spark中的持久化机制以及lineage和checkpoint(简含源码解析)
spark相比MapReduce最大的优势是,spark是基于内存的计算模型,有的spark应用比较复杂,如果中间出错了,那么只能根据lineage从头开始计算,所以为了避免这种情况,spark提供了两种持久化算子,如果用术语回答,持久化的目的就是为了容错。
存储级别
spark贴心地提供了多种存储级别供选择

这里解释一下StorageLevel的参数是什么
1._useDisk
2._useMemory
3._useOffHeap
4._deserialized
5._replication 默认值为1
里解释一下什么是OffHeap,我们知道一般java中对象是分配到jvm中的堆中,而OffHeap就是堆外内存,这片内存直接被操作系统管理而不是受jvm管理,这样的话可以减少GC的影响。
再解释下deserialized,是serialized的反过程,序列化和反序列化指得是对象与字节码文件间转换的过程。
如何选择存储级别
java、scala中的存储级别可以认为是DISK, MEMORY, SERIABLIZED和副本数之间排列组合,如何进行选择在官方文档上(文档地址可以直接搜spark或者去我上篇RDD算子介绍的博客中进入),我这里直接对原文进行硬翻
如果使用默认的存储级别(MEMORY_ONLY),存储在内存中的 RDD 没有发生溢出,那么就选择默认的存储级别。默认存储级别可以最大程度的提高 CPU 的效率,可以使在 RDD 上的操作以最快的速度运行
如果内存不能全部存储 RDD,那么使用 MEMORY_ONLY_SER,并挑选一个快速序列化库将对象序列化,以节省内存空间。使用这种存储级别,计算速度仍然很快
除了在计算该数据集的代价特别高,或者在需要过滤大量数据的情况下,尽量不要将溢出的数据存储到磁盘。因为,重新计算这个数据分区的耗时与从磁盘读取这些数据的耗时差不多。
如果想快速还原故障,建议使用多副本存储级别(例如,使用 Spark 作为 web 应用的后台服务,在服务出故障时需要快速恢复的场景下)。所有的存储级别都通过重新计算丢失的数据的方式,提供了完全容错机制。但是多副本级别在发生数据丢失时,不需要重新计算对应的数据库,可以让任务继续运行。
cache和persist算子的区别

可以看出,cache就是persist的偷懒版本,persist可以自定义StorageLevel,但是cache就是默认的MEMORY_ONLY
观察persist的源码
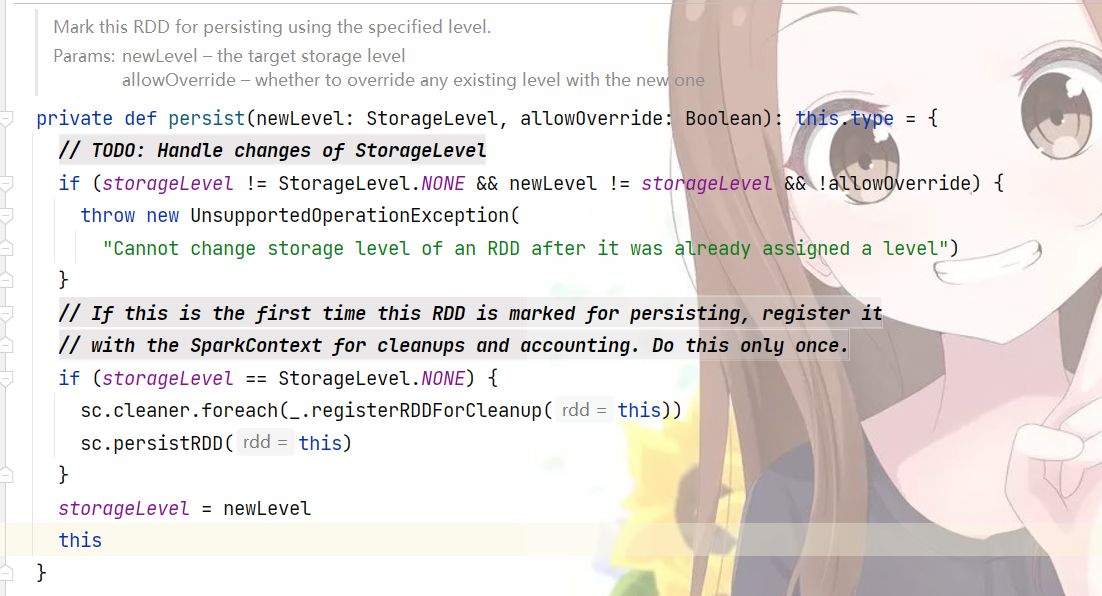

源码本身没什么好讲的,除了那个localcheckPointed,这个可以按下不表,在spark持久化中还有两个重要的概念,
checkpoint, lineage
checkpoint和lineage
checkpoint和lineage都是RDD容错的手段
lineage相当于族谱,记录了RDD变化的过程,这一点与mysql的redo log差不多,在发生错误的时候,通过lineage来重新运算获取数据,lineage描述的是RDD的变化链,有两种路径,一种是窄依赖,另一种是宽依赖,这两种依赖可以想像为独生和超生,一个父只对应一个孩子是窄依赖,一个父对应多个孩子叫做宽依赖。
checkpoint机制是来弥补lineage中宽依赖带来的冗余计算问题(理想中一个孩子丢了只需要“生”出丢失的孩子即可,但是实操如果要复原,只能父重新计算出所有孩子,带来了计算冗余”),对这种宽依赖或者说触发shuffle的算子加checkpoint是可以考虑的事情。checkpoint就是将数据导入可靠的具有容错的存储系统中,一般指定为hdfs,也可以是s3之类的,不过这样做的话会斩断依赖链
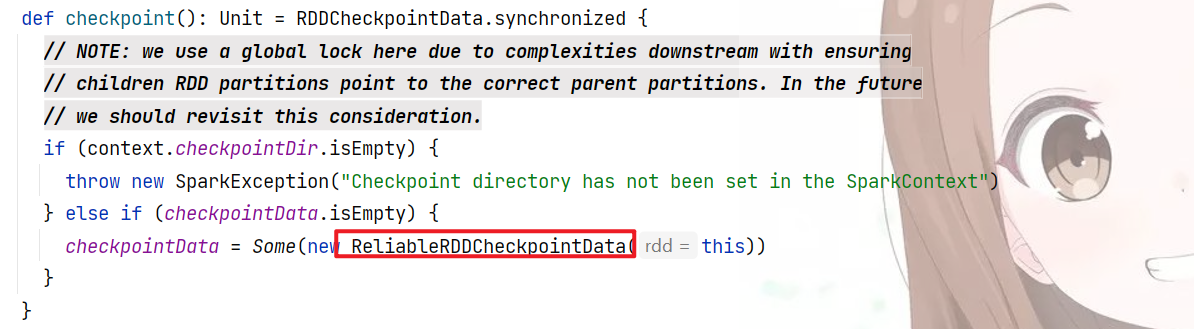
重要的代码也就是最后的赋值,这行代码的意思是标记这个RDD需要checkpointing,但是这个并没有立即执行,需要后面action触发才能执行,也就是
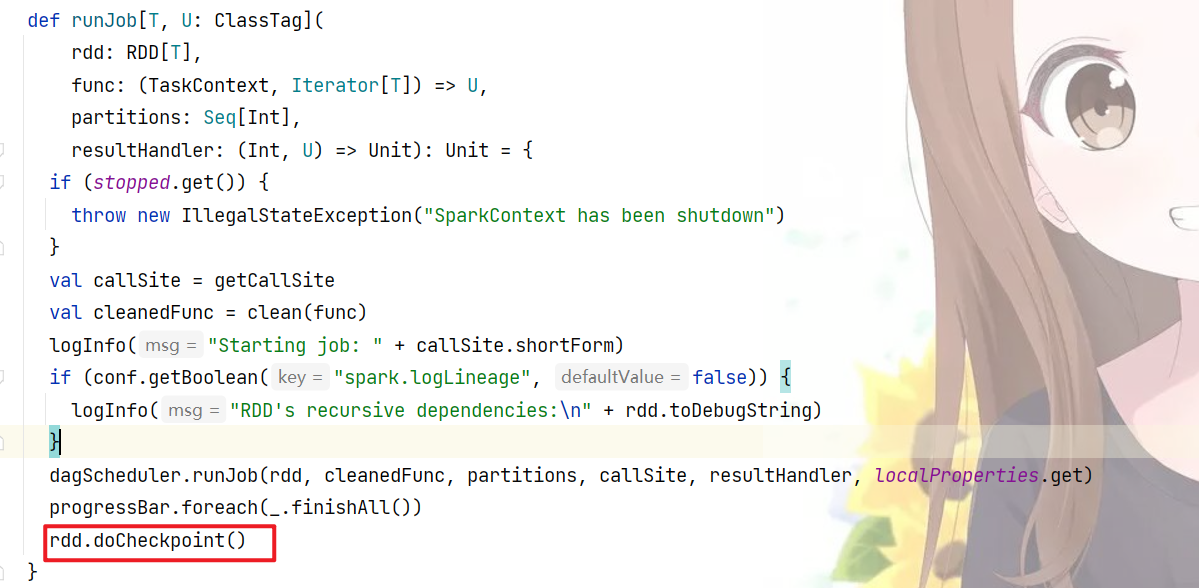
中的最后一行(runJob函数是每个action算子中必定执行的函数)
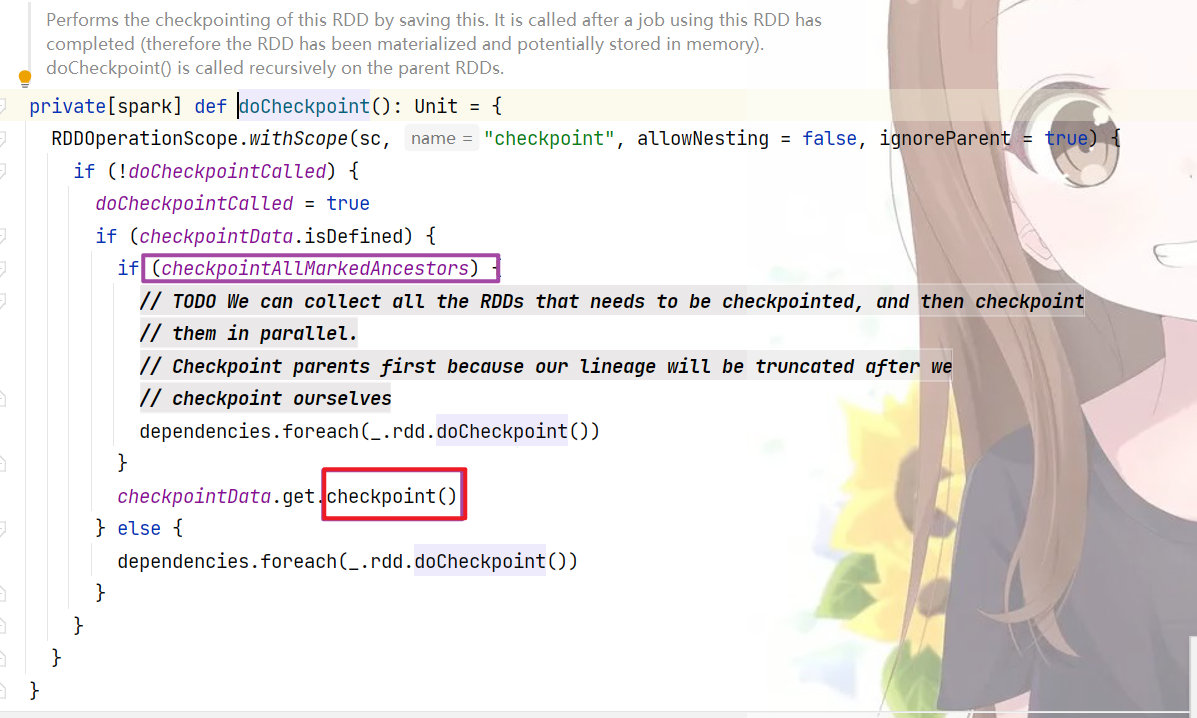
这段代码的意思一个RDD初始时doCheckPointCalled为false,经过一轮后为true,checkpointData.isDefined为true,则说明rdd已经被checkPoint过了,则真正执行进行checkpointData的真实checkpoint()操作,而上面的checkpointAllMarkedAncestors表示此RDD的祖先被checkpoint都通过这个job触发处理,默认是false,也就是说
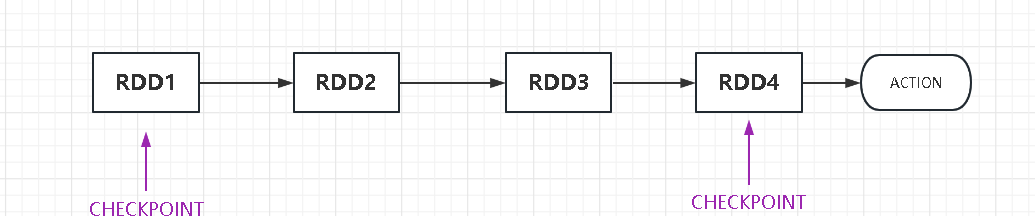
这个时候只会触发RDD4的checkpoint转存,而不会触发RDD1的转存
下面是真正执行checkpoint操作的函数
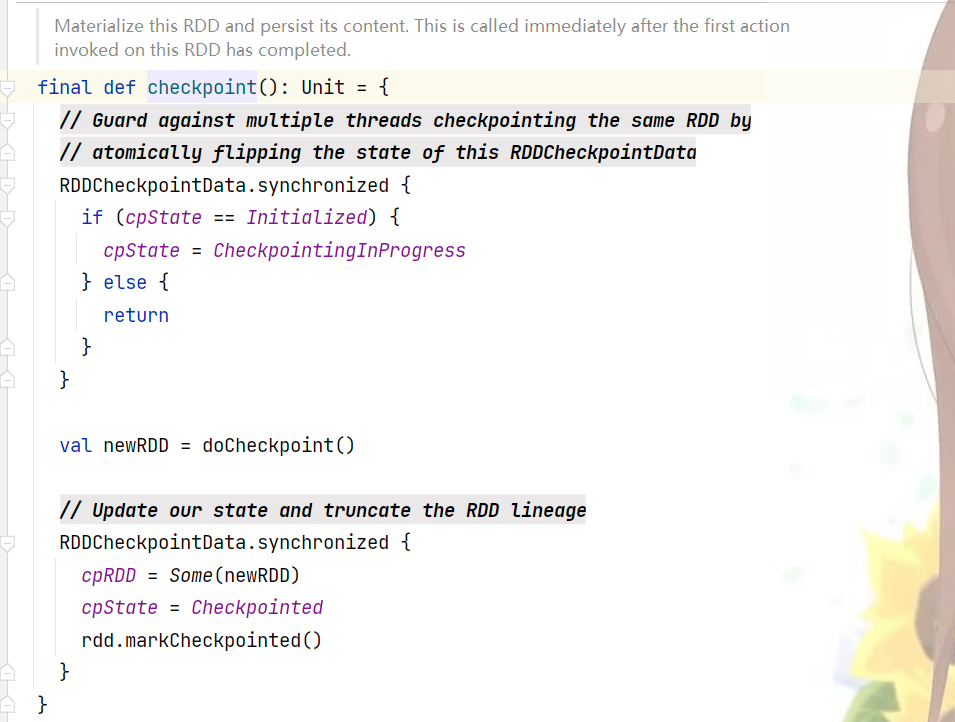
首先把cpState(RDDCheckpointData中的一个属性)置为CheckpointingInProgress,然后进行doCheckPoint操作产生newRDD,这里的doCheckPoint操作并没有实现,那么就去寻找它的子类,这时应该想起
这里,ReliableRDDCheckpointData,这个就是RDDCheckPoint的子类,里面实现doCheckpoint操作
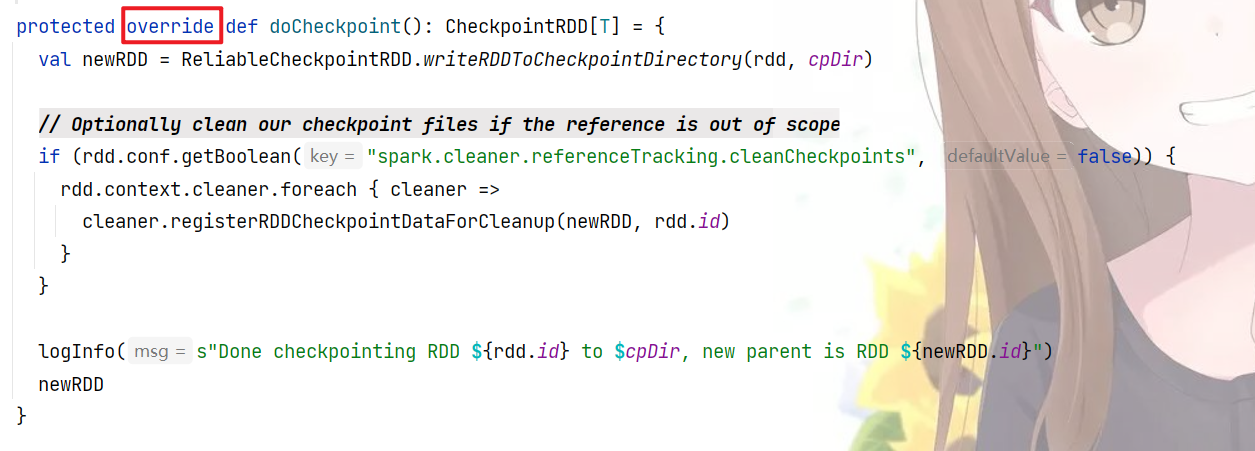
很明显,最重要的代码是 ReliableCheckpointRDD.writeRDDToCheckpointDirectory方法,下面给出它的代码,太长了就不截图了
点击查看代码
def writeRDDToCheckpointDirectory[T: ClassTag](
originalRDD: RDD[T],
checkpointDir: String,
blockSize: Int = -1): ReliableCheckpointRDD[T] = {
val checkpointStartTimeNs = System.nanoTime()
val sc = originalRDD.sparkContext
// Create the output path for the checkpoint
val checkpointDirPath = new Path(checkpointDir)
val fs = checkpointDirPath.getFileSystem(sc.hadoopConfiguration)
if (!fs.mkdirs(checkpointDirPath)) {
throw new SparkException(s"Failed to create checkpoint path $checkpointDirPath")
}
// Save to file, and reload it as an RDD
val broadcastedConf = sc.broadcast(
new SerializableConfiguration(sc.hadoopConfiguration))
// TODO: This is expensive because it computes the RDD again unnecessarily (SPARK-8582)
sc.runJob(originalRDD,
writePartitionToCheckpointFile[T](checkpointDirPath.toString, broadcastedConf) _)
if (originalRDD.partitioner.nonEmpty) {
writePartitionerToCheckpointDir(sc, originalRDD.partitioner.get, checkpointDirPath)
}
val checkpointDurationMs =
TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - checkpointStartTimeNs)
logInfo(s"Checkpointing took $checkpointDurationMs ms.")
val newRDD = new ReliableCheckpointRDD[T](
sc, checkpointDirPath.toString, originalRDD.partitioner)
if (newRDD.partitions.length != originalRDD.partitions.length) {
throw new SparkException(
"Checkpoint RDD has a different number of partitions from original RDD. Original " +
s"RDD [ID: ${originalRDD.id}, num of partitions: ${originalRDD.partitions.length}]; " +
s"Checkpoint RDD [ID: ${newRDD.id}, num of partitions: " +
s"${newRDD.partitions.length}].")
}
newRDD
}
这个函数的作用就是将rdd写入checkpointDir中(其实是hdfs中一个路径),然后生产newRDD,newRDD就是以写入hdfs目录中的rdd数据生产的rdd
最后执行下半程序,更新rdd并斩断lineage,斩断也就是将rdd中dependency属性置为null,整个过程就结束了
总结就是,RDD在进行checkPoint操作的时候先进行标记,然后直到action算子中的runJob函数里的docheckPoint才真正执行checkpoint操作,而具体如何checkpoint,依靠子类ReliableRDDCheckpointData中重写的checkpoint函数进行更新和斩断,更新rdd根据写入hdfs中的rdd数据进行生成,而斩断就是将生成的rdd的dependency属性置位null
spark中的持久化机制以及lineage和checkpoint(简含源码解析)的更多相关文章
- SpringtMVC中配置 <mvc:annotation-driven/> 与 <mvc:default-servlet-handler/> 的作用与源码解析
基于 Spring4.X 来学习 SpringtMVC, 在学习过程中,被"告知"在 XML 配置文件中建议设置如下两项: 一直不明白为什么,但又甘心.于是,花了一点时间来调试源码 ...
- [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark
[源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 0x00 摘要 0 ...
- [Spark內核] 第42课:Spark Broadcast内幕解密:Broadcast运行机制彻底解密、Broadcast源码解析、Broadcast最佳实践
本课主题 Broadcast 运行原理图 Broadcast 源码解析 Broadcast 运行原理图 Broadcast 就是将数据从一个节点发送到其他的节点上; 例如 Driver 上有一张表,而 ...
- Scala 深入浅出实战经典 第65讲:Scala中隐式转换内幕揭秘、最佳实践及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第61讲:Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- Scala 深入浅出实战经典 第60讲:Scala中隐式参数实战详解以及在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第48讲:Scala类型约束代码实战及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Spark 源码解析 : DAGScheduler中的DAG划分与提交
一.Spark 运行架构 Spark 运行架构如下图: 各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规 ...
- Spark Broadcast内幕解密:Broadcast运行机制彻底解密、Broadcast源码解析、Broadcast最佳实践
本课主题 Broadcast 运行原理图 Broadcast 源码解析 Broadcast 运行原理图 Broadcast 就是将数据从一个节点发送到其他的节点上; 例如 Driver 上有一张表,而 ...
- [源码解析] 从TimeoutException看Flink的心跳机制
[源码解析] 从TimeoutException看Flink的心跳机制 目录 [源码解析] 从TimeoutException看Flink的心跳机制 0x00 摘要 0x01 缘由 0x02 背景概念 ...
随机推荐
- vue后台管理系统——权限管理模块
电商后台管理系统的功能--权限管理模块 1. 权限管理业务分析 通过权限管理模块控制不同的用户可以进行哪些操作,具体可以通过角色的方式进行控制,即每个用户分配一个特定的角色,角色包括不同的功能权限. ...
- WSGI网站部署以及requests请求的一些随想.
一直想项目,没怎么写过后端服务,但很多时候,有些服务又是公用的,平时一般都用redis来当做通信的中间件,但这个标准的通用型与扩展信太差了. 与一些群友交流,建议还是起http服务比较好,自己也偏向与 ...
- Linux(CentOS7)中安装Docker
Linux(CentOS7)中安装Docker 什么是Docker? Docker是一个开源项目, 诞生于2013年初,最初是dotCloud公司内部的一个业余项目.它基于Google公司推出的Go语 ...
- 06 显示fps帧频
需要看fps就用下面这段代码即可 var FPS = {};FPS.time = 0;FPS.FPS = 0; FPS.startFPS = function (stage){ FPS.shape = ...
- Tesstwo9.1.0配置步骤
一,配置步骤 环境:Tesstwo9.1.0+Android10(华为)+Android11(模拟器) 1.查看tess-two的最新版本(GitHub - rmtheis/tess-two: For ...
- 数论之GCD+LCM+扩展欧几里得
最大公约数GCD 整数a和b的最大公约数记为gcd(a,b) <1 经典的欧几里得算法,辗转相除法 int gcd(int a, int b){ return b == 0 ? a : gcd( ...
- 关于vue模版动态加载按照指定条件
一.在data中定义要作为模版的变量,当前定义了两个 menuNavigation 和menuDetails 二.模版使用方式使用component中的 用v-bind:is 来使用其参数
- 4组-Beta冲刺-3/5
一.基本情况 队名:摸鲨鱼小队 组长博客:https://www.cnblogs.com/smallgrape/p/15600609.html github链接:https://github.com/ ...
- 2022/7/28 第七组陈美娜 API类
API:Application Program Interface应用程序接口 JDK给我们提供的一些已经写好的类,可以直接调方法来解决问题 类的方法在宏观上都可以称为接口 接口:1.interfac ...
- puts()与scanf(“%s”)
使用gets()即使字符串中含有空格,依然可以接收,而scanf()不会. Example: /* 输入一个字符串到字符数组s1中,将s1中的字符串复制到字符数组s2中并输出s2中的字符串. 不用st ...