HBase详解(01) - Hbase简介
HBase简介
- 定义:HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。
- 数据模型:逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map。
- HBase逻辑结构
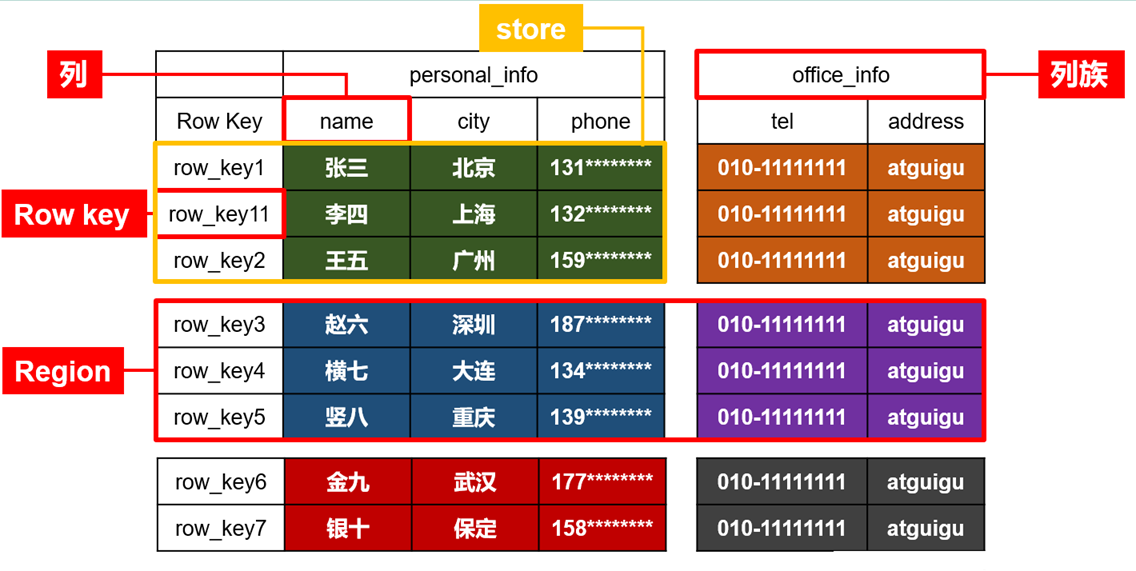
- 物理存储结构
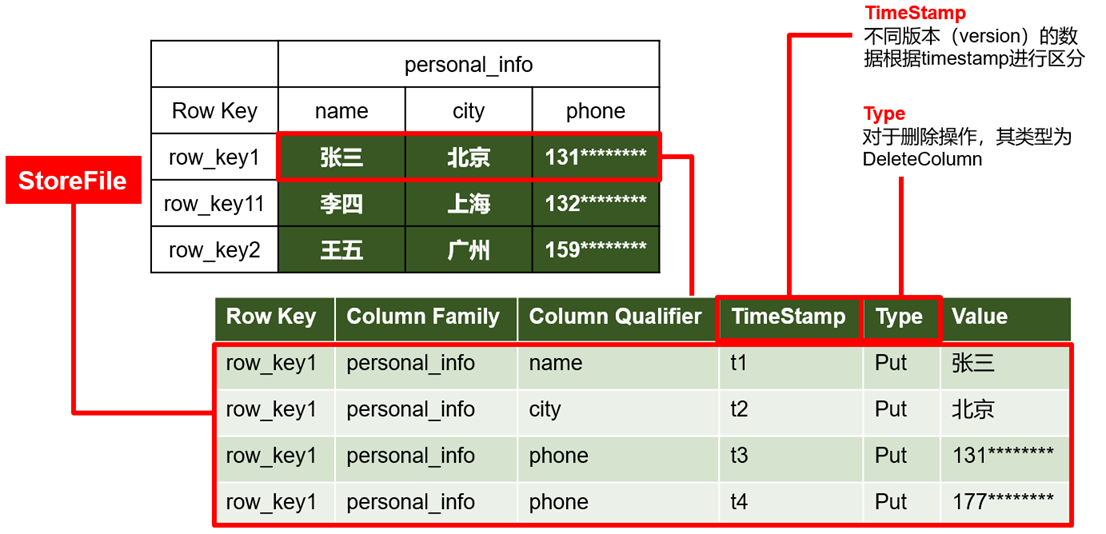
- 数据模型
1)Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
2)Table
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
4)Column
HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell中的数据全部是字节码形式存贮。
- HBase基本架构
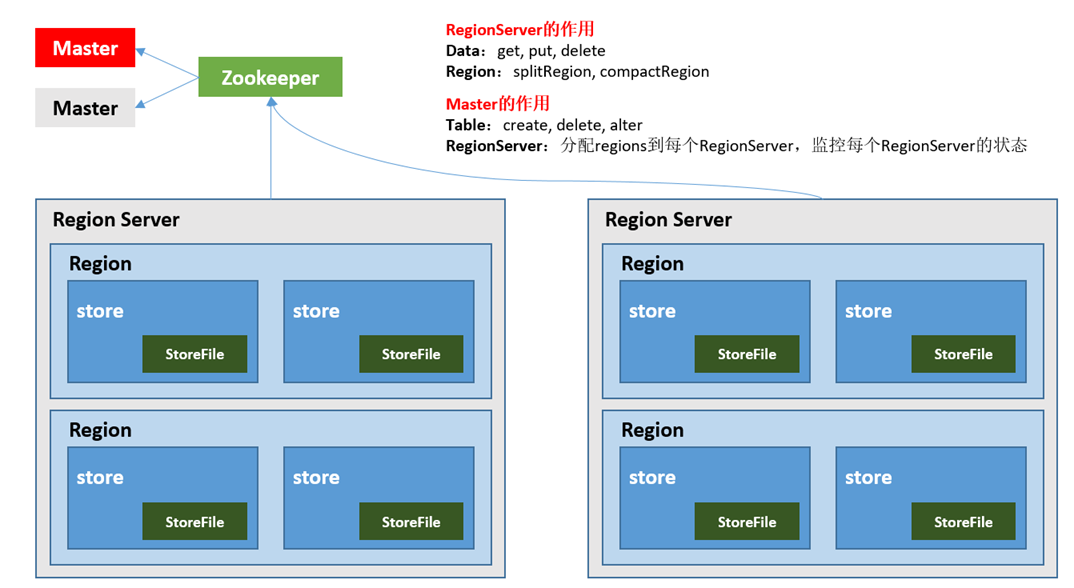
- 架构角色:
1)Region Server
Region Server为 Region的管理者,其实现类为HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于Region的操作:splitRegion、compactRegion。
2)Master
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
对于表的操作:create, delete, alter
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
3)Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
4)HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
HBase详解(01) - Hbase简介的更多相关文章
- HBase详解(05) - HBase优化 整合Phoenix 集成Hive
HBase详解(05) - HBase优化 整合Phoenix 集成Hive HBase优化 预分区 每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维 ...
- HBase详解(04) - HBase Java API使用
HBase详解(04) - HBase Java API使用 环境准备 新建Maven项目,在pom.xml中添加依赖 <dependency> <groupId>org.ap ...
- HBase详解(03) - HBase架构和数据读写流程
RegionServer 架构 每个RegionServer可以服务于多个Region 每个RegionServer中有多个Store, 1个WAL和1个BlockCache 每个Store对应一个列 ...
- [转帖]HBase详解(很全面)
HBase详解(很全面) very long story 简单看了一遍 很多不明白的地方.. 2018-06-08 16:12:32 卢子墨 阅读数 34857更多 分类专栏: HBase [转自 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- HBase详解(02) - HBase-2.0.5安装
HBase详解(02) - HBase-2.0.5安装 HBase安装环境准备 Zookeeper安装 Zookeeper安装参考<Zookeeper详解(02) - zookeeper安装部署 ...
- Hadoop详解(01)-概论
Hadoop详解(01)概论 概念 大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需要新处理模式才能具有更强的决策力.洞察发现力和流程优化能力的海量 ...
- Spark详解(01) - Scala编程语言
Spark详解(01) - Scala编程语言概述 Scala官网:https://www.scala-lang.org/ 什么是Scala 从英文的角度来讲,Scala并不是一个单词,而是Scala ...
- Hive详解(01) - 概念
Hive详解(01) - 概念 hive简介 Hive:由Facebook开源用于解决海量结构化日志的数据统计工具,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类S ...
随机推荐
- 22.通用视图GenericAPIView、属性和方法
generics.ListCreateAPIView #源码 class ListCreateAPIView(mixins.ListModelMixin, mixins.CreateModelMixi ...
- 三十二、kubernetes集群的网络实现
Kubernetes集群的网络实现 CNI介绍及集群网络选型 容器网络接口(Container Network Interface),实现kubernetes集群的Pod网络通信及管理.包括: CNI ...
- HTML躬行记(3)——WebRTC视频通话
WebRTC 在创建点对点(P2P)的连接之前,会先通过信令服务器交换两端的 SDP 和 ICE Candidate,取两者的交集,决定最终的音视频参数.传输协议.NAT 打洞方式等信息. 在完成媒体 ...
- 详细了解JVM运行时内存
详细了解JVM运行时内存 1.程序计数器 概念 程序计数器也叫作PC寄存器,是一块很小的内存区域,可以看做是当前线程执行的字节码的行号指示器.字节码的解释工作就是通过改变程序计数器里面的值来获得下一条 ...
- TASK 总结
信相连知识 1.python操作EXCEL 库:xlwings. 基本操作:打开.读写.关闭. 2.python操作问题库 库:JIRA 基本操作:提交问题 3.网页信息在网址不变时的获取 库:req ...
- 【jmeter】将“察看结果树”中的数据保存到本地
操作说明: 1. "察看结果树"页面,[配置]导出项: 2. "察看结果树"页面,[文件名]选框输入导出文件及路径: 3. 点击jmeter[启动]按钮,响应 ...
- 【笔记】P1606 [USACO07FEB]Lilypad Pond G 及相关
题目传送门 建图 首先,根据题目,可以判断出这是一道最短路计数问题. 但是要跑最短路,首先要用他给的信息建图,这是非常关键的一步. 根据题意,我们可以想出以下建图规则: 起点或是一个空白处可以花费 \ ...
- 如何查看mysql数据目录位置
mysql> show global variables like "%datadir%"; +---------------+-----------------+ | Va ...
- gin-巧用Context传递多种参数
目录 引言: 1.巧妙包装gin.Context为NewContext 2 在使用gin.Use对每一个请求的Context进行组装 3 在路由绑定时解析出NewContext来为应用层函数提供参数, ...
- 给ofo共享单车撸一个微信小程序
想学一下微信小程序,发现文档这东西,干看真没啥意思.所以打算自己先动手撸一个.摩拜单车有自己的小程序,基本功能都有,方便又小巧,甚是喜爱.于是我就萌生了一个给ofo共享单车撸一个小程序(不知道为啥of ...