论文笔记 - RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning
Motivation
虽然半监督学习减少了大量数据标注的成本,但是对计算资源的要求依然很高(无论是在训练中还是超参搜索过程中),因此提出想法:由于计算量主要集中在大量未标注的数据上,能否从未标注的数据中检索出重要的数据(Coreset)呢?
Analysis
当前用来半监督学习的方案:
- 自洽正则化(Consistency Regularization):自洽正则化的思路是,对未标记数据进行数据增广(加入噪声等),产生的新数据输入分类器,预测结果应保持自洽。即同一个数据增广产生的样本,模型预测结果应保持一致。
- 最小化熵(Entropy Minimization):许多半监督学习方法都基于一个共识,即分类器的分类边界不应该穿过边际分布的高密度区域。具体做法就是强迫分类器对未标记数据作出低熵预测。
半监督学习能够成功实施的必要条件:有标签的数据和无标签的数据来自相同的分布。否则会导致模型性能的大幅度下降。因此 DS3L 将其转化为了一个双层的优化问题:
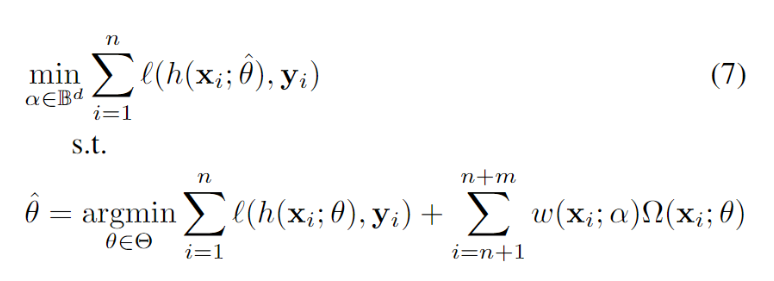
下面的式子和普通的半监督学习一直,不过在无标签正则化项(自洽正则化或最小化熵)前加上了权重参数,权重参数由什么决定:越不影响模型在有标签数据上的表现的数据权重越大;
换句话说:你用一个无标签的数据 A 更新了参数,结果发现更新玩参数的模型在有标签的数据集上表现变差了,那么 A 就是 OOD 或者有巨大噪声的数据,他的权重越小越好,权重为 0 表示不要 A 这个数据了。
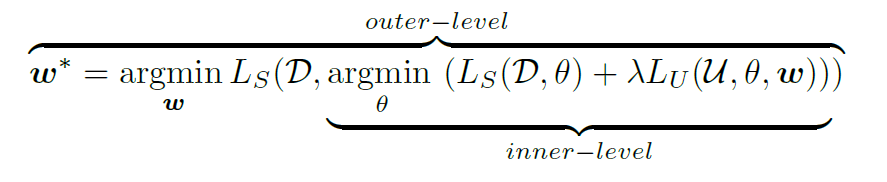
上图:双层优化。
我们选取 Coreset 的出发点也是一样:选择一个无标签数据的子集 $S_t$,使得在这个子集上半监督训练出的参数,在有标签数据上的误差最小,同样是个双层优化。
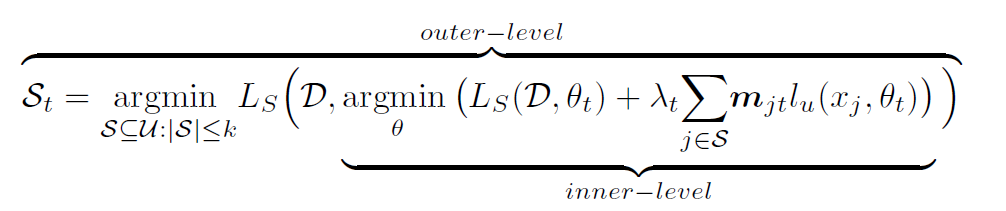
但是这个式子明显是不可解的,首先我们需要遍历出所有的 $S_t$ 组合,对每一种组合应用半监督训练使其收敛,用收敛后的模型权重应用到有标签数据计算准确率,再用这个准确率评估我们选的子集怎么样,复杂度不可想象。
因此用近似的方法进行转化,转化为一层的优化问题:
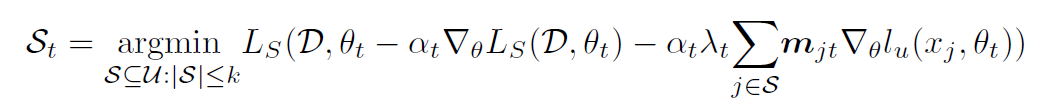
上图的核心思想是适应性的数据挑选,也就是说不是选一种 Coreset 就一次训练到收敛,而是根据训练进度逐渐调整 Coreset,直到得到最好的 Coreset:首先仍然遍历出所有的 $S_t$ 组合,对每一种组合计算半监督训练的损失函数,用这个损失函数优化一遍参数,只进行一次迭代,然后用更新后的模型对有标签的数据求准确度,再用这个准确率评估我们选的子集怎么样,因为这只是一步迭代,因此子集会不断更新。
相当理想了,但是计算复杂度依然是不可接受的,原因就在于最开始的遍历出所有的 $S_t$ 组合,因此作者又提出:当式子中的 $L_s$ 项(即有标签数据的损失项)是交叉熵形式的时候,整个式子就拥有了次模性,因此可以用贪心算法快速解决,同时保证收敛性和收敛速度,也就是原本开始时我们需要遍历所有的可能的 $S_t$ 组合,现在只需要遍历所有的可能加入 $S_t$ 的单个数据就可以了。加上符号,变成具有单调(增)性的次模函数:
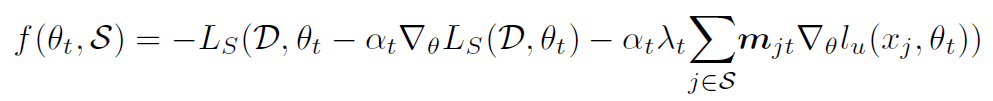
次模性的定义:

因此每次我们只需要挑选让这个次模函数增长最大的单个(无标签)数据,把他加到 Coreset 里面就行了。
作者说现在很好,但是我懒得一个一个计算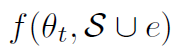 (也就是加上把单个无标签数据 e 加到 Coreset 里面后一次优化后,模型在有标签数据上的损失的负值)怎么办,别慌,可以用泰勒展开近似估计:
(也就是加上把单个无标签数据 e 加到 Coreset 里面后一次优化后,模型在有标签数据上的损失的负值)怎么办,别慌,可以用泰勒展开近似估计:
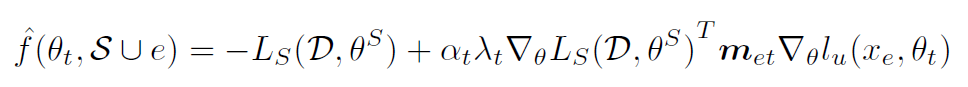
Algorithm

论文笔记 - RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning的更多相关文章
- 论文笔记之:Heterogeneous Image Features Integration via Multi-Modal Semi-Supervised Learning Model
Heterogeneous Image Features Integration via Multi-Modal Semi-Supervised Learning Model ICCV 2013 本文 ...
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
这篇论文主要介绍了如何使用图片级标注对像素级分割任务进行训练.想法很简单却达到了比较好的效果.文中所提到的loss比较有启发性. 大体思路: 首先同FCN一样,这个网络只有8层(5层VGG,3层全卷积 ...
- 【转载】论文笔记系列-Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
一. 引出主题¶ 深度学习领域一直存在一个比较严重的问题——“灾难性遗忘”,即一旦使用新的数据集去训练已有的模型,该模型将会失去对原数据集识别的能力.为解决这一问题,本文提出了树卷积神经网络,通过先将 ...
- 论文笔记之:Heterogeneous Face Attribute Estimation: A Deep Multi-Task Learning Approach
Heterogeneous Face Attribute Estimation: A Deep Multi-Task Learning Approach 2017.11.28 Introductio ...
- 论文笔记:(TOG2019)DGCNN : Dynamic Graph CNN for Learning on Point Clouds
目录 摘要 一.引言 二.相关工作 三.我们的方法 3.1 边缘卷积Edge Convolution 3.2动态图更新 3.3 性质 3.4 与现有方法比较 四.评估 4.1 分类 4.2 模型复杂度 ...
- 论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks 2018年07月11日 14 ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (下)
[论文笔记系列]AutoML:A Survey of State-of-the-art (上) 上一篇文章介绍了Data preparation,Feature Engineering,Model S ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
随机推荐
- APICloud AVM框架 封装车牌号输入键盘组件
AVM(Application-View-Model)前端组件化开发模式基于标准Web Components组件化思想,提供包含虚拟DOM和Runtime的编程框架avm.js以及多端统一编译工具,完 ...
- Java 在Word文档中添加艺术字
艺术字是以普通文字为基础,经过专业的字体设计师艺术加工的变形字体.字体特点符合文字含义.具有美观有趣.易认易识.醒目张扬等特性,是一种有图案意味或装饰意味的字体变形,常用来创建旗帜鲜明的标志或标题. ...
- win10电脑自动连接蓝牙设备攻略
每次在电脑上想连接蓝牙耳机,但不想手动去连接怎么办呢? 自动连接! 其实微软已经解决了这个问题,只要打开蓝牙,他就会自动匹配上次连接的设备 打开设置--->设备勾选 "显示使用&quo ...
- 来点基础的练习题吧,看见CSDN这类基础的代码不多
来点基础的练习题吧,看见CSDN这类基础的代码不多 //正三角形 void ex03(){ int i,k=0, rows, space; printf("请输入三角形的层次:") ...
- SSTI服务端模板注入漏洞原理详解及利用姿势集锦
目录 基本概念 模板引擎 SSTI Jinja2 Python基础 漏洞原理 代码复现 Payload解析 常规绕过姿势 其他Payload 过滤关键字 过滤中括号 过滤下划线 过滤点.(适用于Fla ...
- 论文解读(RvNN)《Rumor Detection on Twitter with Tree-structured Recursive Neural Networks》
论文信息 论文标题:Rumor Detection on Twitter with Tree-structured Recursive Neural Networks论文作者:Jing Ma, Wei ...
- Java SE 3、封装
封装 封装的好处 隐藏实现细节 可以对数据进行验证,保证安全合理 实现步骤 将属性进行私有化private 提供一个公共的(public)set方法,用于对属性判断并赋值 public void se ...
- 添加 K8S CPU limit 会降低服务性能
文章转载自:https://mp.weixin.qq.com/s/cR6MpQu-n1cwMbXmVaXqzQ
- 第一章:模型层 - 5:模型的元数据Meta
模型的元数据,指的是"除了字段外的所有内容",例如排序方式.数据库表名.人类可读的单数或者复数名等等.所有的这些都是非必须的,甚至元数据本身对模型也是非必须的.但是,我要说但是,有 ...
- Docker MySql 查看版本的三种方法
目录 Docker MySql 查看版本的三种方法 1.mysql -V命令查看版本 2.status命令查看版本 3.version命令查看版本 Docker MySql 查看版本的三种方法 1.m ...