基于bert_bilstm_crf的命名实体
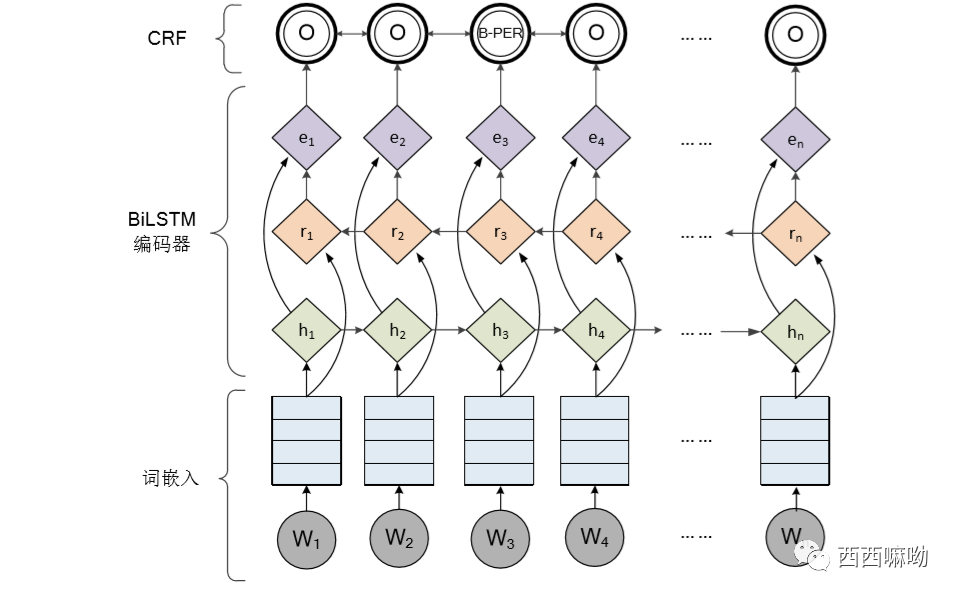
前言
本文将介绍基于pytorch的bert_bilstm_crf进行命名实体识别,涵盖多个数据集。命名实体识别指的是从文本中提取出想要的实体,本文使用的标注方式是BIOES,例如,对于文本虞兔良先生:1963年12月出生,汉族,中国国籍,无境外永久居留权,浙江绍兴人,中共党员,MBA,经济师。,我们想要提取出里面的人名,那么虞兔良可以被标记为B-NAME,I-NAME,E-NAME。最终我们要做的就是对每一个字进行分类。
代码地址:https://github.com/taishan1994/pytorch_bert_bilstm_crf_ner
数据预处理
这里我们以简历数据集为例,数据位于data/cner/raw_data下面,我们先看看初始的数据是什么样子的:
常 B-NAME
建 M-NAME
良 E-NAME
, O
男 O
, O
1 O
9 O
6 O
3 O
年 O
出 O
生 O
, O
工 B-PRO
科 E-PRO
学 B-EDU
士 E-EDU
, O
高 B-TITLE
级 M-TITLE
工 M-TITLE
程 M-TITLE
师 E-TITLE
, O
北 B-ORG
京 M-ORG
物 M-ORG
资 M-ORG
学 M-ORG
院 E-ORG
客 B-TITLE
座 M-TITLE
副 M-TITLE
教 M-TITLE
授 E-TITLE
。 O
我们先要将数据处理成通用的格式,在raw_data下新建一个process.py,具体内容是:
import os
import re
import json
def preprocess(input_path, save_path, mode):
if not os.path.exists(save_path):
os.makedirs(save_path)
data_path = os.path.join(save_path, mode + ".json")
labels = set()
result = []
tmp = {}
tmp['id'] = 0
tmp['text'] = ''
tmp['labels'] = []
# =======先找出句子和句子中的所有实体和类型=======
with open(input_path,'r',encoding='utf-8') as fp:
lines = fp.readlines()
texts = []
entities = []
words = []
entity_tmp = []
entities_tmp = []
for line in lines:
line = line.strip().split(" ")
if len(line) == 2:
word = line[0]
label = line[1]
words.append(word)
if "B-" in label:
entity_tmp.append(word)
elif "M-" in label:
entity_tmp.append(word)
elif "E-" in label:
entity_tmp.append(word)
if ("".join(entity_tmp), label.split("-")[-1]) not in entities_tmp:
entities_tmp.append(("".join(entity_tmp), label.split("-")[-1]))
labels.add(label.split("-")[-1])
entity_tmp = []
if "S-" in label:
entity_tmp.append(word)
if ("".join(entity_tmp), label.split("-")[-1]) not in entities_tmp:
entities_tmp.append(("".join(entity_tmp), label.split("-")[-1]))
entity_tmp = []
labels.add(label.split("-")[-1])
else:
texts.append("".join(words))
entities.append(entities_tmp)
words = []
entities_tmp = []
# for text,entity in zip(texts, entities):
# print(text, entity)
# print(labels)
# ==========================================
# =======找出句子中实体的位置=======
i = 0
for text,entity in zip(texts, entities):
if entity:
ltmp = []
for ent,type in entity:
for span in re.finditer(ent, text):
start = span.start()
end = span.end()
ltmp.append((type, start, end, ent))
# print(ltmp)
ltmp = sorted(ltmp, key=lambda x:(x[1],x[2]))
tmp['id'] = i
tmp['text'] = text
for j in range(len(ltmp)):
tmp['labels'].append(["T{}".format(str(j)), ltmp[j][0], ltmp[j][1], ltmp[j][2], ltmp[j][3]])
else:
tmp['id'] = i
tmp['text'] = text
tmp['labels'] = []
result.append(tmp)
# print(i, text, entity, tmp)
tmp = {}
tmp['id'] = 0
tmp['text'] = ''
tmp['labels'] = []
i += 1
with open(data_path,'w', encoding='utf-8') as fp:
fp.write(json.dumps(result, ensure_ascii=False))
if mode == "train":
label_path = os.path.join(save_path, "labels.json")
with open(label_path, 'w', encoding='utf-8') as fp:
fp.write(json.dumps(list(labels), ensure_ascii=False))
preprocess("train.char.bmes", '../mid_data', "train")
preprocess("dev.char.bmes", '../mid_data', "dev")
preprocess("test.char.bmes", '../mid_data', "test")
labels_path = os.path.join('../mid_data/labels.json')
with open(labels_path, 'r') as fp:
labels = json.load(fp)
tmp_labels = []
tmp_labels.append('O')
for label in labels:
tmp_labels.append('B-' + label)
tmp_labels.append('I-' + label)
tmp_labels.append('E-' + label)
tmp_labels.append('S-' + label)
label2id = {}
for k,v in enumerate(tmp_labels):
label2id[v] = k
path = '../mid_data/'
if not os.path.exists(path):
os.makedirs(path)
with open(os.path.join(path, "nor_ent2id.json"),'w') as fp:
fp.write(json.dumps(label2id, ensure_ascii=False))
上述代码主要是为了获得mid_data下的数据,包含labels.json:要提取的实体的类型
["PRO", "ORG", "CONT", "RACE", "NAME", "EDU", "LOC", "TITLE"]
nor_ent2id.json:每个字对应的可能的标签,由labels.json生成
{"O": 0, "B-PRO": 1, "I-PRO": 2, "E-PRO": 3, "S-PRO": 4, "B-ORG": 5, "I-ORG": 6, "E-ORG": 7, "S-ORG": 8, "B-CONT": 9, "I-CONT": 10, "E-CONT": 11, "S-CONT": 12, "B-RACE": 13, "I-RACE": 14, "E-RACE": 15, "S-RACE": 16, "B-NAME": 17, "I-NAME": 18, "E-NAME": 19, "S-NAME": 20, "B-EDU": 21, "I-EDU": 22, "E-EDU": 23, "S-EDU": 24, "B-LOC": 25, "I-LOC": 26, "E-LOC": 27, "S-LOC": 28, "B-TITLE": 29, "I-TITLE": 30, "E-TITLE": 31, "S-TITLE": 32}
需要注意的是对于不属于实体的字,我们用O进行标记。
train.json、dev.json、test.json:训练验证和测试数据
[{"id": 0, "text": "高勇:男,中国国籍,无境外居留权,", "labels": [["T0", "NAME", 0, 2, "高勇"], ["T1", "CONT", 5, 9, "中国国籍"]]}, ]
对于不同的数据集,我们都会遵循以上的结构。
接下来我们需要在hugging face下载chinese-bert-wwm-ext模型,主要是需要vocab.txt、config.json、pytorch_model.bin,放在和该项目同级的model_hub下面。然后我们就可以处理数据为bert所需要的格式了,具体内容在preprocess.py里面。这里讲下我们需要注意的一些地方:
- 我们需要定义一个datatset="cner",即我们要处理的数据名称,然后再定义一个处理该数据集的代码。基本上不同的数据基本相同,只需要修改数据的位置以及文本的最大长度,比如:
if dataset == "cner":
args.data_dir = './data/cner'
args.max_seq_len = 150
labels_path = os.path.join(args.data_dir, 'mid_data', 'labels.json')
with open(labels_path, 'r') as fp:
labels = json.load(fp)
ent2id_path = os.path.join(args.data_dir, 'mid_data')
with open(os.path.join(ent2id_path, 'nor_ent2id.json'), encoding='utf-8') as f:
ent2id = json.load(f)
id2ent = {v: k for k, v in ent2id.items()}
mid_data_path = os.path.join(args.data_dir, 'mid_data')
processor = NerProcessor(cut_sent=True, cut_sent_len=args.max_seq_len)
if use_aug:
train_data = get_data(processor, mid_data_path, "train_aug.json", "train", ent2id, labels, args)
else:
train_data = get_data(processor, mid_data_path, "train.json", "train", ent2id, labels, args)
save_file(os.path.join(mid_data_path,"cner_{}_cut.txt".format(args.max_seq_len)), train_data, id2ent)
dev_data = get_data(processor, mid_data_path, "dev.json", "dev", ent2id, labels, args)
test_data = get_data(processor, mid_data_path, "test.json", "test", ent2id, labels, args)
运行之后我们会在data/cner/final_data/下生成保存好的文件:train.pkl、dev.pkl、test.pkl。
训练、验证、测试和预测
主代码在main.py里面,具体可查看里面的代码,这里我们主要说明一下运行时的主要参数:
python main.py \
--bert_dir="../model_hub/chinese-bert-wwm-ext/" \
--data_dir="./data/cner/" \
--data_name='cner' \
--log_dir="./logs/" \
--output_dir="./checkpoints/" \
--num_tags=33 \
--seed=123 \
--gpu_ids="0" \
--max_seq_len=150 \
--lr=3e-5 \
--crf_lr=3e-2 \
--other_lr=3e-4 \
--train_batch_size=32 \
--train_epochs=3 \
--eval_batch_size=32 \
--max_grad_norm=1 \
--warmup_proportion=0.1 \
--adam_epsilon=1e-8 \
--weight_decay=0.01 \
--lstm_hidden=128 \
--num_layers=1 \
--use_lstm='False' \
--use_crf='True' \
--dropout_prob=0.3 \
--dropout=0.3 \
- 数据集的名称:cner
- 数据集的地址:data/cner/
- 总共的字的类别数目:num_tags
- 是否使用gpu:如果是指定gpu_ids="0"(默认使用第0块),否则指定gpu_ids="-1"
- 文本的最大长度:max_seq_len,需要和我们在preprocess.py里面指定的保持一致
- 使用use_bilstm和use_crf分别指定是否使用bilstm和crf模块
结果
2021-08-05 16:19:12,787 - INFO - main.py - train - 52 - 【train】 epoch:2 359/360 loss:0.0398
2021-08-05 16:19:14,717 - INFO - main.py - train - 56 - [eval] loss:1.8444 precision=0.9484 recall=0.8732 f1_score=0.9093
2021-08-05 16:32:20,751 - INFO - main.py - test - 130 -
precision recall f1-score support
PRO 0.86 0.63 0.73 19
ORG 0.94 0.91 0.92 543
CONT 1.00 1.00 1.00 33
RACE 1.00 0.93 0.97 15
NAME 0.99 0.93 0.96 110
EDU 0.98 0.94 0.96 109
LOC 0.00 0.00 0.00 2
TITLE 0.95 0.84 0.89 770
micro-f1 0.95 0.88 0.91 1601
2021-08-05 16:32:20,752 - INFO - main.py - <module> - 218 - 虞兔良先生:1963年12月出生,汉族,中国国籍,无境外永久居留权,浙江绍兴人,中共党员,MBA,经济师。
2021-08-05 16:32:22,892 - INFO - trainUtils.py - load_model_and_parallel - 96 - Load ckpt from ./checkpoints/bert/model.pt
2021-08-05 16:32:23,205 - INFO - trainUtils.py - load_model_and_parallel - 106 - Use single gpu in: ['0']
2021-08-05 16:32:23,239 - INFO - main.py - predict - 156 - {'NAME': [('虞兔良', 0)], 'RACE': [('汉族', 17)], 'CONT': [('中国国籍', 20)], 'TITLE': [('中共党员', 40), ('经济师', 49)], 'EDU': [('MBA', 45)]}
| models | loss | precision | recall | f1_score |
|---|---|---|---|---|
| bert | 1.8444 | 0.9484 | 0.8732 | 0.9093 |
| bert_bilstm | 2.0856 | 0.9540 | 0.8670 | 0.9084 |
| bert_crf | 26.9665 | 0.9385 | 0.8957 | 0.9166 |
| bert_bilstm_crf | 30.8463 | 0.9382 | 0.8919 | 0.9145 |
补充
此外,还提供了其它数据集的一些使用实例
商品属性识别
python main.py \
--bert_dir="../model_hub/chinese-bert-wwm-ext/" \
--data_dir="./data/attr/" \
--data_name='attr' \
--log_dir="./logs/" \
--output_dir="./checkpoints/" \
--num_tags=209 \
--seed=123 \
--gpu_ids="0" \
--max_seq_len=64 \
--lr=3e-5 \
--crf_lr=3e-2 \
--other_lr=3e-4 \
--train_batch_size=64 \
--train_epochs=3 \
--eval_batch_size=64 \
--lstm_hidden=128 \
--num_layers=1 \
--use_lstm='False' \
--use_crf='True' \
--dropout_prob=0.1 \
--dropout=0.1 \
precision:0.7420 recall:0.7677 micro_f1:0.7546
precision recall f1-score support
17 0.00 0.00 0.00 4
24 0.00 0.00 0.00 2
35 0.00 0.00 0.00 0
19 0.00 0.00 0.00 19
47 0.57 0.01 0.03 282
30 0.26 0.09 0.13 111
12 0.75 0.82 0.78 2460
44 0.00 0.00 0.00 8
49 0.32 0.33 0.33 266
31 0.44 0.23 0.30 169
1 0.82 0.89 0.85 5048
20 0.52 0.11 0.18 120
26 0.00 0.00 0.00 0
39 0.39 0.30 0.34 1059
36 0.42 0.53 0.47 736
5 0.75 0.74 0.74 7982
11 0.72 0.81 0.76 12250
6 0.58 0.79 0.67 303
18 0.73 0.77 0.75 11123
37 0.74 0.73 0.73 3080
42 0.00 0.00 0.00 4
46 0.00 0.00 0.00 7
33 0.00 0.00 0.00 4
23 0.00 0.00 0.00 4
15 0.62 0.58 0.60 146
28 0.00 0.00 0.00 8
9 0.50 0.61 0.55 2532
51 0.00 0.00 0.00 7
34 0.20 0.06 0.09 54
4 0.81 0.85 0.83 33645
14 0.87 0.89 0.88 4553
13 0.70 0.72 0.71 12992
32 0.00 0.00 0.00 8
38 0.60 0.68 0.64 6788
40 0.75 0.61 0.67 6588
53 0.00 0.00 0.00 0
43 0.00 0.00 0.00 13
22 0.38 0.32 0.35 1770
48 0.00 0.00 0.00 42
2 0.26 0.15 0.19 598
41 0.52 0.11 0.18 108
29 0.75 0.77 0.76 841
52 0.00 0.00 0.00 27
54 0.69 0.65 0.67 1221
3 0.52 0.61 0.56 1840
7 0.83 0.92 0.87 4921
10 0.49 0.46 0.48 1650
21 0.24 0.26 0.25 120
25 0.00 0.00 0.00 3
16 0.90 0.92 0.91 4604
50 0.56 0.38 0.46 91
8 0.86 0.90 0.88 3515
micro-f1 0.74 0.77 0.75 133726
荣耀V9Play支架手机壳honorv9paly手机套新品情女款硅胶防摔壳
Load ckpt from ./checkpoints/bert_crf_attr/model.pt
Use single gpu in: ['0']
{'38': [('荣耀V9Play', 0), ('honorv9paly', 13)], '22': [('支架', 8)], '4': [('手机壳', 10), ('手机套', 24), ('防摔壳', 34)], '14': [('新品', 27)], '8': [('情女款', 29)], '12': [('硅胶', 32)]}
地址要素识别
python main.py \
--bert_dir="../model_hub/chinese-bert-wwm-ext/" \
--data_dir="./data/addr/" \
--data_name='addr' \
--log_dir="./logs/" \
--output_dir="./checkpoints/" \
--num_tags=69 \
--seed=123 \
--gpu_ids="0" \
--max_seq_len=64 \
--lr=3e-5 \
--crf_lr=3e-2 \
--other_lr=3e-4 \
--train_batch_size=64 \
--train_epochs=3 \
--eval_batch_size=64 \
--lstm_hidden=128 \
--num_layers=1 \
--use_lstm='False' \
--use_crf='True' \
--dropout_prob=0.1 \
--dropout=0.1 \
precision:0.9233 recall:0.9021 micro_f1:0.9125
precision recall f1-score support
district 0.96 0.93 0.94 1444
village_group 0.91 0.87 0.89 47
roadno 0.98 0.98 0.98 815
poi 0.77 0.85 0.81 1279
subpoi 0.82 0.65 0.73 459
community 0.81 0.70 0.75 373
distance 1.00 1.00 1.00 6
city 0.99 0.94 0.96 1244
road 0.94 0.95 0.95 1244
prov 0.99 0.97 0.98 994
floorno 0.97 0.94 0.95 211
assist 0.82 0.88 0.85 64
cellno 0.99 0.98 0.98 123
town 0.95 0.87 0.91 924
devzone 0.82 0.82 0.82 222
houseno 0.97 0.96 0.97 496
intersection 0.93 0.65 0.76 20
micro-f1 0.92 0.90 0.91 9965
浙江省嘉兴市平湖市钟埭街道新兴六路法帝亚洁具厂区内万杰洁具
Load ckpt from ./checkpoints/bert_crf_addr/model.pt
Use single gpu in: ['0']
{'prov': [('浙江省', 0)], 'city': [('嘉兴市', 3)], 'district': [('平湖市', 6)], 'town': [('钟埭街道', 9)], 'road': [('新兴六路', 13)], 'poi': [('法帝亚洁具厂区', 17), ('万杰洁具', 25)]}
CLUE数据集
python main.py \
--bert_dir="../model_hub/chinese-bert-wwm-ext/" \
--data_dir="./data/CLUE/" \
--data_name='clue' \
--log_dir="./logs/" \
--output_dir="./checkpoints/" \
--num_tags=41 \
--seed=123 \
--gpu_ids="0" \
--max_seq_len=150 \
--lr=3e-5 \
--crf_lr=3e-2 \
--other_lr=3e-4 \
--train_batch_size=32 \
--train_epochs=3 \
--eval_batch_size=32 \
--max_grad_norm=1 \
--warmup_proportion=0.1 \
--adam_epsilon=1e-8 \
--weight_decay=0.01 \
--lstm_hidden=128 \
--num_layers=1 \
--use_lstm='False' \
--use_crf='True' \
--dropout_prob=0.3 \
--dropout=0.3 \
precision:0.7802 recall:0.8176 micro_f1:0.7984
precision recall f1-score support
position 0.77 0.82 0.80 425
movie 0.88 0.77 0.82 150
name 0.84 0.90 0.87 451
book 0.86 0.81 0.83 152
address 0.65 0.68 0.66 364
organization 0.81 0.81 0.81 344
scene 0.73 0.76 0.74 199
government 0.77 0.87 0.82 244
game 0.76 0.90 0.82 287
company 0.80 0.81 0.81 366
micro-f1 0.78 0.82 0.80 2982
彭小军认为,国内银行现在走的是台湾的发卡模式,先通过跑马圈地再在圈的地里面选择客户,
Load ckpt from ./checkpoints/bert_crf/model.pt
Use single gpu in: ['0']
{'name': [('彭小军', 0)], 'address': [('台湾', 15)]}
医疗数据集实例
python main.py \
--bert_dir="../model_hub/chinese-bert-wwm-ext/" \
--data_dir="./data/CHIP2020/" \
--data_name='chip' \
--log_dir="./logs/" \
--output_dir="./checkpoints/" \
--num_tags=37 \
--seed=123 \
--gpu_ids="0" \
--max_seq_len=150 \
--lr=3e-5 \
--crf_lr=3e-2 \
--other_lr=3e-4 \
--train_batch_size=32 \
--train_epochs=3 \
--eval_batch_size=32 \
--max_grad_norm=1 \
--warmup_proportion=0.1 \
--adam_epsilon=1e-8 \
--weight_decay=0.01 \
--lstm_hidden=128 \
--num_layers=1 \
--use_lstm='False' \
--use_crf='True' \
--dropout_prob=0.3 \
--dropout=0.3 \
Load ckpt from ./checkpoints/bert_crf/model.pt
Use single gpu in: ['0']
precision:0.6477 recall:0.6530 micro_f1:0.6503
precision recall f1-score support
equ 0.57 0.57 0.57 238
sym 0.59 0.45 0.51 4130
pro 0.60 0.68 0.64 2057
bod 0.63 0.66 0.64 5883
dis 0.71 0.78 0.74 4935
dru 0.77 0.86 0.81 1440
mic 0.73 0.82 0.77 584
dep 0.59 0.53 0.56 110
ite 0.47 0.40 0.43 923
micro-f1 0.65 0.65 0.65 20300
大动脉转换手术要求左心室流出道大小及肺动脉瓣的功能正常,但动力性左心室流出道梗阻并非大动脉转换术的禁忌证。
Load ckpt from ./checkpoints/bert_crf/model.pt
Use single gpu in: ['0']
{'pro': [('大动脉转换手术', 0), ('大动脉转换术', 42)], 'bod': [('左心室流出道', 9), ('肺动脉瓣', 18)], 'dis': [('动力性左心室流出道梗阻', 29)]}
怎么训练自己数据
- 1、在data下新建数据集文件夹,在该文件夹下新建mid_data、raw_data。raw_data下放置数据集文件。
- 2、在raw_data下新建process.py,主要处理数据为mid_data下的文件,具体可参考上述实例数据集。
- 3、在preprocess.py定义数据集名和文本最大长度,运行后得到final_data下的文件。
- 4、根据不同的指令运行main.py得到结果。

基于bert_bilstm_crf的命名实体的更多相关文章
- 基于bert的命名实体识别,pytorch实现,支持中文/英文【源学计划】
声明:为了帮助初学者快速入门和上手,开始源学计划,即通过源代码进行学习.该计划收取少量费用,提供有质量保证的源码,以及详细的使用说明. 第一个项目是基于bert的命名实体识别(name entity ...
- 【转】基于VSM的命名实体识别、歧义消解和指代消解
原文地址:http://blog.csdn.net/eastmount/article/details/48566671 版权声明:本文为博主原创文章,转载请注明CSDN博客源地址!共同学习,一起进步 ...
- 学习笔记CB007:分词、命名实体识别、词性标注、句法分析树
中文分词把文本切分成词语,还可以反过来,把该拼一起的词再拼到一起,找到命名实体. 概率图模型条件随机场适用观测值条件下决定随机变量有有限个取值情况.给定观察序列X,某个特定标记序列Y概率,指数函数 e ...
- 抛弃模板,一种Prompt Learning用于命名实体识别任务的新范式
原创作者 | 王翔 论文名称: Template-free Prompt Tuning for Few-shot NER 文献链接: https://arxiv.org/abs/2109.13532 ...
- 基于keras的BiLstm与CRF实现命名实体标注
众所周知,通过Bilstm已经可以实现分词或命名实体标注了,同样地单独的CRF也可以很好的实现.既然LSTM都已经可以预测了,为啥要搞一个LSTM+CRF的hybrid model? 因为单独LSTM ...
- 基于CRF工具的机器学习方法命名实体识别的过
[转自百度文库] 基于CRF工具的机器学习方法命名实体识别的过程 | 浏览:226 | 更新:2014-04-11 09:32 这里只讲基本过程,不涉及具体实现,我也是初学者,想给其他初学者一些帮助, ...
- DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
三个月之前 NLP 课程结课,我们做的是命名实体识别的实验.在MSRA的简体中文NER语料(我是从这里下载的,非官方出品,可能不是SIGHAN 2006 Bakeoff-3评测所使用的原版语料)上训练 ...
- 基于BERT预训练的中文命名实体识别TensorFlow实现
BERT-BiLSMT-CRF-NERTensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuni ...
- 基于条件随机场(CRF)的命名实体识别
很久前做过一个命名实体识别的模块,现在有时间,记录一下. 一.要识别的对象 人名.地名.机构名 二.主要方法 1.使用CRF模型进行识别(识别对象都是最基础的序列,所以使用了好评率较高的序列识别算法C ...
随机推荐
- React简单教程-4.1-hook
前言 虽然我们简单感受了一下 useState 的用法,但我想你还是对 React 里的 hook 迷迷糊糊的.本文我们将明确下 React 的概念. HOOK 前生今世 在我示例中,写的 React ...
- Prometheus 四种metric类型
Prometheus的4种metrics(指标)类型: Counter Gauge Histogram Summary 四种指标类型的数据对象都是数字,如果要监控文本类的信息只能通过指标名称或者 la ...
- 【Redis】集群请求命令处理
集群请求命令处理 在Redis的命令处理函数processCommand(server.c)中有对集群节点的处理,满足以下条件时进入集群节点处理逻辑中: 启用了集群模式,通过server.cluste ...
- 【Pr】基础流程
新建工程 1.打开Pr 2.点击"新建""项目" 3.在电脑磁盘上新建好项目想要存放的位置,比如Demo1,为了便于管理,我先新建了一个Demo文件夹,再在里边 ...
- 《The Tail At Scale》论文详解
简介 用户体验与软件的流畅程度是呈正相关的,所以对于软件服务提供方来说,保持服务耗时在用户能接受的范围内就是一件必要的事情.但是在大型分布式系统上保持一个稳定的耗时又是一个很大的挑战,这篇文章解析的是 ...
- 在.NET 6.0上使用Kestrel配置和自定义HTTPS
大家好,我是张飞洪,感谢您的阅读,我会不定期和你分享学习心得,希望我的文章能成为你成长路上的垫脚石,让我们一起精进. 本章是<定制ASP NET 6.0框架系列文章>的第四篇.在本章,我们 ...
- dubbox 入门demo
1.Dubbox简介 Dubbox 是一个分布式服务架构,其前身是阿里巴巴开源项目 Dubbo,被国内电商及互联网项目使用,后期阿里巴巴停止了该项目的维护,当当网便在 Dubbo 基础上进行优化,并继 ...
- centos7 nginx 域名能ping通,但无法打开网页
方法一:关闭防火墙 sudo systemctl stop firewalld.service 方法二:容许80端口访问 vim打开iptables, 命令如下: #vim /etc/sysconfi ...
- 004 SpringSecurity验证规则
SpringSecurity验证规则 SpringSecurity框架登录后,==在userDetails对象中,一定会有一个权限列表 == 登录用户对象的值可能是: {"authoriti ...
- 000Java_Java_历史
1. Java历史 程序:有序指令的集合 1995年--Java.1版本 Java之父--Gosling Java特点 面向对象 健壮 (强类型机制异常处理垃圾的自动回收) 跨平台性[一个编译好的.c ...