者的值θ−←θ
三、代码内容
代码内容略
四、实验结果
对于实验结果,可以完全通过网站上的几个例子,并且程序运行时间特别快


五、总结
总体来看,本次实验符合预期,DQN的效果特别不错,在实验中,遇到的比较大的问题是建立DQN网络和调整相应的超参数,我们调整超参数的策略可以通过在本地运行不同maze大小,看训练完之后,机器人采取一定行动能否到达最终的目的地,如果不能到达目的地,看机器人的行动轨迹,调整不同的超参数的值来使模型达到最佳的效果。
朴素的搜索算法本来我写了一个传递location参数的版本,但是评测要求不能传递这个参数,所以我们只能将其声明为全局变量进行使用,总体来看,本次实验难度适中,特别合理,收获很大!
人工智能导论——机器人自动走迷宫&强化学习的更多相关文章
- 用Q-learning算法实现自动走迷宫机器人
项目描述: 在该项目中,你将使用强化学习算法,实现一个自动走迷宫机器人. 如上图所示,智能机器人显示在右上角.在我们的迷宫中,有陷阱(红色炸弹)及终点(蓝色的目标点)两种情景.机器人要尽量避开陷阱.尽 ...
- 基于TORCS和Torch7实现端到端连续动作自动驾驶深度强化学习模型(A3C)的训练
基于TORCS(C++)和Torch7(lua)实现自动驾驶端到端深度强化学习模型(A3C-连续动作)的训练 先占坑,后续内容有空慢慢往里填 训练系统框架 先占坑,后续内容有空慢慢往里填 训练系统核心 ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- 【强化学习】MOVE37-Introduction(导论)/马尔科夫链/马尔科夫决策过程
写在前面的话:从今日起,我会边跟着硅谷大牛Siraj的MOVE 37系列课程学习Reinforcement Learning(强化学习算法),边更新这个系列.课程包含视频和文字,课堂笔记会按视频为单位 ...
- 阅读AuTO利用深度强化学习自动优化数据中心流量工程(一)
目录 问题 解决方法 模型选择 框架构建 Sigcomm'18 AuTO: Scaling Deep Reinforcement Learning for Datacenter-Scale Autom ...
- ReLeQ:一种自动强化学习的神经网络深度量化方法
ReLeQ:一种自动强化学习的神经网络深度量化方法 ReLeQ:一种自动强化学习的神经网络深度量化方法ReLeQ: An Automatic Reinforcement Learning Ap ...
- 基于深度强化学习(DQN)的迷宫寻路算法
QLearning方法有着明显的局限性,当状态和动作空间是离散的且维数不高时可使用Q-Table存储每个状态动作的Q值,而当状态和动作时高维连续时,该方法便不太适用.可以将Q-Table的更新问题变成 ...
- 机器学习之强化学习概览(Machine Learning for Humans: Reinforcement Learning)
声明:本文翻译自Vishal Maini在Medium平台上发布的<Machine Learning for Humans>的教程的<Part 5: Reinforcement Le ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
随机推荐
- day06-静态资源访问&Rest风格
SpringBoot之静态资源访问&REST风格请求 1.SpringBoot静态资源访问 1.1基本介绍 只要静态资源是放在类路径下的:/static./public./resources. ...
- stm32的学习笔记1
一 目录结构管理 Libraries是放官方固件库的 MDK-ARM是放产生的文件的,工程存放的目录 USERS是放自己写的代码的 然后是一个解释文件README 在MDK-ARM目录里还要创建两个文 ...
- python线程之event事件
from threading import Thread, Event import time event = Event() def light(): print('红灯亮着,所有车都要等待') t ...
- kubernetes 的TCP 数据包可视化
kubernetes 的TCP 数据包可视化 介绍 k8spacket是用 Golang 编写的工具,它使用gopacket第三方库来嗅探工作负载(传入和传出)上的 TCP 数据包.它在运行的容器网络 ...
- 在k8s(kubernetes)上安装 ingress V1.1.3
介绍 Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由.流量路由由 Ingress 资源上定义的规则控制. 下面是一个将所有流量都发送到同一 Service 的简单 In ...
- [软件体系结构/架构]零拷贝技术(Zero-copy)[转发]
0 前言 近期遇到难题:1个大数据集的查询导出API,因从数据库查询后占用内存极大,每次调用将消耗近100MB的JVM内存资源.故现需考虑研究和应用零拷贝技术. 如下全文摘自: 看一遍就理解:零拷贝原 ...
- [MyBatis]MyBatis问题及解决方案记录
1字节的UTF-8序列的字节1无效 - CSDN 手动将<?xml version="1.0" encoding="UTF-8"?>中的UTF-8更 ...
- 我来泼盆冷水:正面迎击AI的时代千万别被ChatGPT割了韭菜
前言 ChatGPT从出来的时候我就一直密切关注,为此还加了不少群,用了不少套壳的程序,公司还开了专门的培训会,技术团队还为此搭建了接入ChatGPT的服务,帮助全公司的产品.商务.测试.运维.研发一 ...
- Django笔记二十一之使用原生SQL查询数据库
本文首发于公众号:Hunter后端 原文链接:Django笔记二十一之使用原生SQL查询数据库 Django 提供了两种方式来执行原生 SQL 代码. 一种是使用 raw() 函数,一种是 使用 co ...
- Redis(二)redis发布与订阅以及三种新数据类型
1 配置文件 Utis单位部分 redis支持字节但不支持其他类型 Includes部分 设置包含的其他文件的目录 netword网络部分 bind:默认情况bind=127.0.0.1只接受本机的访 ...