如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入。
一、代码实现
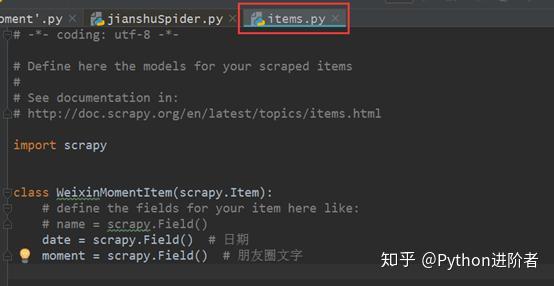
1、修改Scrapy项目中的items.py文件。我们需要获取的数据是朋友圈和发布日期,因此在这里定义好日期和动态两个属性,如下图所示。
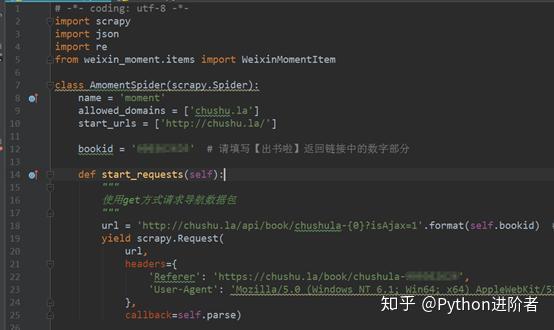
2、修改实现爬虫逻辑的主文件moment.py,首先要导入模块,尤其是要主要将items.py中的WeixinMomentItem类导入进来,这点要特别小心别被遗漏了。之后修改start_requests方法,具体的代码实现如下图。
3、修改parse方法,对导航数据包进行解析,代码实现稍微复杂一些,如下图所示。
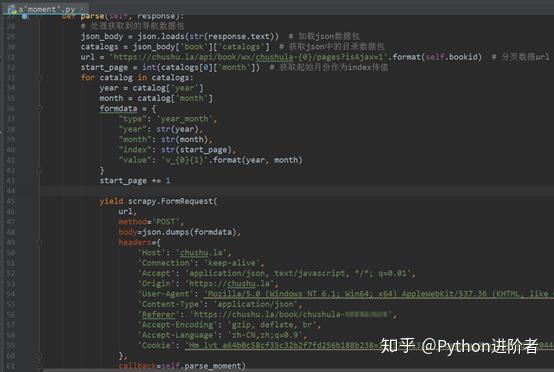
- l需要注意的是从网页中获取的response是bytes类型,需要显示的转为str类型才可以进行解析,否则会报错。
- l在POST请求的限定下,需要构造参数,需要特别注意的是参数中的年、月和索引都需要是字符串类型的,否则服务器会返回400状态码,表示请求参数错误,导致程序运行的时候报错。
- l在请求参数还需要加入请求头,尤其是Referer(反盗链)务必要加上,否则在重定向的时候找不到网页入口,导致报错。
- l上述的代码构造方式并不是唯一的写法,也可以是其他的。
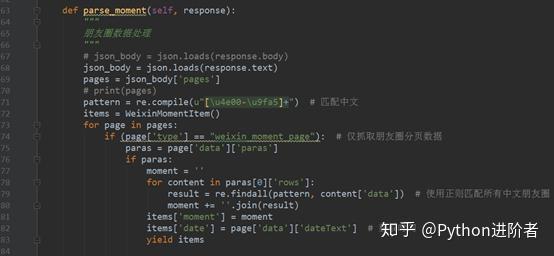
4、定义parse_moment函数,来抽取朋友圈数据,返回的数据以JSON加载的,用JSON去提取数据,具体的代码实现如下图所示。
5、在setting.py文件中将ITEM_PIPELINES取消注释,表示数据通过该管道进行处理。
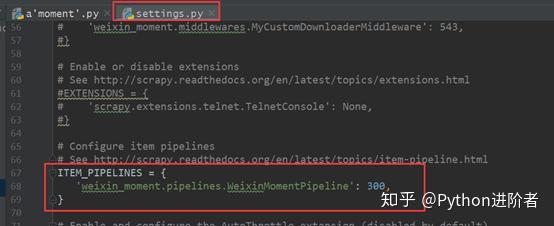
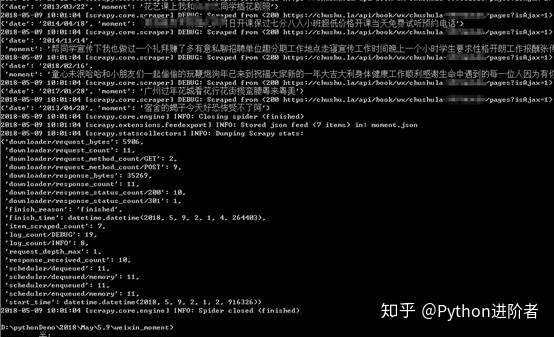
6、之后就可以在命令行中进行程序运行了,在命令行中输入scrapy crawl moment -o moment.json,之后可以得到朋友圈的数据,在控制台上输出的信息如下图所示。
7、尔后我们得到一个moment.json文件,里面存储的是我们朋友圈数据,如下图所示。
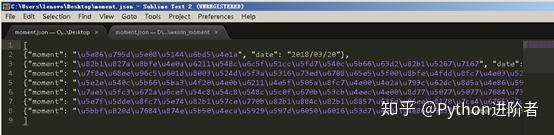
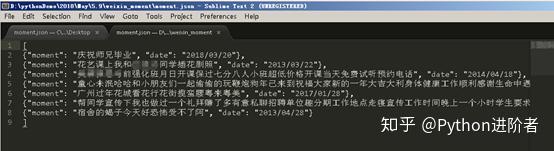
8、嗯,你确实没有看错,里边得到的数据确实让人看不懂,但是这个并不是乱码,而是编码的问题。解决这个问题的方式是将原来的moment.json文件删除,之后重新在命令行中输入下面的命令:scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,此时可以看到编码问题已经解决了,如下图所示。
下一篇文章,小编带大家将抓取到的朋友圈数据进行可视化展示,敬请关注~~
如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)的更多相关文章
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1& ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
随机推荐
- 【一天一道LeetCode】#47. Permutations II
一天一道LeetCode系列 (一)题目 Given a collection of numbers that might contain duplicates, return all possibl ...
- (三十)PickerView文字和随机数的使用
PickerView用于展示供选择的内容(例如日期选取.点菜等). 有三种情况: 1.每一列都是独立的选取 2.右边的列受到左边列的影响 3.包含图片 PickerView和TableView类似,通 ...
- CRM导入组织报实例名称必须与计算机名称相同的问题
今天采用P2V拷贝了一台CRM数据库到虚机上,因为要加域必须得把计算机名改了,然后再重新导入组织的时候报错了:"实例名称必须与计算机名称相同",google了下没有匹配的问题答案, ...
- SpriteBuilder中的CCSprite9Slice是个什么鬼?
CCSprite大家都知道,但是加上后面那一串又变成了神马呢? 我们可以首先到官方的API文档网站查一下,如下: http://www.cocos2d-swift.org/docs/api/Class ...
- C语言字符串的常见特殊操作(除了string.c实现的那些接口)
字符串操作中,必须掌握的一些之前已经在文章有写过了,比如说字符串查找,字符串粘帖,字符串拷贝等等,这些在标准C库的string.c中已经有实现,故包含#include <string.h> ...
- C语言在linux内核中do while(0)妙用之法
为什么说do while(0) 妙?因为它的确就是妙,而且在linux内核中实现是相当的妙,我们来看看内核中的相关代码: #define db_error(fmt, ...) \ do { \ fpr ...
- java开发中几种常见的线程池
线程池 java.util.concurrent:Class Executors 常用线程池 几种常用的的生成线程池的方法: newCachedThreadPool newFixedThreadPoo ...
- The 14th tip of DB Query Analyzer
The 14th tip of DB Query Analyzer Ma Genfeng (Guangdong Unitoll Services incorporated, Guangzhou 5 ...
- Github上的原文XMPP环境搭建步骤,英语能力差不多的可以看看
Getting started using XMPPFramework on iOS Here is a post on StackOverflow describing how to install ...
- 恶补web之六:javascript知识(1)
javascript(下称js)是一种轻量级编程语言,它可以插入html页面然后由浏览器执行. document.write("<h1>...</h1>") ...