hadoop安装问题
1、
运行start-dfs.sh启动HDFS守护进程,start-yarn.sh面向YARN的资源器和节点管理器,资源管理器web地址是http://localhost:8080/。输入stop.dfs.sh,stop-yarn.sh终止守护进程。
以上是打开hadoop服务的两种方法,每次使用hadoop之前都需要使用这条命令打开hadoop,接着使用jps查看服务是否已经启动,在浏览器中http://localhost:50070查看hadoop相关情况
2、
运行 ps -e | grep ssh,查看是否有sshd进程ss
如果没有,说明server没启动(谷总说ssh是自动启动的)
3、
网络配置过程中,以sudo的方式修改/etc/hosts文件(否则提示文件是只读的)过程,ip地址是虚拟机里网卡的ip地址,使用ifconfig察看ip(hadoop装在虚拟机里的情况下),修改完成之后使用source /etc/hosts(source命令也称为“点命令”,也就是一个点符号(.)。source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。用法: source filename 或 . filename)。另外,虚拟机的网路配置选项选择桥接,这样就可以实行物理机与虚拟机、Master与Slave之间的通信(可以ping通,两台主机之间可以ping通前提是两台主机在同一个网段之内,同一个网段就是网络标识相同,网络标识的计算方法就是ip地址和掩码进行与运算。想在同一网段,必需做到网络标识相同,那网络标识怎么算呢?各类IP的网络标识算法都是不一样的。A类的,只算第一段。B类,只算第一、二段。C类,算第一、二、三段。)
将hadoop文件通过ssh从Master发给Slave之后,需要在Slave机器上使用chown命令修改hadoop文件的所有者以及所属的群组(http://www.cnblogs.com/lz3018/p/4871391.html)
4、
由于多次格式化hdfs,导致格式化hdfs的时候失败(提示Reformat Y or N,输入了Y也不能格式化成功),可能会导致namenode无法启动,所以如果要重新格式化,需要按如下步骤进行:在进行一切实验之前,我们首先清空/usr/local/hadoop/tmp以及logs文件夹(其实就是情况hadoop.tmp.dir配置项路径下的tmp和logs文件夹即可,不用下面那么麻烦)。
1、查看hdfs-ste.xml:
- <property>
- <name>dfs.name.dir</name>
- <value>/home/hadoop/hdfs/name</value>
- <description>namenode上存储hdfs名字空间元数据</description>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/home/hadoop/hdsf/data</value>
- <description>datanode上数据块的物理存储位置</description>
- </property>
将 dfs.name.dir所指定的目录删除、dfs.data.dir所指定的目录删除
2、查看core-site.xml:
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/home/hadoop/hadooptmp</value>
- <description>namenode上本地的hadoop临时文件夹</description>
- </property>
将hadoop.tmp.dir所指定的目录删除。
3)重新执行命令:bin/hdfs namenode -format
格式化完毕。
注意:原来的数据全部被清空了。产生了一个新的hdfs。
5、运行bin/hdfs dfsadmin -report,结果显示
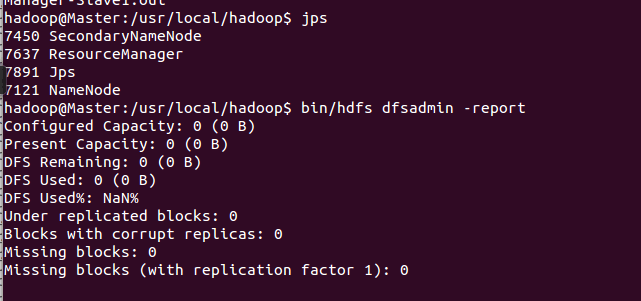
结果都是0,说明datanode有问题,进去Slave1查看hadoop-hadoop-datanode-Slave1.log文件,就是datanode的日志文件,提示信息如下:
Retrying connect to server: localhost/127.0.0.1:9000. Already tried 5 time。。。。。
这说明datanode连接不到Master,到server的链路不通,最后发现Slave1端的core-site.xml文件有一个配置项并没有改过来(Master上改过来了)
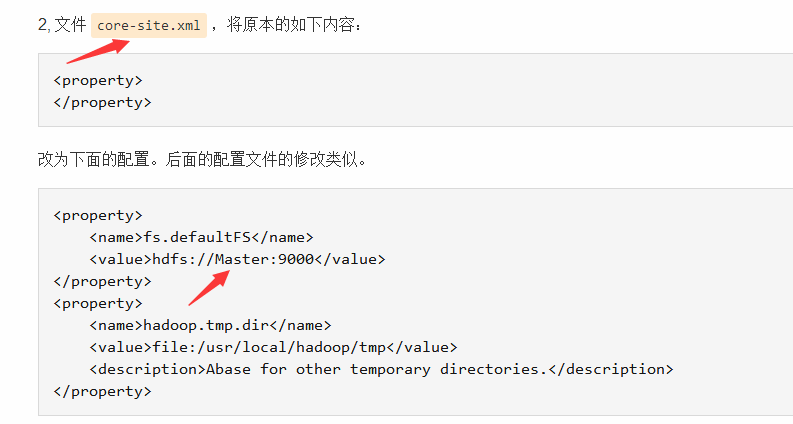
原先是localhost:9000,改为Master:9000,成功。localhost:9000也对应了 Retrying connect to server: localhost/127.0.0.1:9000. Already tried 5 time。。。。。
6、
执行mapreduce作业的时候会job会卡在那里,一直卡着,发现原因是mapred-site.xml和yarn-site.xml的配置问题,正确配置如下:
mapred-site.xml
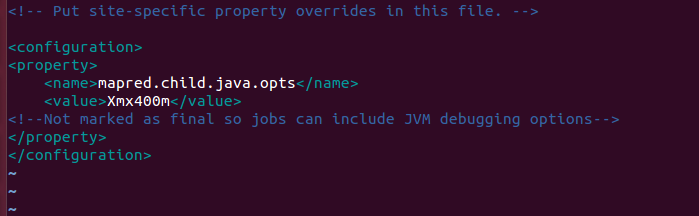
另外使用
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar grep input output 'dfs[a-z.]+' 运行实例时正确写法是
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input/hadoop output 'dfs[a-z.]+'
Hadoop运行程序时,默认输出目录不能存在,因此再次运行需要执行如下命令删除 output文件夹:
bin/hdfs dfs -rm -r /user/hadoop/output # 删除 output 文件夹
使用命令 bin/hadoop fs -ls /usr/hadoop 查看hdfs中/usr/hadoop有哪些文件
最后使用
bin/hdfs dfs -cat output/* 查看mapreduce运算结果,如下图所示:
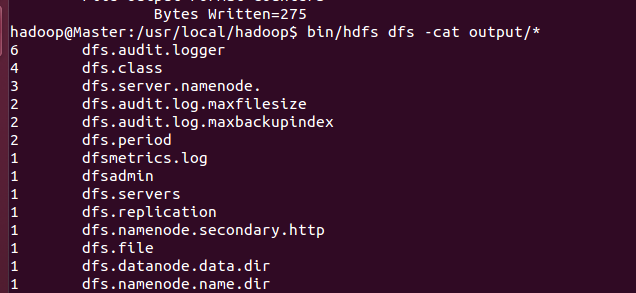
7、
NodeManager没有启动原因之一:
就是yarn-site.xml中
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> 属性yarn.nodemanager.aux-services的值应为mapreduce_shuffle,而不是mapreduce.shuffle(Hadoop权威指南第三版上348页配置yarn-site.xm这样配置) 8、补充两个hadoop的下载地址:
http://mirrors.cnnic.cn/apache/hadoop/common/
http://mirror.bit.edu.cn/apache/hadoop/common/ 参考:
http://www.powerxing.com/install-hadoop/
hadoop安装问题的更多相关文章
- linux hadoop安装
linux hadoop安装 本文介绍如何在Linux下安装伪分布式的hadoop开发环境. 在一开始想利用cgywin在 windows下在哪, 但是一直卡在ssh的安装上.所以最后换位虚拟机+ub ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- hadoop安装遇到的各种异常及解决办法
hadoop安装遇到的各种异常及解决办法 异常一: 2014-03-13 11:10:23,665 INFO org.apache.hadoop.ipc.Client: Retrying connec ...
- hadoop安装实战(mac实操)
集群环境配置参考(http://blog.csdn.net/zcf1002797280/article/details/49500027) 参考:http://www.cnblogs.com/liul ...
- hadoop安装计
hadoop安装计 大体上按这个做就好了 http://blog.csdn.net/hitwengqi/article/details/8008203 需要修改hadoop-env.sh export ...
- [Hadoop入门] - 2 ubuntu安装与配置 hadoop安装与配置
ubuntu安装(这里我就不一一捉图了,只引用一个网址, 相信大家能力) ubuntu安装参考教程: http://jingyan.baidu.com/article/14bd256e0ca52eb ...
- Hadoop安装(Ubuntu Kylin 14.04)
安装环境:ubuntu kylin 14.04 haoop-1.2.1 hadoop下载地址:http://apache.mesi.com.ar/hadoop/common/hadoop-1. ...
- hadoop安装配置——伪分布模式
1. 安装 这里以安装hadoop-0.20.2为例 先安装java,参考这个 去着下载hadoop 解压 2. 配置 修改环境变量 vim ~/.bashrc export HADOOP_HOME= ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- Hadoop安装教程_单机/伪分布式配置
环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS).如果用的是 Ubuntu 系统,请查看相应的 Ubuntu安装Hadoo ...
随机推荐
- ubuntu miss tool bar
reson: unity exception 1. open terminal: /usr/bin/**terminal** 2. run command on terminal: gsetting ...
- windows下python+flask环境配置详细图文教程
本帖是本人在安装配置python和flask环境时所用到的资源下载及相关的教程进行了整理罗列,来方便后面的人员,省去搜索的时间.如果你在安装配置是存在问题可留言给我. 首先罗列一下python+fla ...
- 菜鸟学习Spring——60s让你学会动态代理原理
一.为什么要使用动态代理 当一个对象或多个对象实现了N中方法的时候,由于业务需求需要把这个对象和多个对象的N个方法加入一个共同的方法,比如把所有对象的所有方法加入事务这个时候有三种方法 ...
- 算法系列7《CVN》
计算CVN时使用二个64位的验证密钥,KeyA和KeyB. 1) 计算CVN 的数据源包括: 主账号(PAN).卡失效期和服务代码,从左至右顺序编排. 4123456789012345+8701+11 ...
- oracle 分析函数(笔记)
分析函数是oracle数据库在9i版本中引入并在以后版本中不断增强的新函数种类.分析函数提供好了跨行.多层次聚合引用值的能力.分析函数所展现的效果使用传统的SQL语句也能实现,但是实现方式比较复杂,效 ...
- DeviceOne开发HelloWord
http://www.cnblogs.com/wjiaonianhua/p/5278061.html http://www.jb51.net/article/75693.htm 2015 年 9 月 ...
- poj 2485 Highways
题目连接 http://poj.org/problem?id=2485 Highways Description The island nation of Flatopia is perfectly ...
- Iframe跨域Session丢失的问题
很久之前做的一个使用插件实现了图片批量上传,是通过IFrame加载上传面板的,使用google的chrome上传成功了就没怎么理了,最近同事测试时(使用的是360安全浏览器)老是出现上传不了图片的问题 ...
- com.Goods.ForEach
com.Goods.ForEach(g => { g.TransactionPrice = getUnitPriceByProductId(g.ProductID); g.ExpressMone ...
- P3380: [Usaco2004 Open]Cave Cows 1 洞穴里的牛之一
还是蛮简单的一道题,首先dfs一遍,在所有能到达放有干草的洞穴的所有路径中,找出路径上最小伐值的最大值,按这个值由小到大,再来一遍贪心就行了,能放就放,不能放拉倒(也可以理解为,不能放把最前一个删了) ...