tensorflow笔记:流程,概念和简单代码注释
tensorflow是google在2015年开源的深度学习框架,可以很方便的检验算法效果。这两天看了看官方的tutorial,极客学院的文档,以及综合tensorflow的源码,把自己的心得整理了一下,作为自己的备忘录。
tensorflow笔记系列:
(一) tensorflow笔记:流程,概念和简单代码注释
(二) tensorflow笔记:多层CNN代码分析
(三) tensorflow笔记:多层LSTM代码分析
(四) tensorflow笔记:常用函数说明
(五) tensorflow笔记:模型的保存与训练过程可视化
(六)tensorflow笔记:使用tf来实现word2vec
1.tensorflow的运行流程
tensorflow的运行流程主要有2步,分别是构造模型和训练。
在构造模型阶段,我们需要构建一个图(Graph)来描述我们的模型。所谓图,也可以理解为流程图,就是将数据的输入->中间处理->输出的过程表示出来,就像下面这样。
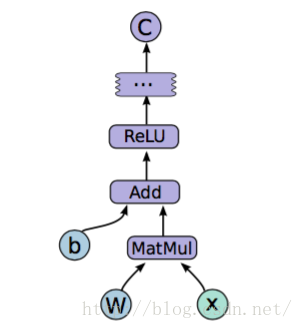
注意此时是不会发生实际运算的。而在模型构建完毕以后,会进入训练步骤。此时才会有实际的数据输入,梯度计算等操作。那么,如何构建抽象的模型呢?这里就要提到tensorflow中的几个概念:Tensor,Variable,placeholder,而在训练阶段,则需要介绍Session。下面先解释一些上面的几个概念
1.1概念描述
1.1.1 Tensor
Tensor的意思是张量,不过按我的理解,其实就是指矩阵。也可以理解为tensorflow中矩阵的表示形式。Tensor的生成方式有很多种,最简单的就如
import tensorflow as tf # 在下面所有代码中,都去掉了这一行,默认已经导入
a = tf.zeros(shape=[1,2])不过要注意,因为在训练开始前,所有的数据都是抽象的概念,也就是说,此时a只是表示这应该是个1*5的零矩阵,而没有实际赋值,也没有分配空间,所以如果此时print,就会出现如下情况:
print(a)
#===>Tensor("zeros:0", shape=(1, 2), dtype=float32)只有在训练过程开始后,才能获得a的实际值
sess = tf.InteractiveSession()
print(sess.run(a))
#===>[[ 0. 0.]]这边设计到Session概念,后面会提到
1.1.2 Variable
故名思议,是变量的意思。一般用来表示图中的各计算参数,包括矩阵,向量等。例如,我要表示上图中的模型,那表达式就是
(relu是一种激活函数,具体可见这里)这里W和b是我要用来训练的参数,那么此时这两个值就可以用Variable来表示。Variable的初始函数有很多其他选项,这里先不提,只输入一个Tensor也是可以的
W = tf.Variable(tf.zeros(shape=[1,2]))注意,此时W一样是一个抽象的概念,而且与Tensor不同,Variable必须初始化以后才有具体的值。
tensor = tf.zeros(shape=[1,2])
variable = tf.Variable(tensor)
sess = tf.InteractiveSession()
# print(sess.run(variable)) # 会报错
sess.run(tf.initialize_all_variables()) # 对variable进行初始化
print(sess.run(variable))
#===>[[ 0. 0.]]1.1.3 placeholder
又叫占位符,同样是一个抽象的概念。用于表示输入输出数据的格式。告诉系统:这里有一个值/向量/矩阵,现在我没法给你具体数值,不过我正式运行的时候会补上的!例如上式中的x和y。因为没有具体数值,所以只要指定尺寸即可
x = tf.placeholder(tf.float32,[1, 5],name='input')
y = tf.placeholder(tf.float32,[None, 5],name='input')- 1
- 2
- 1
- 2
上面有两种形式,第一种x,表示输入是一个[1,5]的横向量。
而第二种形式,表示输入是一个[?,5]的矩阵。那么什么情况下会这么用呢?就是需要输入一批[1,5]的数据的时候。比如我有一批共10个数据,那我可以表示成[10,5]的矩阵。如果是一批5个,那就是[5,5]的矩阵。tensorflow会自动进行批处理
1.1.4 Session
session,也就是会话。我的理解是,session是抽象模型的实现者。为什么之前的代码多处要用到session?因为模型是抽象的嘛,只有实现了模型以后,才能够得到具体的值。同样,具体的参数训练,预测,甚至变量的实际值查询,都要用到session,看后面就知道了
1.2 模型构建
这里我们使用官方tutorial中的mnist数据集的分类代码,公式可以写作
那么该模型的代码描述为
# 建立抽象模型
x = tf.placeholder(tf.float32, [None, 784]) # 输入占位符
y = tf.placeholder(tf.float32, [None, 10]) # 输出占位符(预期输出)
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
a = tf.nn.softmax(tf.matmul(x, W) + b) # a表示模型的实际输出
# 定义损失函数和训练方法
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y * tf.log(a), reduction_indices=[1])) # 损失函数为交叉熵
optimizer = tf.train.GradientDescentOptimizer(0.5) # 梯度下降法,学习速率为0.5
train = optimizer.minimize(cross_entropy) # 训练目标:最小化损失函数可以看到这样以来,模型中的所有元素(图结构,损失函数,下降方法和训练目标)都已经包括在train里面。我们可以把train叫做训练模型。那么我们还需要测试模型
correct_prediction = tf.equal(tf.argmax(a, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))上述两行代码,tf.argmax表示找到最大值的位置(也就是预测的分类和实际的分类),然后看看他们是否一致,是就返回true,不是就返回false,这样得到一个boolean数组。tf.cast将boolean数组转成int数组,最后求平均值,得到分类的准确率(怎么样,是不是很巧妙)
1.3 实际训练
有了训练模型和测试模型以后,我们就可以开始进行实际的训练了
sess = tf.InteractiveSession() # 建立交互式会话
tf.initialize_all_variables().run() # 所有变量初始化
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100) # 获得一批100个数据
train.run({x: batch_xs, y: batch_ys}) # 给训练模型提供输入和输出
print(sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}))可以看到,在模型搭建完以后,我们只要为模型提供输入和输出,模型就能够自己进行训练和测试了。中间的求导,求梯度,反向传播等等繁杂的事情,tensorflow都会帮你自动完成。
2. 实际代码
实际操作中,还包括了获取数据的代码
"""A very simple MNIST classifier.
See extensive documentation at
http://tensorflow.org/tutorials/mnist/beginners/index.md
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
# Import data
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('data_dir', '/tmp/data/', 'Directory for storing data') # 把数据放在/tmp/data文件夹中
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) # 读取数据集
# 建立抽象模型
x = tf.placeholder(tf.float32, [None, 784]) # 占位符
y = tf.placeholder(tf.float32, [None, 10])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
a = tf.nn.softmax(tf.matmul(x, W) + b)
# 定义损失函数和训练方法
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y * tf.log(a), reduction_indices=[1])) # 损失函数为交叉熵
optimizer = tf.train.GradientDescentOptimizer(0.5) # 梯度下降法,学习速率为0.5
train = optimizer.minimize(cross_entropy) # 训练目标:最小化损失函数
# Test trained model
correct_prediction = tf.equal(tf.argmax(a, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# Train
sess = tf.InteractiveSession() # 建立交互式会话
tf.initialize_all_variables().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train.run({x: batch_xs, y: batch_ys})
print(sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}))得到的分类准确率在91%左右
转载来自:http://blog.csdn.net/u014595019/article/details/52677412
tensorflow笔记:流程,概念和简单代码注释的更多相关文章
- tensorflow笔记:多层LSTM代码分析
tensorflow笔记:多层LSTM代码分析 标签(空格分隔): tensorflow笔记 tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) ten ...
- tensorflow笔记:多层CNN代码分析
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- tensorflow笔记:使用tf来实现word2vec
(一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 (四) tensorflow笔 ...
- tensorflow笔记:模型的保存与训练过程可视化
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- (四) tensorflow笔记:常用函数说明
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- tensorflow学习笔记——常见概念的整理
TensorFlow的名字中已经说明了它最重要的两个概念——Tensor和Flow.Tensor就是张量,张量这个概念在数学或者物理学中可以有不同的解释,但是这里我们不强调它本身的含义.在Tensor ...
- tensorflow笔记(二)之构造一个简单的神经网络
tensorflow笔记(二)之构造一个简单的神经网络 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7425200.html ...
- Qt简单项目--加法计算器(详细代码注释)
Qt的简单案例--加法计算器(详细代码注释) 一.项目结构 二.项目代码 widget.h #ifndef WIDGET_H #define WIDGET_H //预编译指令, 为了避免头文件被重复包 ...
- 《从零开始学Swift》学习笔记(Day 57)——Swift编码规范之注释规范:文件注释、文档注释、代码注释、使用地标注释
原创文章,欢迎转载.转载请注明:关东升的博客 前面说到Swift注释的语法有两种:单行注释(//)和多行注释(/*...*/).这里来介绍一下他们的使用规范. 1.文件注释 文件注释就在每一个文件开头 ...
随机推荐
- Mybatis+MySql 一个标签中执行多条sql语句 这个坑 ,我心中有一句MMP
解决办法 转自网友: 亲测 解决了问题@ MySql默认是不支持这种骚操作的,但是并不代表不能实现,只需要在jdbc的配置文件中稍做配置: driver=com.mysql.jdbc.Driverur ...
- Docker selinux
编辑/etc/sysconfig/docker文件,把OPTIONS='--selinux-enabled'的--selinux-enabled注释掉,也可以通过这个错误. 最大的问题就是Linux的 ...
- python面试题(六)
1 异常处理写法以及如何主动跑出异常(应用场景) try: """执行语句""" except: #异常类型 ""&qu ...
- Map.Entry<K,V>分析
一.好处 你是否已经对每次从Map中取得关键字然后再取得相应的值感觉厌倦? Set keys = map.keySet( ); if(keys != null) { Iterator iterator ...
- 004-mysql explain详解
一.使用 使用explain + 查询语句 二.解释说明 1)id列[执行顺序] id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它 ...
- Linux:文件系统
Linux:文件系统 分区与文件系统 对分区进行格式化是为了在分区上建立文件系统.一个分区通常只能格式化为一个文件系统,但是磁盘阵列等技术可以将一个分区格式化为多个文件系统. 组成 最主要的组成部分如 ...
- 使用idea2016导出web项目war包
第一步配置Web Application:Exploded(已经配置的可以跳到第二步): 打开project structure(默认的快捷键是Ctrl+Alt+Shift+S),依次选择Artifa ...
- 【转】Linux rpm 安装卸载操作
rpm 是红帽(RedHat)软件包管理工具,实现类似于 Windows 中的添加/删除程序功能.下面,就来向大家介绍 rpm 命令的用法. 1. 安装rpm包: rpm -ivh 软件包名 安装软件 ...
- iOS NSCoding 的学习 和 使用
起初接触的轻量级 物理存储 方式 是 plist 可以存储 系统级别的 字典 数组 但是不能存储自定义的对象类 那会 用自定义对象做存储的 需求也不大 主要 是 还没建立面向对象意识,会的也少. ...
- Js 类型方面的神坑
你有没有遇见过本来好好的一个数组结果 typeof 出来是个 object 的情况,你有没有遇到过非要写个 typeof x === "undefined" 判断未赋值的情况... ...