HBase详解(01) - Hbase简介
HBase简介
- 定义:HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。
- 数据模型:逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map。
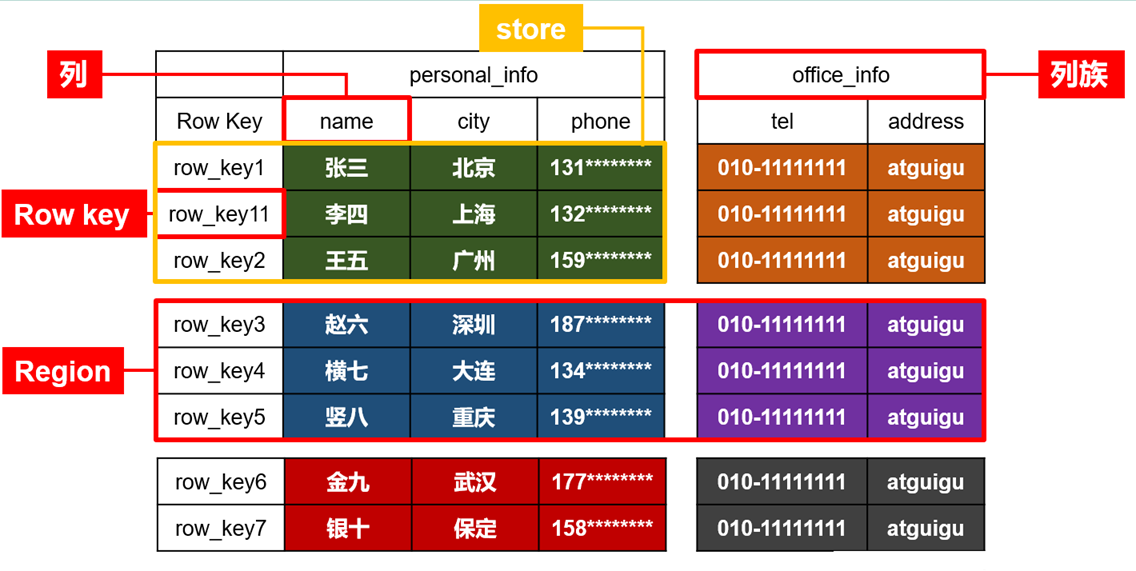
- HBase逻辑结构
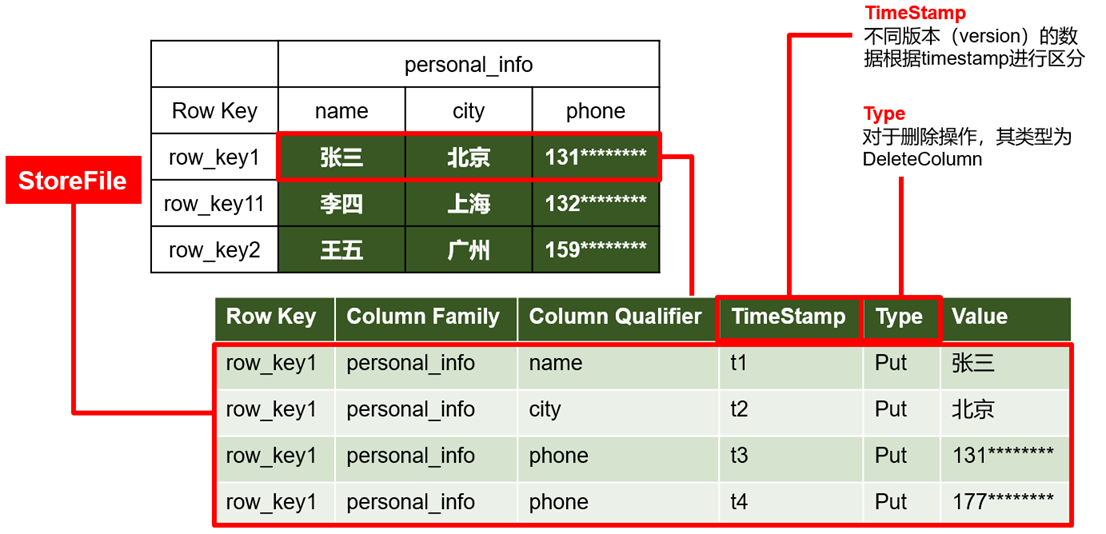
- 物理存储结构
- 数据模型
1)Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
2)Table
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
4)Column
HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell中的数据全部是字节码形式存贮。
- HBase基本架构
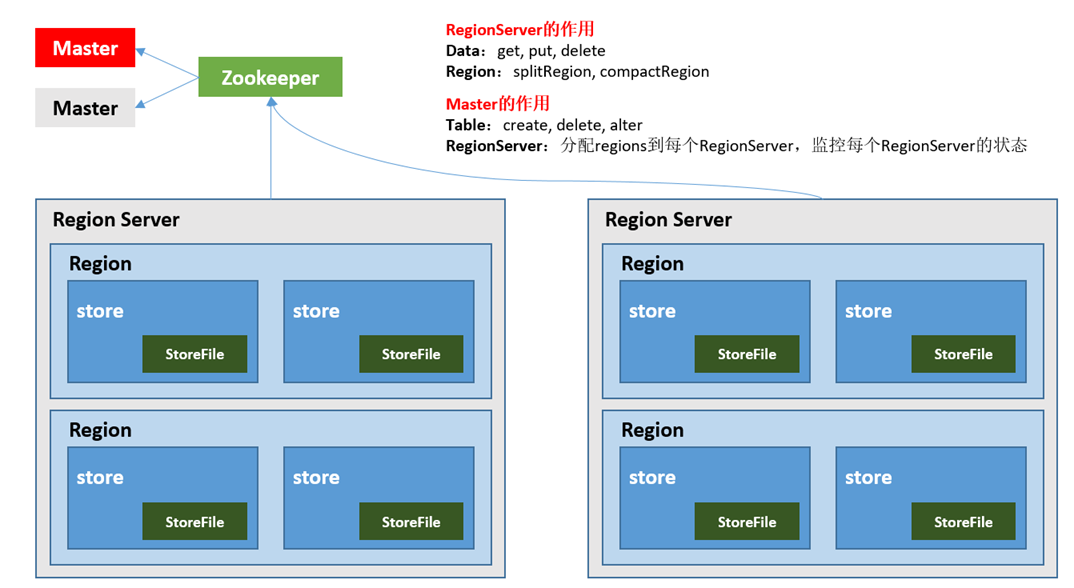
- 架构角色:
1)Region Server
Region Server为 Region的管理者,其实现类为HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于Region的操作:splitRegion、compactRegion。
2)Master
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
对于表的操作:create, delete, alter
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
3)Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
4)HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
HBase详解(01) - Hbase简介的更多相关文章
- HBase详解(05) - HBase优化 整合Phoenix 集成Hive
HBase详解(05) - HBase优化 整合Phoenix 集成Hive HBase优化 预分区 每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维 ...
- HBase详解(04) - HBase Java API使用
HBase详解(04) - HBase Java API使用 环境准备 新建Maven项目,在pom.xml中添加依赖 <dependency> <groupId>org.ap ...
- HBase详解(03) - HBase架构和数据读写流程
RegionServer 架构 每个RegionServer可以服务于多个Region 每个RegionServer中有多个Store, 1个WAL和1个BlockCache 每个Store对应一个列 ...
- [转帖]HBase详解(很全面)
HBase详解(很全面) very long story 简单看了一遍 很多不明白的地方.. 2018-06-08 16:12:32 卢子墨 阅读数 34857更多 分类专栏: HBase [转自 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- HBase详解(02) - HBase-2.0.5安装
HBase详解(02) - HBase-2.0.5安装 HBase安装环境准备 Zookeeper安装 Zookeeper安装参考<Zookeeper详解(02) - zookeeper安装部署 ...
- Hadoop详解(01)-概论
Hadoop详解(01)概论 概念 大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需要新处理模式才能具有更强的决策力.洞察发现力和流程优化能力的海量 ...
- Spark详解(01) - Scala编程语言
Spark详解(01) - Scala编程语言概述 Scala官网:https://www.scala-lang.org/ 什么是Scala 从英文的角度来讲,Scala并不是一个单词,而是Scala ...
- Hive详解(01) - 概念
Hive详解(01) - 概念 hive简介 Hive:由Facebook开源用于解决海量结构化日志的数据统计工具,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类S ...
随机推荐
- Mysql知识点整理
索引相关 abcd联合索引搜索ba会走索引么 会,重排 索引的底层实现是B+树,为何不采用红黑树,B树? (1):B+Tree非叶子节点只存储键值信息,降低B+Tree的高度,所有叶子节点之间都有一个 ...
- 齐博x1{:get_user_money(2,$uid)}
第一項是積分類型,第二項是用戶的UID, 在模板中用得最多的可能是 {:get_user_money(2,$uid)} 以管理員身份登錄後,在前台任何頁麵,隻要添加了標簽,雙擊就可以進入設置管理,如果 ...
- Redis—问题(1)
写在前面 Redis 是一种 NoSQL 数据库,包含多种数据结构.支持网络.基于内存.可选持久性的键值对存储数据库,在我们的日常开发中会经常使用 Redis 来解决许多问题,比如排行榜.消息队列系统 ...
- TASK 总结
信相连知识 1.python操作EXCEL 库:xlwings. 基本操作:打开.读写.关闭. 2.python操作问题库 库:JIRA 基本操作:提交问题 3.网页信息在网址不变时的获取 库:req ...
- CSS处理器-Less/Scss
HTML系列: 人人都懂的HTML基础知识-HTML教程 HTML元素大全(1) HTML元素大全(2)-表单 CSS系列: CSS基础知识筑基 常用CSS样式属性 CSS选择器大全48式 CSS布局 ...
- el-select实现下拉框触底加载更多
当下拉框需要展示的数据有很多时,几千甚至上万条,一次性全部请求回来再按照特定格式比如 id-name 去处理数据的话,不论是从接口还是前端,这个性能都不是很好,会造成下拉框初次打开时响应很慢,影响用户 ...
- 【云原生 · Kubernetes】搭建Harbor仓库
[云原生 · Kubernetes]Kubernetes基础环境搭建 接着上次的内容,后续来了! 4.部署Harbor仓库 在master节点执行脚本k8s_harbor_install.sh即可完成 ...
- 我的第一个项目(二):使用Vue做一个登录注册界面
好家伙, 顶不住了,太多的bug, 本来是想把背景用canvas做成动态的,但是,出现了各种问题 为了不耽误进度,我们先把一个简单的登录注册界面做出来 来看看效果: (看上去还不错) 本界面使用 ...
- C++ using 编译指令与名称冲突
using 编译指令:它由名称空间名和它前面的关键字 using namespace 组成,它使名称空间中的所有名称都可用,而不需要使用作用域解析运算符.在全局声明区域中使用 using 编译指令,将 ...
- (GDB) GDB调试技巧,调试命令
调试时查看依赖DSO pidof tvm_rpc_server cat /proc/<pid_of_tvm_rpc_server>/maps 子进程调试 1.vscode -- launc ...