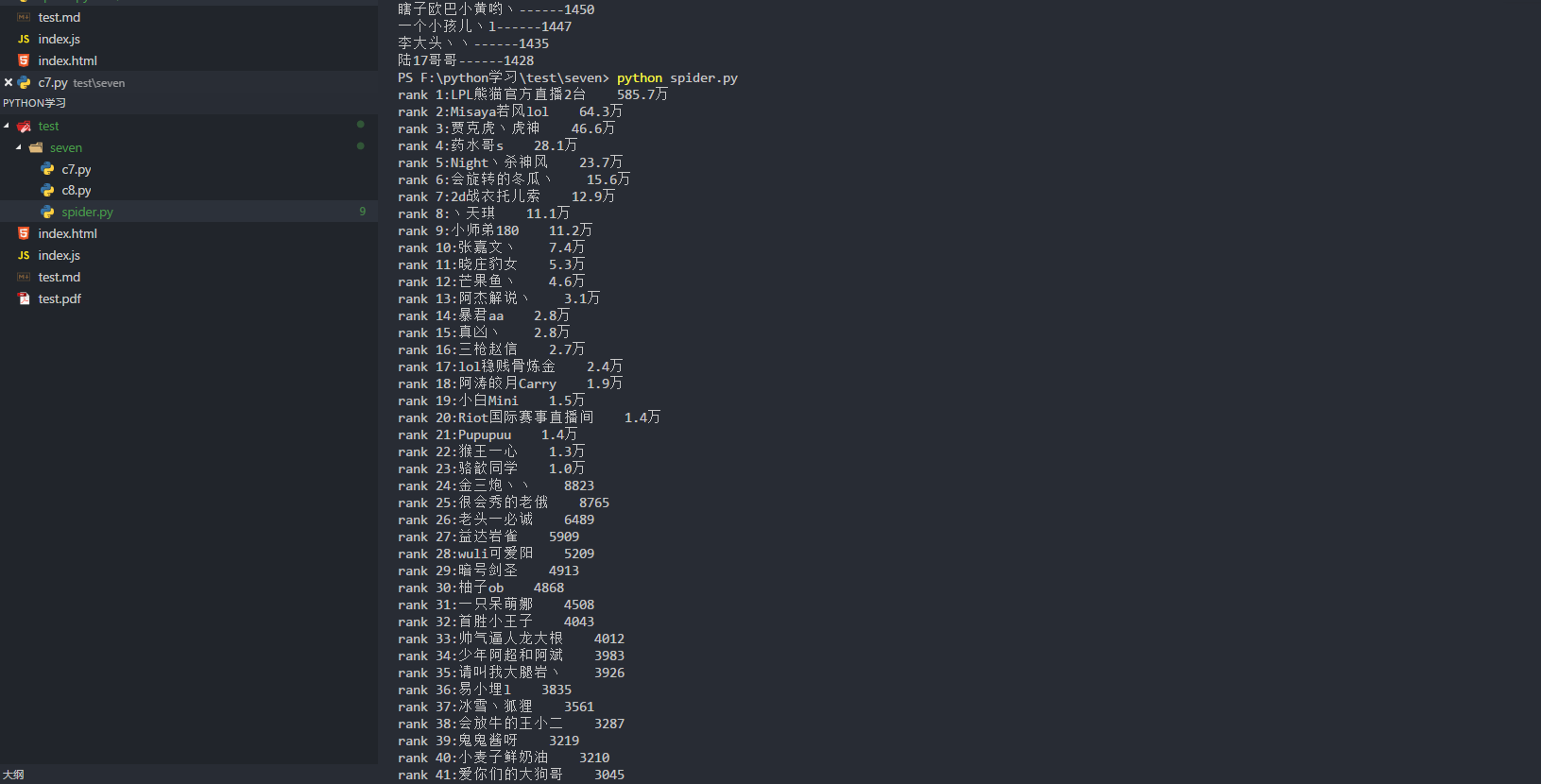
python实战之原生爬虫(爬取熊猫主播排行榜)
"""
this is a module,多行注释
"""
import re
from urllib import request
# BeautifulSoup:解析数据结构 推荐库 Scrapy:爬虫框架
#爬虫,反爬虫,反反爬虫
#ip 封
#代理ip库
class Spider():
url='https://www.panda.tv/cate/lol'
root_pattern='<div class="video-info">([\s\S]*?)</div>'
name_pattern='</i>([\s\S]*?)</span>'
number_pattern='<span class="video-number">([\s\S]*?)</span>'
def __fetch_content(self):
r=request.urlopen(Spider.url)
htmls=r.read()
htmls=str(htmls,encoding='utf-8')
return htmls
a=1
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html)
number=re.findall(Spider.number_pattern,html)
anchor={'name':name,'number':number}
anchors.append(anchor)
return anchors
def __refine(self,achors):
l=lambda anchor:{'name':anchor['name'][0].strip(),'number':anchor['number'][0]}
return map(l,achors)
def __sort(self,anchors):
anchors=sorted(anchors,key=self.__sord_seed,reverse=True)
return anchors
def __show(self,anchors):
for rank in range(0,len(anchors)):
print('rank '+str(rank+1)+':'+anchors[rank]['name']
+' '+anchors[rank]['number']
)
def __sord_seed(self,anchor):
r=re.findall('\d*',anchor['number'])
number= float(r[0])
if '万' in anchor['number']:
number*=10000
return number
def go(self):
htmls=self.__fetch_content()
anchors=self.__analysis(htmls)
anchors=list(self.__refine(anchors))
anchors=self.__sort(anchors)
self.__show(anchors)
splider=Spider()
splider.go()
python实战之原生爬虫(爬取熊猫主播排行榜)的更多相关文章
- 『Scrapy』爬取斗鱼主播头像
分析目标 爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣...... 目标URL如下, ...
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- 爬虫之selenium爬取斗鱼主播图片
这是我GitHub上简单的selenium介绍与简单使用:https://github.com/bwyt/spider/tree/master/selenium%E5%9F%BA%E7%A1%80 & ...
- selenium,webdriver爬取斗鱼主播信息 实操
from selenium import webdriver import time from bs4 import BeautifulSoup class douyuSelenium(): #初始化 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取京东、淘宝、苏宁上华为P20购买评论
爬虫爬取京东.淘宝.苏宁上华为P20购买评论 1.使用软件 Anaconda3 2.代码截图 三个网站代码大同小异,因此只展示一个 3.结果(部分) 京东 淘宝 苏宁 4.分析 这三个网站上的评论数据 ...
随机推荐
- [菜鸟]HTTP 与 HTTPS 的区别
HTTP 与 HTTPS 的区别 分类 编程技术 基本概念 HTTP(HyperText Transfer Protocol:超文本传输协议)是一种用于分布式.协作式和超媒体信息系统的应用层协议. 简 ...
- 【bzoj5118】Fib数列2 费马小定理+矩阵乘法
题目描述 Fib定义为Fib(0)=0,Fib(1)=1,对于n≥2,Fib(n)=Fib(n-1)+Fib(n-2) 现给出N,求Fib(2^n). 输入 本题有多组数据.第一行一个整数T,表示数据 ...
- Day18-前端和后端怎么区分
前端 - 通常是针对浏览器而开发的,是在浏览器端运行的程序,而后端 - 针对的是服务器,准确的来说应该是服务器端开发.前端开发偏向于用户体验,比较直观,服务器端开发偏向于性能. 前端和后端指的是网站建 ...
- OAuth2的基本概念的理解
书籍推荐 OAuth2 in Action -- 原理 OAuth2 Cookbook -- 实践 OAuth2 解决的问题域 开放系统间授权 社交联合登录 开放API平台 现代微服务安全 单页浏览器 ...
- (转)win下修改jdk环境变量后,java版本不变 java -version
背景:在windows下安装了多个版本的jdk,发现修改环境变量无法切换. win 7环境下修改JAVA_HOME后,在命令行执行:java -version 发现版本没有变化,以为需要重启才行,就把 ...
- acm 比赛模板
C++模板 A-M https://pan.baidu.com/s/1lqR1s5RcAR52UJLYNfmRTQ C++模板 1-13 https://pan.baidu.com/s/1361ShU ...
- string::replace
#include <string> #include <cctype> #include <algorithm> #include <iostream> ...
- 口琴练习部分 - 多孔单音奏法 & 简单伴奏
多孔单音奏法(口含5个孔) 加入伴奏 理论知识 - 盖住 理论知识 - 松开 舌头一抬一合形成一个伴奏 高级一点的伴奏练习 正拍伴奏: 当要吹吸某一个音时,舌头先离开琴格,然后迅速盖上.
- Openstack 网络服务 Neutron计算节点部署(十)
Neutron计算节点部署 安装组件,安装的服务器是192.168.137.12 1.安装软件包 yum install -y openstack-neutron-linuxbridge ebtabl ...
- IE盒模型和W3C盒子模型的区别
其实这个问题到现在真的是没有意义了,因为早在IE6的兼容模式开始就已经弃用了IE盒子模型了,但是现在的各种面试题还是会时常出现这样的上世纪的题目,我觉得其实时纯粹的刁难. 好了,吐槽不多说了,直接上图 ...