solr6.6 配置自带中文分词
1、配置solrconfig.xml
solr的自带中文分词包在solr-6.6.0\contrib\analysis-extras\lucene-libs下

修改solrconfig.xml增加
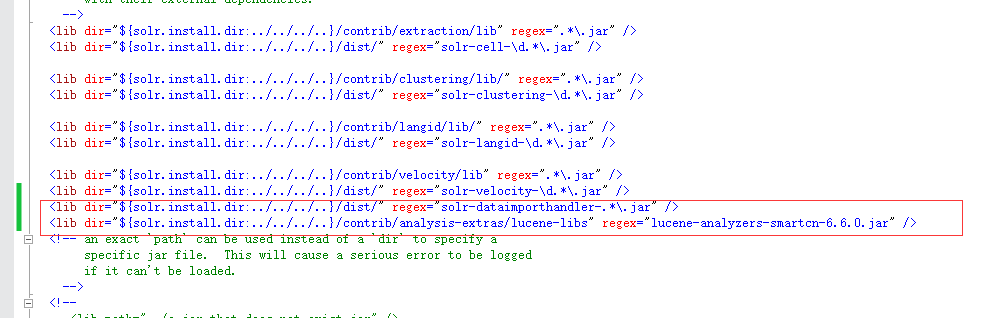
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lucene-libs" regex="lucene-analyzers-smartcn-6.6.0.jar" />
2、配置data-config.xml
建立data-config.xml文件,配置如下:
<dataConfig>
<dataSource type="BinFileDataSource"/>
<document>
<entity name="file" processor="FileListEntityProcessor" dataSource="null"
baseDir="D:/work/Solr/Import" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)"
rootEntity="false"> <field column="file" name="id"/>
<!--<field column="file" name="fileType"/>
<field column="fileSize" name="fileSize"/>
<field column="fileLastModified" name="fileLastModified"/>
<field column="fileAbsolutePath" name="fileAbsolutePath"/>-->
<entity name="pdf" processor="TikaEntityProcessor"
url="${file.fileAbsolutePath}" format="text"> <field column="Author" name="author" meta="true"/>
<!-- in the original PDF, the Author meta-field name is upper-cased,
but in Solr schema it is lower-cased
--> <field column="title" name="title" meta="true"/>
<field column="text" name="text"/>
</entity>
</entity>
</document>
</dataConfig>
再修改solrconfig.xml配置文件,增加如下内容
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
3、修改配置文件
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
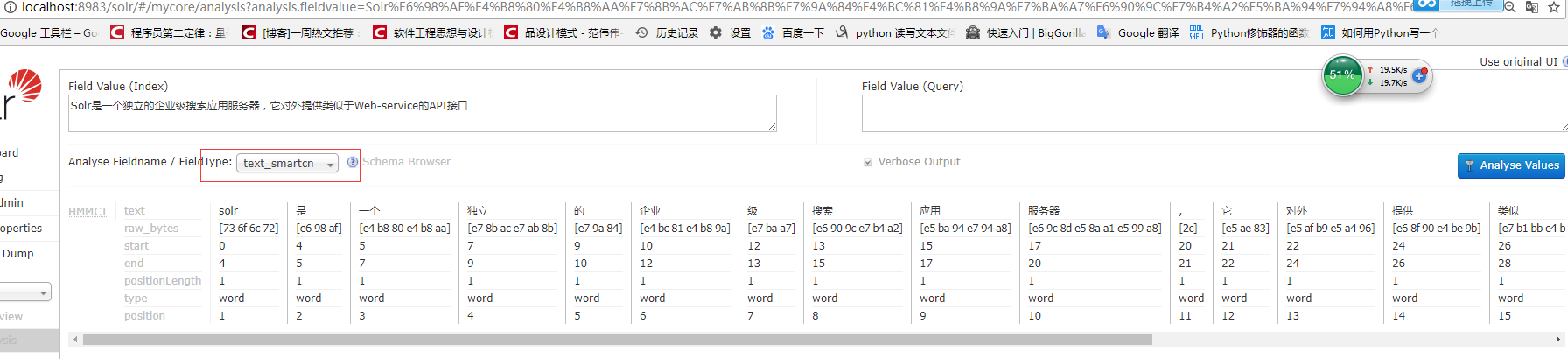
3、测试分析
solr6.6 配置自带中文分词的更多相关文章
- Solr6.6.0添加IK中文分词器
IK分词器就是一款中国人开发的,扩展性很好的中文分词器,它支持扩展词库,可以自己定制分词项,这对中文分词无疑是友好的. jar包下载链接:http://pan.baidu.com/s/1o85I15o ...
- solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程: Solr Admin中,选择Analysis,在FieldType中,选择text_en 左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词. ...
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- Solr5.5.1 IK中文分词配置与使用
前言 用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词.其中包含一个词典. 那么既然用到了这种国际化的框架,那么就避免不了中文分词.尤其是国内特殊行业比 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- (转)全文检索技术学习(三)——Lucene支持中文分词
http://blog.csdn.net/yerenyuan_pku/article/details/72591778 分析器(Analyzer)的执行过程 如下图是语汇单元的生成过程: 从一个Re ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
随机推荐
- git 提示 Please move or remove them before you can merge 解决办法
解决Git冲突造成的Please move or remove them before you can merge git clean -d -fx其中x -----删除忽略文件已经对git来说不识别 ...
- python模块之os.path
对文件路径的操作 os.path.split(p)函数返回一个路径的目录名和文件名. os.path.splitext():分离文件名与扩展名 os.path.isfile()和os.path.isd ...
- python tips:列表推导
看一个代码: a=[1,2,3,4,5,6,7,8,9] b=[5 if (i >3) else 1 for i in a] print(b) 这就是列表推导. 列表推导一般用在通过一个list ...
- rest_framework 权限流程
权限流程 权限流程与认证流程非常相似,只是后续操作稍有不同 当用户访问是 首先执行dispatch函数,当执行当第二部时: #2.处理版本信息 处理认证信息 处理权限信息 对用户的访问频率进行限制 s ...
- centos6.5 安装stardict 出现问题 [Errno 256] No more mirrors to try
1. 下载startdict #wget http://downloads.naulinux.ru/pub/NauLinux/6x/i386/sites/School/RPMS/stardict-3. ...
- 计蒜客 31458.Features Track-滚动数组+STL(map)连续计数 (ACM-ICPC 2018 徐州赛区网络预赛 F)
F. Features Track Morgana is learning computer vision, and he likes cats, too. One day he wants to f ...
- POJ1861 Network(Kruskal)(并查集)
Network Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 16047 Accepted: 6362 Spec ...
- Jenkins一个任务下载多个git库代码
公司的项目是微服务架构,一个服务对应的一个git仓库,现在的需求时拉取所有仓库代码下来,指定父级的pom.xml,一次性构建打包 jenkins在默认情况下,一个任务只能配置一个git仓库地址 1.安 ...
- Longest Absolute File Path -- LeetCode
Suppose we abstract our file system by a string in the following manner: The string "dir\n\tsub ...
- 【费用流】【Next Array】费用流模板(spfa版)
#include<cstdio> #include<algorithm> #include<cstring> #include<queue> using ...