centos-7部署kafka-v2.13.3.0.1集群
1、部署测试机器规划
| ip | kafka 版本 | zookeeper 版本 |
| 192.168.113.132 | v2.13.3.0.1 | v3.6.3 |
| 192.168.113.135 | v2.13.3.0.1 | v3.6.3 |
| 192.168.113.136 | v2.13.3.0.1 | v3.6.3 |
kafka下载官网:https://kafka.apache.org/downloads.html
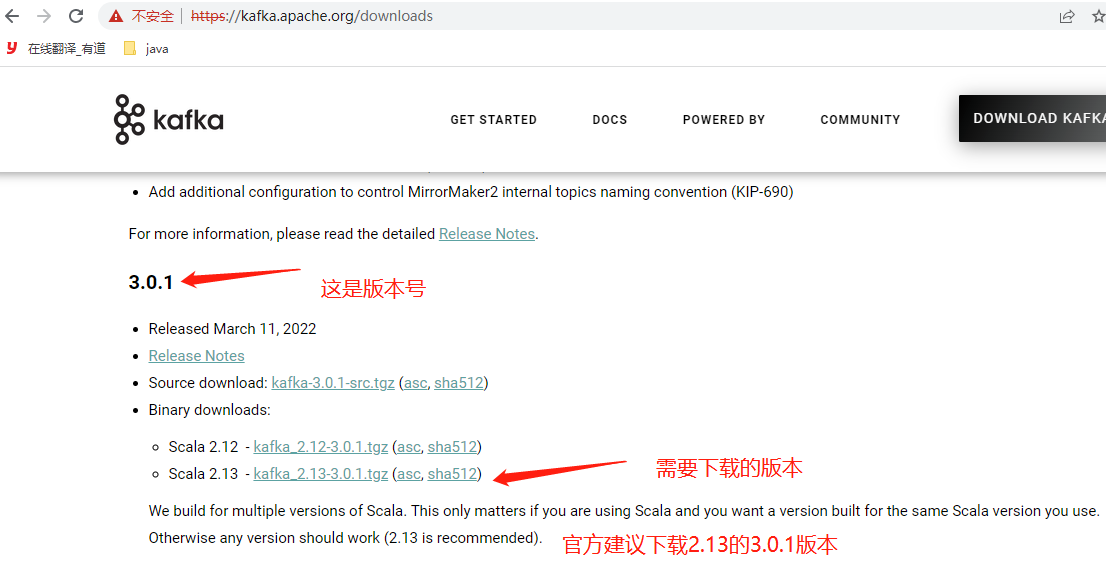
[root@localhost ~]# cd /opt/ #计划安装kafka的位置
[root@localhost opt]# wget https://archive.apache.org/dist/kafka/3.0.1/kafka_2.13-3.0.1.tgz #下载包
[root@localhost opt]# tar xf kafka_2.13-3.0.1.tgz #解压
[root@localhost opt]# mv kafka_2.13-3.0.1/ kafka #重命名
[root@localhost opt]# ls kafka/libs/ #查看kfaka的包名查看zk的版本,如果不使用kafka包里面自带的zk服务,自己搭建的话,最好下载对应版本的zk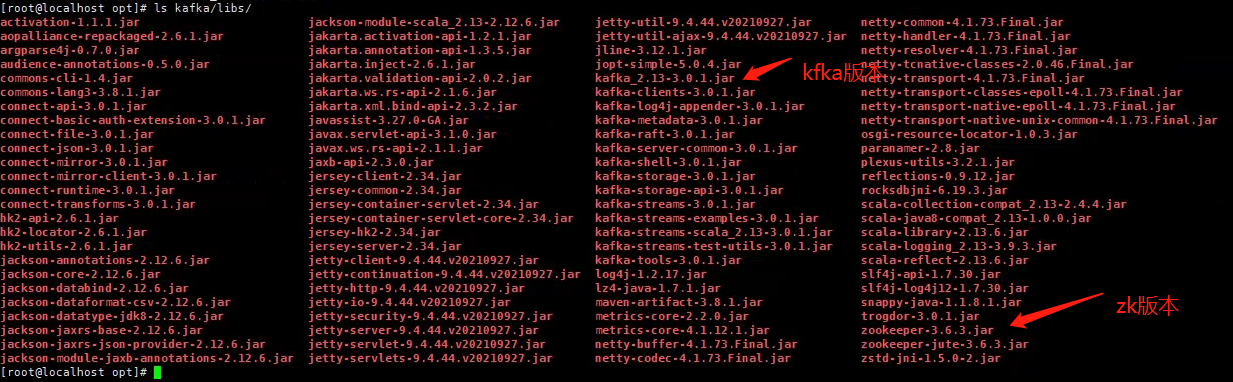
zookeeper下载官网:http://zookeeper.apache.org/
下载二进制包

每台节点执行操作
[root@localhost ~]# cd /opt/
[root@localhost opt]# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz --no-check-certificate
[root@localhost opt]# tar xf apache-zookeeper-3.6.3-bin.tar.gz
[root@localhost opt]# mv apache-zookeeper-3.6.3-bin zookeeper2、使用二进制安装zookeeper集群
应用场景:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等
kafka需要使用zookeeper来进行调度所以首先安装,也可以不单独安装直接使用kafka包里面的zookeeper进行配置启动,但是建议单独安装
2.1、前面已经将包下载好并解压重命名了,接下来进行配置zookeeper
没安装jdk的先安装jdk,我这里是yum安装的也可以下载二进制包进行
[root@localhost conf]# yum -y install java-1.8.0-openjdk*对每台节点进行操作
[root@localhost opt]# cd zookeeper/conf/ #切换目录
[root@localhost conf]# ls #查看配置文件
configuration.xsl log4j.properties zoo_sample.cfg
[root@localhost conf]# cp zoo_sample.cfg zoo.cfg #拷贝配置文件并重命名
[root@localhost conf]# vim zoo.cfg #编辑配置文件进行修改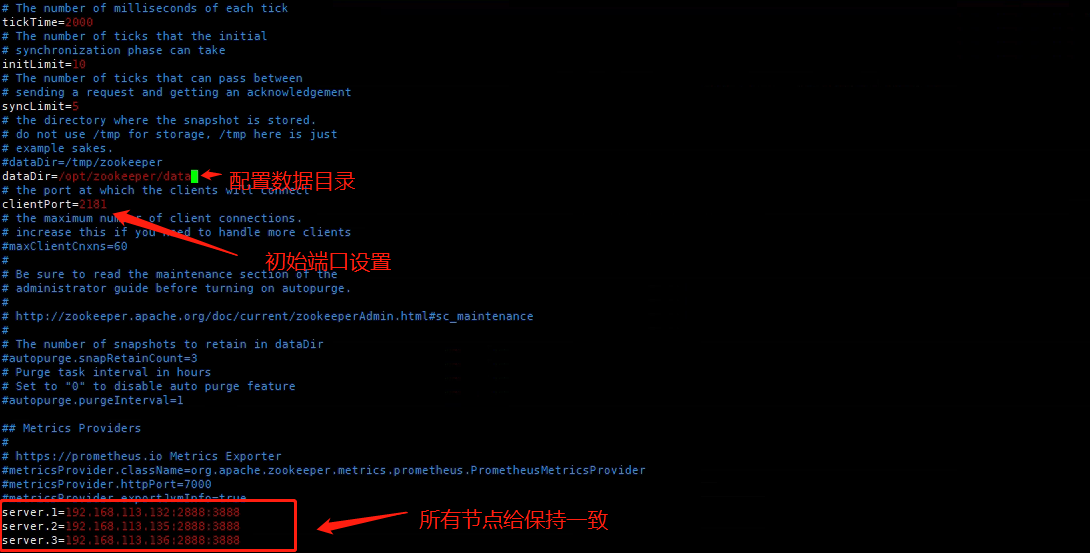
注意!zk-3.6过后的版本在开启服务器后会默认占用8080端口
可以修改配置来修改端口
# admin.serverPort 默认占8080端口
admin.serverPort=88882.2、添加myid文件这个配置是区分节点的
[root@localhost conf]# mkdir /opt/zookeeper/data
[root@localhost conf]# vim /opt/zookeeper/data/myid
[root@localhost conf]# echo 1 > /opt/zookeeper/data/myid #分别给三个server节点定向一个编号到myid文件里面(1 2 3)来进行节点区分
切换到启动目录
[root@localhost zookeeper]# cd /opt/zookeeper/bin/
启动zk
[root@localhost bin]# /opt/zookeeper/bin/zkServer.sh start #源码包安装的方式需要指定配置文件查看启动状态

提示下面错误表示没有关闭selinux或者防火墙(或者直接配置iptables规则)
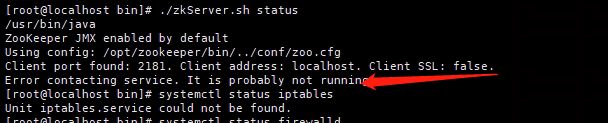
关闭防火墙跟selinux后状态正常(这是被分配到的从节点)

再看看分配到的主节点(leader)

zkCli.sh客户端使用
[root@localhost bin]# ./zkCli.sh -server 192.168.113.135:2181 #连接本机
[root@localhost bin]# ./zkCli.sh -server 192.168.113.135 #不适用端口连接本机,默认去连接2181端口
[root@localhost bin]# ./zkCli.sh -server 192.168.113.132:2181 #连接到其他机器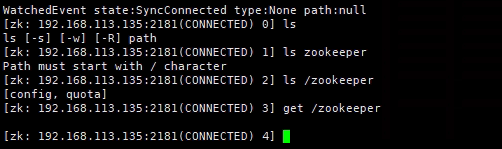
2.3、为了安全起见可以给zk集群添加ip白名单,本来zk只是kafka使用只需要集群ip能访问就可以了
登陆zookeeper
进入zookeeper安装目录下的bin目录下执行
./zkCli.sh -server ip:port
./zkCli.sh -server 192.168.113.135:2181 #例!在bin目录下面执行,进入集群的任意一台zk查看当前权限,未配置会提示允许所有
getAcl /添加可访问IP
setAcl / ip:192.168.113.132:cdrwa,ip:192.168.113.135:cdrwa,ip:192.168.113.136:cdrwa,ip:127.0.0.1:cdrwa注:1.在设置IP白名单时,将本机ip 127.0.0.1也加上,让本机也可以访问及修改
在第一次添加完ip白名单后,又想继续添加白名单,则在设置的时候,以前的ip也都是写在命令里,不然以前添加的都会被覆盖掉,那就坑了
查看是否正常添加
getAcl /如果要恢复所有ip皆可访问,则执行
setAcl / world:anyone:cdrwa3、配置kafka
[root@localhost opt]# cd /opt/kafka/config/
[root@localhost config]# vim /opt/kafka/config/server.properties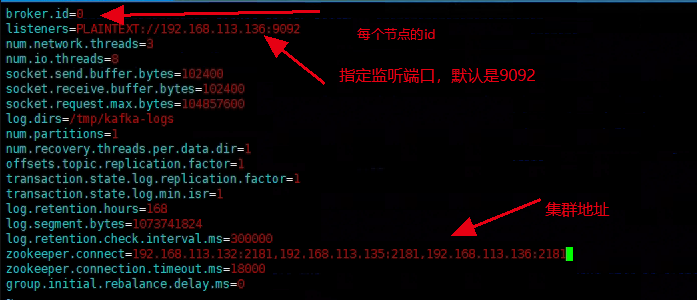
注意!:log.dirs在生产中不要配置到tmp目录下面不然系统定时清理掉这个下面的文件会导致系统崩溃。
启动kafka
[root@localhost ~]# nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties 1> /dev/null 2>&1 &测试创建topic
[root@localhost bin]# ./kafka-topics.sh --create --topic quickstart-events --bootstrap-server 192.168.113.132:9092查看topic
[root@localhost bin]# ./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server 192.168.113.132:9092
生产者:发送消息
[root@localhost bin]# ./kafka-console-producer.sh --topic quickstart-events --bootstrap-server 192.168.113.132:9092消费者:处理消息
[root@localhost bin]# ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server 192.168.113.132:9092命令使用拓展
指定创建多个副本及分区
./kafka-topics.sh --create --replication-factor 2 --partitions 4 --topic quickstart-events --bootstrap-server 192.168.113.132:9092
# --replication-factor 参数是指定副本数
# --partitions 指定分区动态调整分区只能网上调不能向下
./kafka-topics.sh --alter --bootstrap-server 192.168.113.132:9092 --topic quickstart-events --partitions 12删除topic
./kafka-topics.sh --delete --bootstrap-server 192.168.113.132:9092 --topic quickstart-events kafka查看所有组
./kafka-consumer-groups.sh --bootstrap-server 192.168.113.132:9092 --list查看topIc消费组consumer的积压情况
./kafka-consumer-groups.sh --bootstrap-server 192.168.113.132:9092 --describe --group +需要查询的groupcentos-7部署kafka-v2.13.3.0.1集群的更多相关文章
- K8S学习笔记之二进制部署Kubernetes v1.13.4 高可用集群
0x00 概述 本次采用二进制文件方式部署,本文过程写成了更详细更多可选方案的ansible部署方案 https://github.com/zhangguanzhang/Kubernetes-ansi ...
- 2、kubeadm快速部署kubernetes(v1.15.0)集群190623
一.网络规划 节点网络:192.168.100.0/24 Service网络:10.96.0.0/12 Pod网络(默认):10.244.0.0/16 二.组件分布及节点规划 master(192.1 ...
- CentOS 7部署Kafka和Kafka集群
CentOS 7部署Kafka和Kafka集群 注意事项 需要启动多个shell脚本交互客户端进行验证,运行中的客户端不要停止. 准备工作: 安装java并设置java环境变量,在`/etc/prof ...
- [转帖]Breeze部署kubernetes1.13.2高可用集群
Breeze部署kubernetes1.13.2高可用集群 2019年07月23日 10:51:41 willblog 阅读数 673 标签: kubernetes 更多 个人分类: kubernet ...
- kafka2.3.1+zookeeper3.5.6+kafka-manager2.0.0.2集群部署(centos7.7)
一.准备三台服务器,配置好主机名和ip地址 二.服务器初始化:包括安装常用命令工具,修改系统时区,校对系统时间,关闭selinux,关闭firewalld,修改主机名,修改系统文件描述符,优化内核参数 ...
- Storm1.0.3集群部署
Storm集群部署 所有集群部署的基本流程都差不多:下载安装包并上传.解压安装包并配置环境变量.修改配置文件.分发安装包.启动集群.查看集群是否部署成功. 1.所有的集群上都要配置hosts vi ...
- hbase-2.0.4集群部署
hbase-2.0.4集群部署 1. 集群节点规划: rzx1 HMaster,HRegionServer rzx2 HRegionServer rzx3 HRegionServer 前提:搭建好ha ...
- lvs+keepalived部署k8s v1.16.4高可用集群
一.部署环境 1.1 主机列表 主机名 Centos版本 ip docker version flannel version Keepalived version 主机配置 备注 lvs-keepal ...
- Centos7.6部署k8s v1.16.4高可用集群(主备模式)
一.部署环境 主机列表: 主机名 Centos版本 ip docker version flannel version Keepalived version 主机配置 备注 master01 7.6. ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载-2)
原文:http://www.cnblogs.com/PurpleDream/p/4510279.html 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群 前言: ...
随机推荐
- 085_JS Promise
js对undefined的处理 https://www.liaoxuefeng.com/wiki/001434446689867b27157e896e74d51a89c25cc8b43bdb3000 ...
- 计算机视觉——SSD和YOLO简介
前言 本文记录用,防止遗忘 计算机视觉--SSD和YOLO简介 课件(单发多框检测SSD) 生成锚框 对每个像素,生成多个以它为中心的锚框 给定n个大小 s1, ...,s2,和m个高宽比,那么生成 ...
- 深入理解JVM 学习笔记2
Java内存区域 在执行java程序的过程中JVM会把它管理的内存划分为多个不同的数据区域. 根据<Java 虚拟机规范 SE7版>的规定,Java 虚拟机所管理的内存将会包括以下几个运行 ...
- 一、100ASK_IMX6ULL嵌入式裸板学习_LED实验(中)
以C语言方式驱动(例程与代码分析) 韦东山的例程: start.s部分: .text .global _start @全局标号 _start: //设置栈 ldr sp,=0x80200000 @设置 ...
- 理解redux中间件
redux questions : 1. reducers 函数如何创建和聚合 2. action创建函数如何如何包裹在dispatch函数中 3. 如何给默认的dispatch方法增加中间件能力 m ...
- 刘蓉年谱.PDF
书本详情 刘蓉年谱.PDF 所有责任者: 陆宝千著 所有题名: 并列正题名:A chronological biography of Liu JungChronological biography o ...
- 广告网络归因技术之SKAdNetwork
IDFA的背景 为了保护用户隐私,早在2012年就不再允许其生态中的玩家获取用户的唯一标识符,但是商家在移动端打广告的时候又希望能监控到每一次广告投放的效果,因此,苹果想出了折中的办法,就是提供另外一 ...
- python 操作 ES 二、mappings
环境 python:3.8 es:7.8.0 环境安装 pip install elasticsearch==7.8.0 from elasticsearch import Elasticsearch ...
- uml类间关系总结
1. 关联关系 (1) 双向关联 顾客购买并拥有商品,商品被顾客购买,Customer和Product双向关联 (2) 单向关联 顾客拥有地址 (3) 自关联:一些类的属性对象类型是本身 (4) 多重 ...
- 深度剖析CPython解释器》Python内存管理深度剖析Python内存管理架构、内存池的实现原理
目录 1.楔子 第1层:基于第0层的"通用目的内存分配器"包装而成. 第2层:在第1层提供的通用 *PyMem_* 接口基础上,实现统一的对象内存分配(object.tp_allo ...