date_histogram,es按照时间分组统计
日期直方图聚合(date_histogram)
与histogram相似,es中内部将日期表示为一个long值,所以有时候可以用histogram来达到相同的目的,但往往没有date_histogram那么精确
date_histogram的特点在于可以使用 日期/时间表达式指定间隔。
原本的interval在7.2中被弃用,更换为fixed_interval与calendar_interval
相关字段
calendar_interval
只支持单个日历单元,如:支持1m 不支持2m 1.5m
- minute (
1m) - hour(
1h) - day(
1d) - week(
1w) - month(
1m) - quarter( 季度
1q) - year(
1y)
fixed_interval
固定间隔,SI单位i,永远不会偏离,
- seconds (s) :
30s - hours (h) :
1.5h - days (d):
3d
time_zone
es的日期时间是以UTC存储的,默认情况下,所有的桶装和四舍五入也是在 UTC 中完成的。使用 time _ zone 参数指示 bucket 应使用不同的时区。
时区可以指定为 ISO 8601 UTC的偏移量,也可指定为 IANA 时区数据库中指定的时区 ID。如 "time_zone": "+08:00" 或"time_zone": "Asia/Shanghai"
这里引用一个官方的例子:
PUT my_index/_doc/1?refresh
{
"date": "2015-10-01T00:30:00Z"
}
PUT my_index/_doc/2?refresh
{
"date": "2015-10-01T01:30:00Z"
}
不指定时区
GET my_index/_search?size=0
{
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"calendar_interval": "day"
}
}
}
}
# 响应
{
...
"aggregations": {
"by_day": {
"buckets": [
{
"key_as_string": "2015-10-01T00:00:00.000Z",
"key": 1443657600000,
"doc_count": 2
}
]
}
}
}
如果指定的时区为“-01:00”,那么该时区的24点就是UTC23点
GET my_index/_search?size=0
{
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"calendar_interval": "day",
"time_zone": "-01:00"
}
}
}
}
# 现在,第一个文档落入2015年9月30日的桶中,而第二个文档落入2015年10月1日的桶中:
{
...
"aggregations": {
"by_day": {
"buckets": [
{
# key_as_string 值表示指定时区内每天的午夜。
"key_as_string": "2015-09-30T00:00:00.000-01:00",
"key": 1443574800000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T00:00:00.000-01:00",
"key": 1443661200000,
"doc_count": 1
}
]
}
}
}
offset
使用偏移量参数根据指定的正偏移量(+)或负偏移量(-)持续时间更改每个 bucket 的开始值
比如一个index中现有两个文档,date属性分别为2015.10.01 05:30:00和2015.10.01 06:30:00,使用如下参数,那么这两个文档会落入一桶中,即2015-10-01 00:00:00的桶中
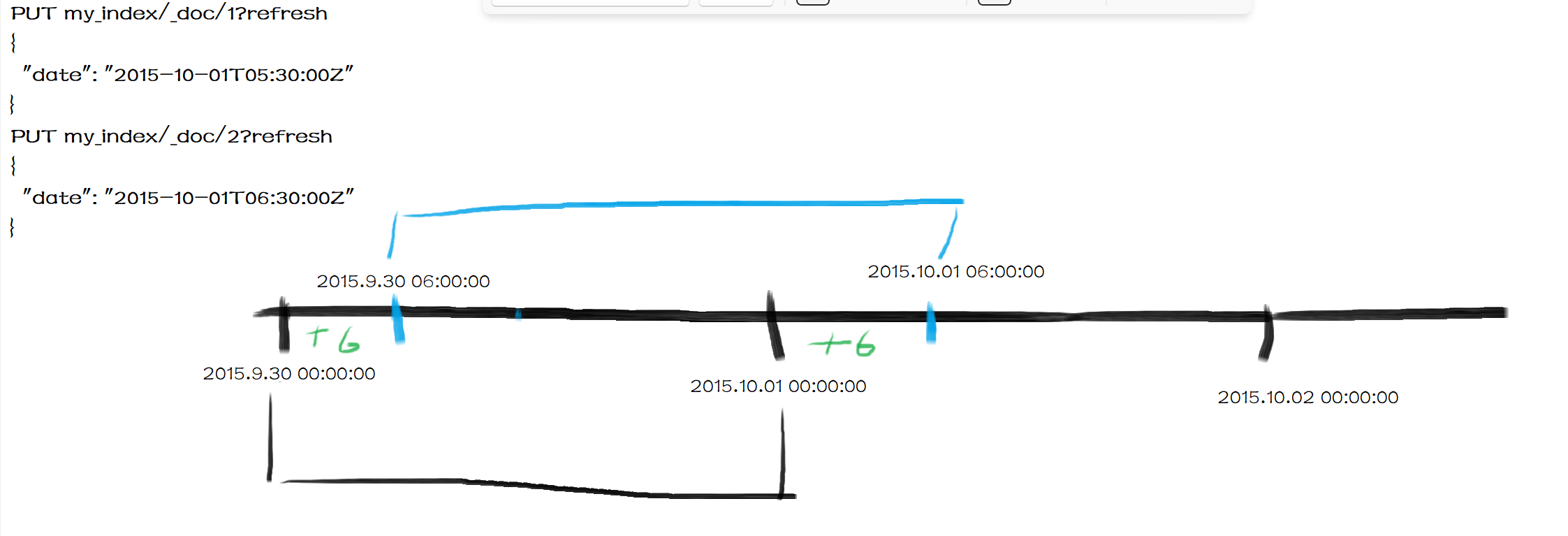
{
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"calendar_interval": "day"
}
}
}
}
如果这时偏移量设置为+6h:
{
...
"aggregations": {
"by_day": {
"buckets": [
{
"key_as_string": "2015-09-30T06:00:00.000Z",
"key": 1443592800000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T06:00:00.000Z",
"key": 1443679200000,
"doc_count": 1
}
]
}
}
}
extended_bounds
强制返回指定范围内的每一个桶,min与max都会被当做桶返回
date_histogram,es按照时间分组统计的更多相关文章
- Oracle按不同时间分组统计
Oracle按不同时间分组统计 Oracle按不同时间分组统计的sql 如下表table1: 日期(exportDate) 数量(amount) -------------- ----------- ...
- Oracle 按不同时间分组统计
1.按年 select to_char(record_date,'yyyy'), sum(col_8) as total_money from table_name where group by to ...
- ES 24 - 如何通过Elasticsearch进行聚合检索 (分组统计)
目录 1 普通聚合分析 1.1 直接聚合统计 1.2 先检索, 再聚合 1.3 扩展: fielddata和keyword的聚合比较 2 嵌套聚合 2.1 先分组, 再聚合统计 2.2 先分组, 再统 ...
- Dev用于界面按选中列进行分组统计数据源(实用技巧)
如果有用U8的可以明白这个功能就是模仿他的统计功能.我不过是把他造成通用的与适应于DEV的. (效率为6000条数据分组统计时间为3秒左右分组列过多5秒.1000条以下0.几秒,500条下0.00几秒 ...
- DataTable、List使用groupby进行分组和分组统计;List、DataTable查询筛选方法
DataTable分组统计: .用两层循环计算,前提条件是数据已经按分组的列排好序的. DataTable dt = new DataTable(); dt.Columns.AddRange(new ...
- Mysql 根据时间戳按年月日分组统计
Mysql 根据时间戳按年月日分组统计create_time时间格式SELECT DATE_FORMAT(create_time,'%Y%u') weeks,COUNT(id) COUNT FROM ...
- Mysql中较为复杂的分组统计去重复值
这是我的代码: 前提是做了一个view:att_sumbase 首先分开统计每天的中午.下午饭点人数,这时需要分别去除中午和下午重复打卡的人.用了记录集的交,嵌套select的知识. 注意不能直接使用 ...
- SQL——按照季度,固定时间段,分组统计数据
最近在工作中接到了一个需求,要求统计当月以10天为一个周期,每个周期的数据汇总信息.假设有一张表如下: 表table_test中 ID AMOUNT CREATE_ ...
- 【.Net】 大文件可使用的文本分组统计工具(附带源码,原创)
本工具可实现的效果: 1.读取大文件(大于1GB) 2.根据分隔符分割后的列分组 3.速度快. 4.处理过程中,可以随时停止处理,操作不卡死. 5.有对当前内存的实时监测,避免过多占用内存,影响系统运 ...
- 问题 B: 分组统计
分组统计 问题 B: 分组统计时间限制: 1 Sec 内存限制: 32 MB 提交: 416 解决: 107 [提交][状态][讨论版][命题人:外部导入] 题目描述 先输入一组数,然后输入其分组,按 ...
随机推荐
- XTW100编程器在Win10下的安装
XTW100 这是一个淘宝上卖得很多的经典编程器, 用于写入24和25系列的存储芯片. 最初使用的是stm32f103c8t6, 因为f103价格飞涨, 市面上大都换成国产的兼容mcu了, 软件和使用 ...
- Goland 使用[临时]
环境变量 因为module模式的引入, 多个项目可以共用同一套External Libraries, 在File->Settings->Go中, 设置GOROOT为go安装目录, 例如 / ...
- np.newaxis的用法
1 前言 np.newaxis的意思是给数组新增一个维度."python中矩阵切片维数微秒变化"中介绍了矩阵切片有时候会降低矩阵维度,为保证维度不变,可以用np.newaxis新增 ...
- patch命令
patch命令 patch指令让用户利用设置修补文件的方式.修改.更新原始文件,倘若一次仅修改一个文件,可直接在指令列中下达指令依序执行,如果配合修补文件的方式则能一次修补大批文件,这也是Linux系 ...
- 临时修改session日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01' alter session set NLS_DATE_LANGUAGE ...
- djang中orm使用iterator()
当查询结果有很多对象时,QuerySet的缓存行为会导致使用大量内存.如果你需要对查询结果进行好几次循环,这种缓存是有意义的,但是对于 queryset 只循环一次的情况,缓存就没什么意义了.在这种情 ...
- SOTIF很快将会取代ISO 26262?为您详细解读SOTIF标准ISO/PAS 21448
SOTIF很快将会取代ISO 26262?为您详细解读SOTIF标准ISO/PAS 21448 根据MES模赛思对其全球客户的问卷调查表明, 尽管有相当一部分的参与者(35%)认为SOTIF在功能安全 ...
- 【Azure 存储服务】如何查看Storage Account的删除记录,有没有接口可以下载近1天删除的Blob文件信息呢?
问题描述 如何查看Storage Account的删除记录,有没有接口可以下载近1天删除的Blob文件信息呢?因为有时候出现误操作删除了某些Blob文件,想通过查看删除日志来定位被删除的文件信息. 问 ...
- Nebula Graph 在众安保险的图实践
本文首发于 Nebula Graph Community 公众号 互联网金融的借贷同传统信贷业务有所区别,相较于传统信贷业务,互联网金融具有响应快.数据规模大.风险高等特点.众安保险主要业务是做信用保 ...
- Tomcat8.5简介
1. Tomcat简介[1] Apache Tomcat是Servlet/JSP的容器.Tomcat8.5 实现了由 JCP 组织 (Java Community Process) 制定的Servle ...