通过 Pulsar 源码彻底解决重复消费问题

背景
最近真是和 Pulsar 杠上了,业务团队反馈说是线上有个应用消息重复消费。

而且在测试环境是可以稳定复现的,根据经验来看一般能稳定复现的都比较好解决。
定位问题
接着便是定位问题了,根据之前的经验让业务按照这几种情况先排查一下:
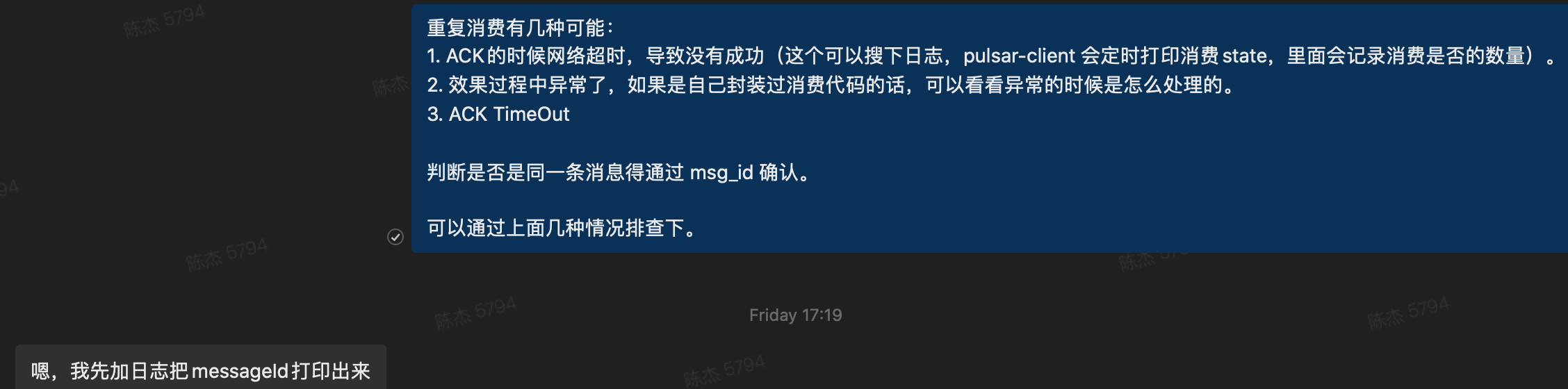
通过排查:1,2可以排除了。
- 没有相关日志
- 存在异常,但最外层也捕获了,所以不管有无异常都会 ACK。
第三个也在消费的入口和提交消息出计算了时间,最终发现都是在2s左右 ACK 的。
伪代码如下:
Consumer consumer = client.newConsumer()
.subscriptionType(SubscriptionType.Shared)
.enableRetry(true)
.topic(topic)
.ackTimeout(30, TimeUnit.SECONDS)
.subscriptionName("my-sub")
.messageListener(new MessageListener<byte[]>() {
@SneakyThrows
@Override
public void received(Consumer<byte[]> consumer, Message<byte[]> msg) {
log.info("msg_id{}",msg.getMessageId().toString());
TimeUnit.SECONDS.sleep(2);
consumer.acknowledge(msg);
}
})
.subscribe();
那这就很奇怪了,因为代码里配置的 ackTimeout 是 30s,理论上来说是不会存在超时导致消息重发的。
为了排除是否是超时引起的,直接将业务代码注释掉了,等于是消息收到后立即就 ACK,经过测试发现这样确实就没有重复消费了。
为了再次确认是不是和 ackTimeout 有关,直接将 .ackTimeout(30, TimeUnit.SECONDS) 注释掉后测试,发现也没有重复消费了。
确认原因
既然如此那一定是和这个配置有关了,但看代码确实没有超时,为了定位具体原因只有去看 client 的源码了。
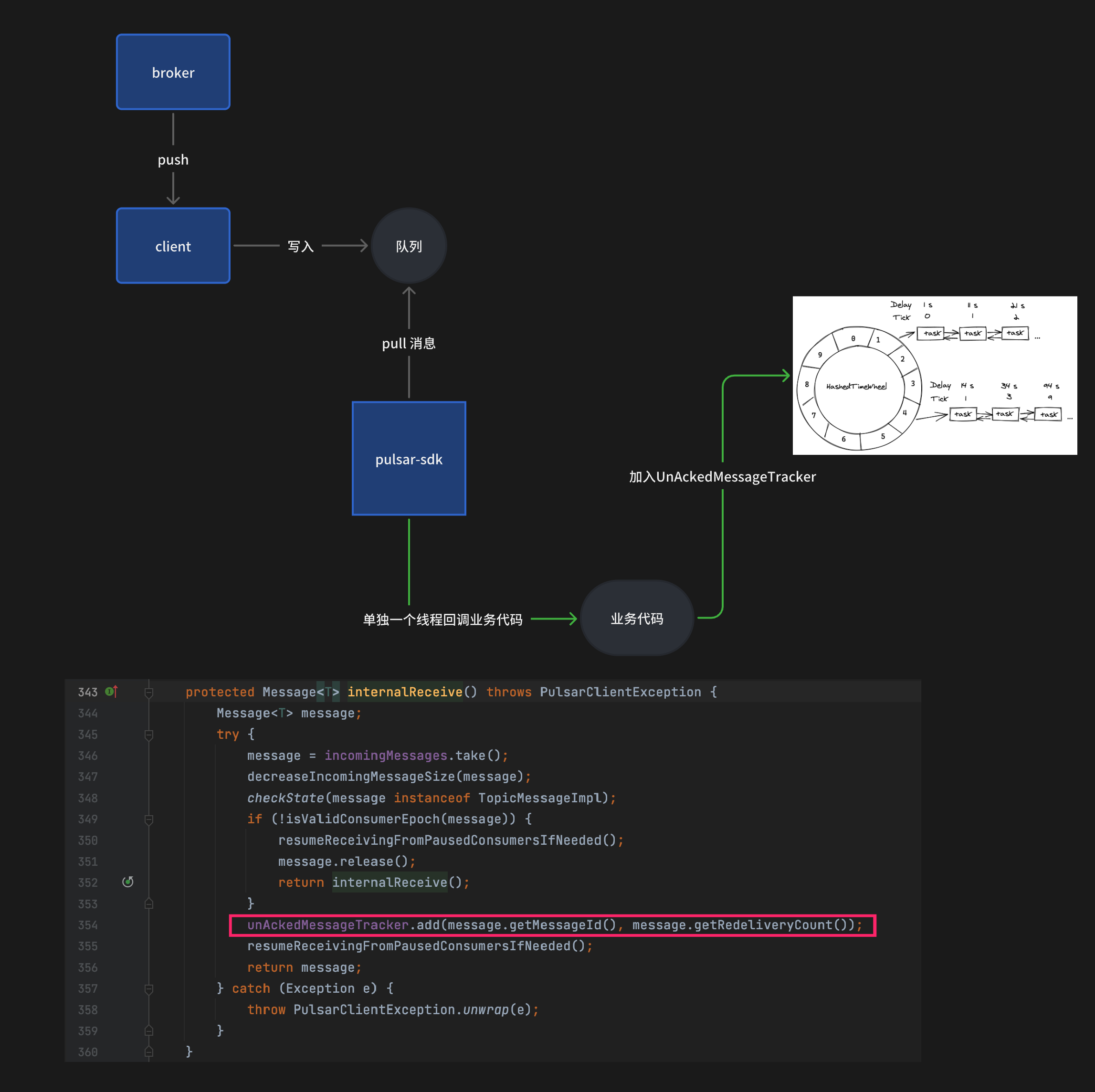
这里简单梳理下消息的消费的流程:
- 根据
.receiverQueueSize(1000)的配置,默认情况下 broker 会直接给客户端推送 1000 条消息。 - 客户端将这 1000 条消息保存到内部队列中。
- 如果使用同步消费
receive()时,本质上就是去take这个内部队列。 - 如果是使用的是
messageListener异步消费并配置ackTimeout,每当从队列里获得一条消息后便会把这条消息加入UnAckedMessageTracker内部的一个时间轮中,定时检测顶部是否存在消息,如果存在则会触发重新投递。
4.1 加入时间轮后,异步调用我们自定义的事件,这个异步操作是提交到一个无界队列中由单个线程依次排队执行(这点是这次问题的关键) - 业务 ACK 的时候会从时间轮中删除消息,所以如果消息 ACK 的足够快,在第四步就不会获取到消息进行重新投递。
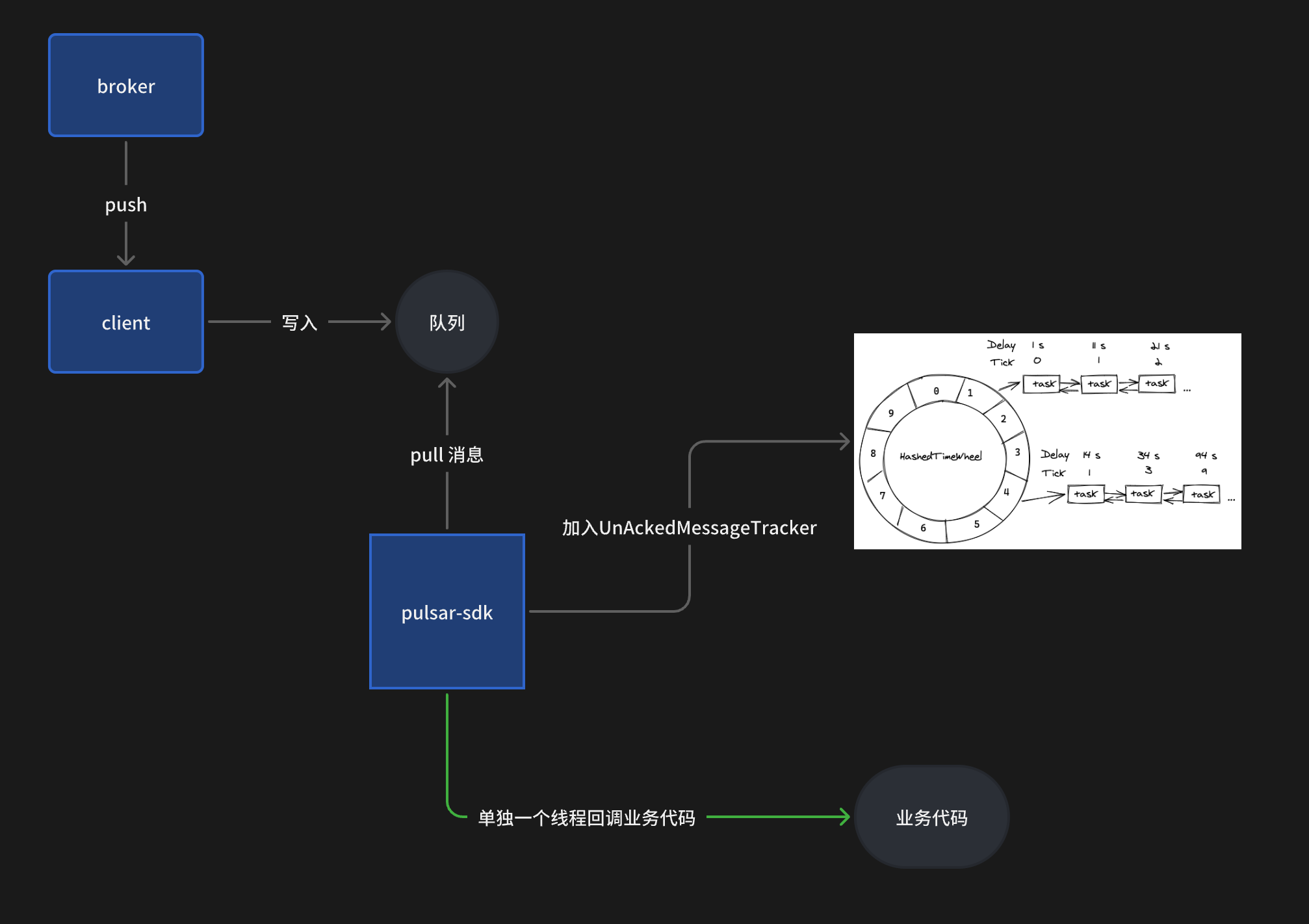
整体流程如上图,代码细节如下图:

所以问题的根本原因就是写入时间轮(UnAckedMessageTracker)开始倒计时的线程和回调业务逻辑的不是同一个线程。
如果业务执行耗时,等到消息从那个单线程的无界队列中取出来的时候很有可能已经过了 ackTimeou 的时间,从而导致了超时重发。
也就是用户所理解的 ackTimeout 周期(应该进入回调时候开始计时)和 SDK 实现的不一致造成的。
之后我再次确认同样的代码换为同步消费是没有问题的,不会导致重复消费:
while (true) {
Message msg = consumer.receive();
log.info(
"consumer Message received: " + new String(msg.getData()) + msg.getMessageId().toString());
TimeUnit.SECONDS.sleep(2);
consumer.acknowledge(msg);
}
查看代码后发现同步代码的获取消息和加入 UnAckedMessageTracker 时间轮是同步的,也就不会出现超时的问题。
总结
所以其实 是messageListener 异步消费的 ackTimeout 的语义是有问题的,需要将加入 UnAckedMessageTracker 处移动到回调函数中同步调用。
我查看了最新的 2.11.x 版本的代码依然没有修复,正准备提个 PR 切换到 master 时才发现已经有相关的 PR 了,只是还没有发版。
修复的背景和思路也是类似的,具体参考:
https://github.com/apache/pulsar/pull/18911
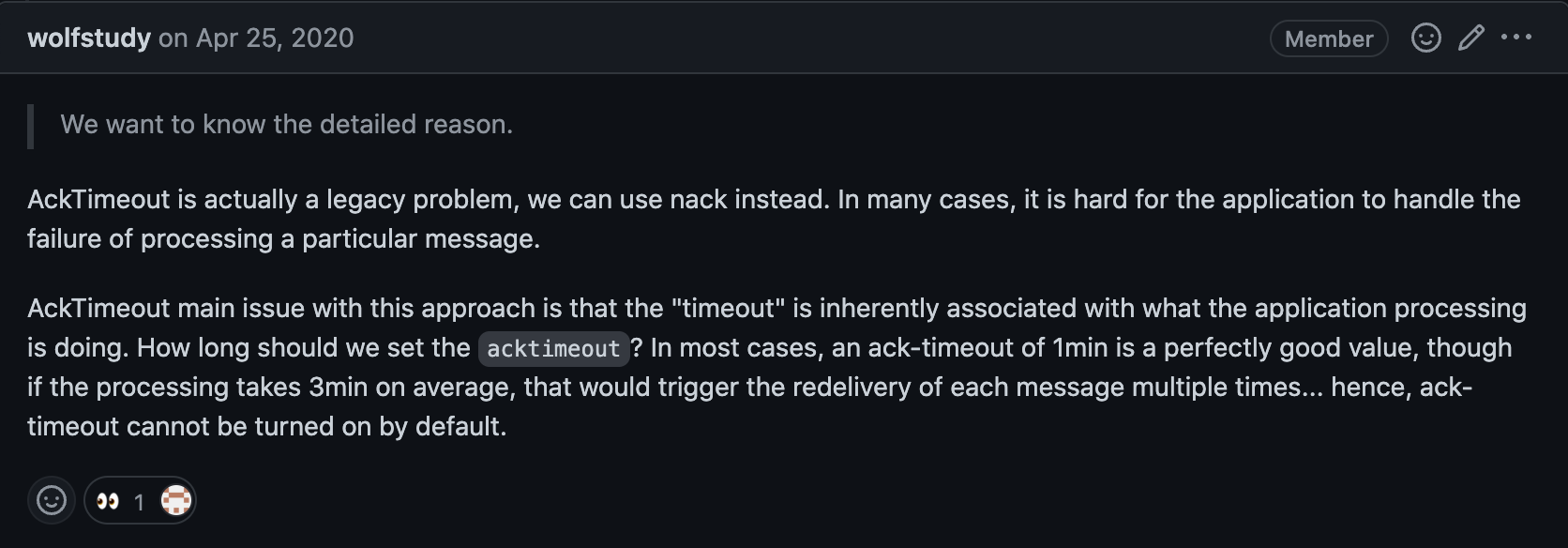
其实业务中并不推荐使用 ackTimeout 这个配置了,不好预估时间从而导致超时,而且我相信大部分业务配置好 ackTImeout 后直到后续出问题的时候才想起来要改。
所以干脆一开始就不要使用。
在 go 版本的 SDK 中直接废弃掉了这个参数,推荐使用 nack API 替换。
通过 Pulsar 源码彻底解决重复消费问题的更多相关文章
- Android Studio2.x版本无法自动关联源码的解决方法
Android Studio2.x版本无法自动关联源码的解决方法 在学习android开发过程中,对于一个不熟悉的类,阅读源码是一个很好的学习方式,使用andorid studio开发工具的SDK M ...
- 清晰易懂TCP通信原理解析(附demo、简易TCP通信库源码、解决沾包问题等)C#版
目录 说明 TCP与UDP通信的特点 TCP中的沾包现象 自定义应用层协议 TCPLibrary通信库介绍 Demo演示 未完成功能 源码下载 说明 我前面博客中有多篇文章讲到了.NET中的网络编程, ...
- jQuery源码研究——解决命名冲突
在项目中难免不去使用多个插件,如此一来这些插件就有可能出现一样的名称,当出现同名变量时后一个将会覆盖上一个,这样的话我们就无法同时使用多个插件了. 当遇到这种情况我们可以手动去修改插件源码把它的名字改 ...
- 使用myeclipse自动导入hibernate3的jar包,如何关联hibernate源码的解决办法
1.在网上找了好久,今天终于解决了,如果你的myeclipse自动生成的添加hibernate3jar包时,依靠通常的方法是无法关联其相应版本的源代码的,就是你在编写代码是,按住ctrl + hibe ...
- 源码分析Dubbo服务消费端启动流程
通过前面文章详解,我们知道Dubbo服务消费者标签dubbo:reference最终会在Spring容器中创建一个对应的ReferenceBean实例,而ReferenceBean实现了Spring生 ...
- 被Spring坑了一把,查看源码终于解决了DataFlow部署K8s应用的问题
1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! Docker & Kubernetes相关文章:容器技术 基于各种原因,团队的Kubernetes被加了限制,必须在 ...
- 探索TiDB Lightning的源码来解决发现的bug
背景 上一篇<记一次简单的Oracle离线数据迁移至TiDB过程>说到在使用Lightning导入csv文件到TiDB的时候发现了一个bug,是这样一个过程. Oracle源库中表名都是大 ...
- JGUI源码:解决手机端点击出现半透明阴影(4)
下面开始进入正题,问题发现与解决 1.According解决手机浏览器点击出现半透明阴影 手机下点击有白色蒙版,原始效果如下,看起来很不协调 2.解决办法:增加 -webkit-tap-highlig ...
- [dubbo 源码之 ]2. 服务消费方如何启动服务
启动流程 消费者在启动之后,会通过ReferenceConfig#get()来生成远程调用代理类.在get方法中,会启动一系列调用函数,我们来一个个解析. 配置同样包含2种: XML <?xml ...
- eclipse 打开其他项目的jar源码 乱码解决
步骤1.在eclipse菜单栏中,Window–>Preferences–>General–>Content types 将JAR Content , Java Class File ...
随机推荐
- 漫谈计算机网络:番外篇 ------网络安全相关知识——>公钥与私钥、防火墙与入侵检测
<漫谈计算机网络>上次已经完结啦,今天出一个番外篇! 2022-12-06 今天我们来聊一聊网络安全 废话不多说直接进入正题 网络安全问题概述 计算机网络面临的安全性威胁 两大类威胁:被动 ...
- ATM购物车项目总结
目录 项目实现思路 ATM项目 优先实现功能 拆分函数 项目路径展示 项目启动文件 start.py 配置文件 setting.py 日志配置字典 日志函数 展示层 src.py 用户注册 获取用户输 ...
- 玩转 Go 生态|Hertz WebSocket 扩展简析
WebSocket 是一种可以在单个 TCP 连接上进行全双工通信,位于 OSI 模型的应用层.WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据.在 W ...
- Jmeter 之在linux中监控Memory、CPU、I/O资源等操作方法
在做性能测试时,单纯的只看响应时间.错误率.中间值远远不够的,有时需要监控服务cpu.内存等指标来判断影响性能的瓶颈在哪. 操作步骤: 一.Linux下配置jmeter环境 1.在linux环境下安装 ...
- [OpenCV实战]35 使用Tesseract和OpenCV实现文本识别
目录 1 如何在Ubuntu和windows上安装Tesseract 1.1 在ubuntu18.04上安装Tesseract4 1.2 在Ubuntu 14.04,16.04,17.04,17.10 ...
- 时钟同步服务器ntp安装文档
应用场景 同步时钟很有必要,如果服务器的时间差过大会出现不必要的问题 大数据产生与处理系统是各种计算设备集群的,计算设备将统一.同步的标准时间用于记录各种事件发生时序, 如E-MAIL信息.文件创建和 ...
- P8844 [传智杯 #4 初赛] 小卡与落叶
简要题意 给出一个 \(n\) 个节点的以 \(1\) 为根的树,每一个节点 \(i\) 带权 \(w_i\),初始时所有节点的权均为 \(0\).有 \(m\) 个操作,支持以下操作: 1 x,对于 ...
- C# 如何发送邮件消息
1.安装NUGET包 MailKit 2.代码如下 using MailKit.Net.Smtp; using MimeKit; using System.Collections.Generic; u ...
- VBA中的(升降序)排名问题
1 Sub 升序() 2 3 all_rows = Sheets(1).Range("a65536").End(xlUp).Row 4 5 With ActiveWorkbook. ...
- Python修改柱状图边缘柱子与图边界的距离
本文介绍基于Python中matplotlib.pyplot模块,修改柱状图.条形图最两侧的柱子与图像边缘之间距离的方法. 最近,绘制了一个水平的柱状图,但是发现图的上.下边距(不是柱子与柱子 ...