python实战之原生爬虫(爬取熊猫主播排行榜)
"""
this is a module,多行注释
"""
import re
from urllib import request
# BeautifulSoup:解析数据结构 推荐库 Scrapy:爬虫框架
#爬虫,反爬虫,反反爬虫
#ip 封
#代理ip库
class Spider():
url='https://www.panda.tv/cate/lol'
root_pattern='<div class="video-info">([\s\S]*?)</div>'
name_pattern='</i>([\s\S]*?)</span>'
number_pattern='<span class="video-number">([\s\S]*?)</span>'
def __fetch_content(self):
r=request.urlopen(Spider.url)
htmls=r.read()
htmls=str(htmls,encoding='utf-8')
return htmls
a=1
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html)
number=re.findall(Spider.number_pattern,html)
anchor={'name':name,'number':number}
anchors.append(anchor)
return anchors
def __refine(self,achors):
l=lambda anchor:{'name':anchor['name'][0].strip(),'number':anchor['number'][0]}
return map(l,achors)
def __sort(self,anchors):
anchors=sorted(anchors,key=self.__sord_seed,reverse=True)
return anchors
def __show(self,anchors):
for rank in range(0,len(anchors)):
print('rank '+str(rank+1)+':'+anchors[rank]['name']
+' '+anchors[rank]['number']
)
def __sord_seed(self,anchor):
r=re.findall('\d*',anchor['number'])
number= float(r[0])
if '万' in anchor['number']:
number*=10000
return number
def go(self):
htmls=self.__fetch_content()
anchors=self.__analysis(htmls)
anchors=list(self.__refine(anchors))
anchors=self.__sort(anchors)
self.__show(anchors)
splider=Spider()
splider.go()
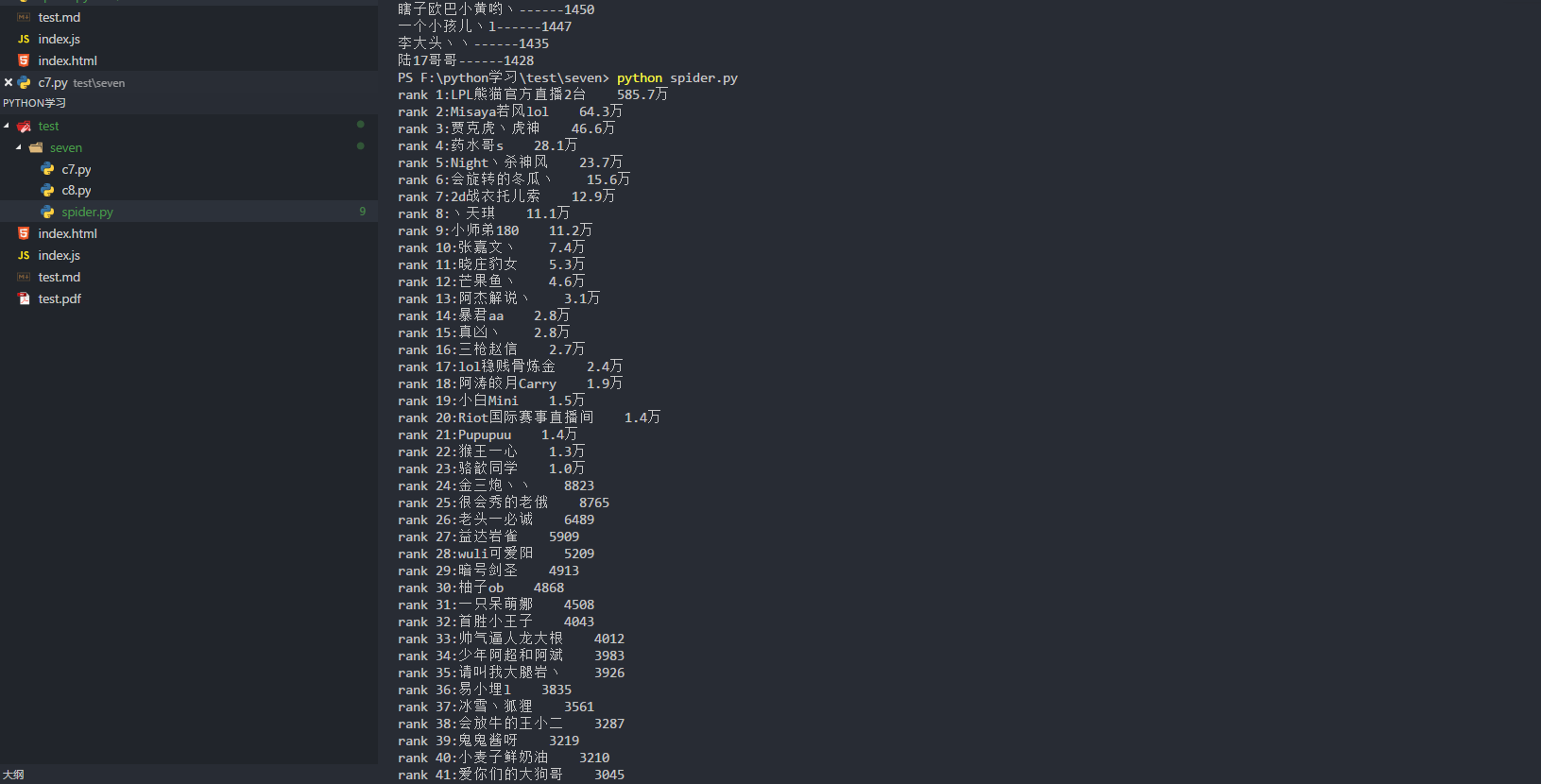
python实战之原生爬虫(爬取熊猫主播排行榜)的更多相关文章
- 『Scrapy』爬取斗鱼主播头像
分析目标 爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣...... 目标URL如下, ...
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- 爬虫之selenium爬取斗鱼主播图片
这是我GitHub上简单的selenium介绍与简单使用:https://github.com/bwyt/spider/tree/master/selenium%E5%9F%BA%E7%A1%80 & ...
- selenium,webdriver爬取斗鱼主播信息 实操
from selenium import webdriver import time from bs4 import BeautifulSoup class douyuSelenium(): #初始化 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取京东、淘宝、苏宁上华为P20购买评论
爬虫爬取京东.淘宝.苏宁上华为P20购买评论 1.使用软件 Anaconda3 2.代码截图 三个网站代码大同小异,因此只展示一个 3.结果(部分) 京东 淘宝 苏宁 4.分析 这三个网站上的评论数据 ...
随机推荐
- golang yaml配置文件解析
yaml文件语法 此模块内容转自:http://www.ruanyifeng.com/blog/2016/07/yaml.html 大小写敏感 使用缩进表示层级关系 缩进时不允许使用Tab键,只允许使 ...
- mybatis 注解和xml 优缺点
xml: 增加了xml文件,修改麻烦,条件不确定(ifelse判断),容易出错,特殊转义字符比如大于小于 注释: 复杂sql不好用,搜集sql不方便,管理不方便,修改需重新编译 #和$区别: 相同 都 ...
- SpringBoot 1.快速搭建一个 SpringBoot Maven工程
一.新建一个Maven工程 (1)选择创建简单MAVNE工程 (2)输入你自己的MAVEN工程的Group Id(必填).Artifact Id(必填).Version(必填).Packaging(必 ...
- Latex使用:在latex中添加算法模块
在Miktex下有三个latex algorithm包,分别为:algorithm,algorithmic,algorithm2e三个,其中algorithm,algorithmic经常成套使用: l ...
- 1019C Sergey's problem(思维)
题意: 找出来一个点集S 使得S中的点不能互相通过一步到达 并且S中的点 可以在小于等于2的步数下到达所有的点 要父结点 不要子结点 这样就求出来一个点集S‘ 而S'中可能存在 v -> u ...
- c++11 追踪返回类型
c++11 追踪返回类型 返回类型后置:使用"->"符号,在函数名和参数列表后面指定返回类型. #define _CRT_SECURE_NO_WARNINGS #includ ...
- oracle 获取当前用户下的所有表名与字段信息
select *from user_col_commentswhere substr(table_name,1,3)<>'BIN'
- MT【112】单变量化
评:降维,单变量是我们不懈的追求
- c# yield关键字原理详解
c# yield关键字的用法 1.yield实现的功能 yield return: 先看下面的代码,通过yield return实现了类似用foreach遍历数组的功能,说明yield return也 ...
- 《Linux命令行与shell脚本编程大全》23章24章
第二十三章 使用其他shell bash shell是linux发行版中最广泛使用的shell.但是它并不是唯一的选择,还有其他的shell可以供你选择. 23.1 什么是dash shell 百度百 ...