11月17日内容总结——黏包现象、struct模块和解决黏包问题的流程、UDP协议、并发编程理论、多道程序设计技术及进程理论
一、黏包现象
什么是黏包
1.服务端连续执行三次recv(字节数需要大一些)
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
sock, addr = server.accept()
data1 = sock.recv(1024)
print(data1)
data2 = sock.recv(1024)
print(data2)
data3 = sock.recv(1024)
print(data3)
sock.close()
server.close()
2.客户端连续执行三次send
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8081))
client.send(b'hello kevin')
client.send(b'jason say hei')
client.send(b'jerry say goodbye')
问题:服务端一次性接收到了客户端三次的消息 该现象称为"黏包现象"
黏包现象产生的原因
1.不知道每次的数据到底多大
2.TCP也称为流式协议:数据像水流一样绵绵不绝没有间隔(TCP会针对数据量较小且发送间隔较短的多条数据一次性合并打包发送)
在知道了产生的原因后我们可以想到避免黏包现象的核心思路\关键点在于如何明确即将接收的数据具体有多大
ps:如何将长度变化的数据全部制作成固定长度的数据
二、struct模块及解决黏包问题的流程
struct模块
在处理黏包现象之前需要学习一个新模块:struct模块
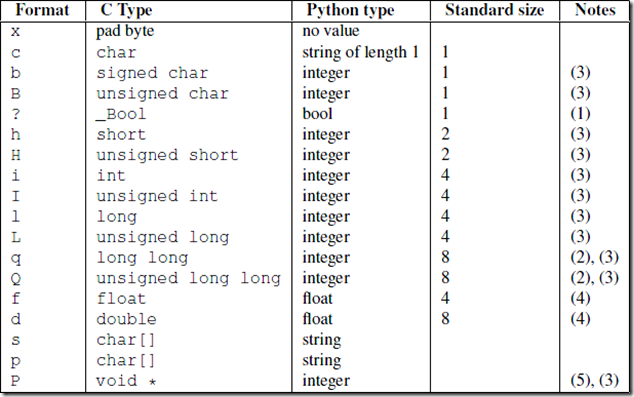
该模块可以把一个类型,如数字,转成固定长度的bytes(当然了,有长度限制)
import struct
info = b'hello big baby'
print(len(info)) # 数据真实的长度(bytes) 14
res = struct.pack('i', len(info)) # 将数据打包成固定的长度 i是固定的打包模式
print(len(res)) # 打包之后长度为(bytes) 4 报头
real_len = struct.unpack('i', res)
print(real_len) # (14,) 根据固定长度的报头 解析出真实数据的长度
desc = b'hello my baby I will take you to play big ball'
print(len(desc)) # 数据真实的长度(bytes) 46
res1 = struct.pack('i', len(desc))
print(len(res1)) # 打包之后长度为(bytes) 4 报头
real_len1 = struct.unpack('i', res1)
print(real_len1) # (46,) 根据固定长度的报头 解析出真实数据的长度
这里我们发现struct模块可以把对应的数据类型打包成固定的二进制长度然后还可以解压回去。
解决黏包问题初级版本
客户端
1.将真实数据转成bytes类型并计算长度
2.利用struct模块将真实长度制作一个固定长度的报头
3.将固定长度的报头先发送给服务端 服务端只需要在recv括号内填写固定长度的报头数字即可
4.然后再发送真实数据
服务端
1.服务端先接收固定长度的报头
2.利用struct模块反向解析出真实数据长度
3.recv接收真实数据长度即可
解决过程中遇到的问题
问题1:
struct模块无法打包数据量较大的数据,就算换更大的模式也不行
问题2:
报头能否传递更多的信息 比如电影大小 电影名称 电影评价 电影简介
解决黏包问题终极解决方案
字典作为报头打包 效果更好 数字更小
import struct
data_dict = {
'file_name': 'xxx老师教学.avi',
'file_size': 123132131232342342423423423423432423432,
'file_info': '内容很精彩 千万不要错过',
'file_desc': '一代神作 私人珍藏'
}
import json
data_json = json.dumps(data_dict)
print(len(data_json.encode('utf8'))) # 真实字典的长度 228
res = struct.pack('i', len(data_json.encode('utf8')))
print(len(res))
客户端
1.制作真实数据的信息字典(数据长度、数据简介、数据名称)
2.利用struct模块制作字典的报头
3.发送固定长度的报头(解析出来是字典的长度)
4.发送字典数据
5.发送真实数据
服务端
1.接收固定长度的字典报头
2.解析出字典的长度并接收
3.通过字典获取到真实数据的各项信息
4.接收真实数据长度
三、粘包代码实战
服务端
import socket
import struct
import json
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
sock, addr = server.accept()
# 1.接收固定长度的字典报头
data_dict_head = sock.recv(4)
# 2.根据报头解析出字典数据的长度
data_dict_len = struct.unpack('i', data_dict_head)[0]
# 3.接收字典数据
data_dict_bytes = sock.recv(data_dict_len)
data_dict = json.loads(data_dict_bytes) # 自动解码再反序列化
# 4.获取真实数据的各项信息
# total_size = data_dict.get('file_size')
# with open(data_dict.get('file_name'), 'wb') as f:
# f.write(sock.recv(total_size))
'''接收真实数据的时候 如果数据量非常大 recv括号内直接填写该数据量 不太合适 我们可以每次接收一点点 反正知道总长度'''
# total_size = data_dict.get('file_size')
# recv_size = 0
# with open(data_dict.get('file_name'), 'wb') as f:
# while recv_size < total_size:
# data = sock.recv(1024)
# f.write(data)
# recv_size += len(data)
# print(recv_size)
客户端
import socket
import os
import struct
import json
client = socket.socket()
client.connect(('127.0.0.1', 8081))
'''任何文件都是下列思路 图片 视频 文本 ...'''
# 1.获取真实数据大小
file_size = os.path.getsize(r'/Users/jiboyuan/PycharmProjects/day36/xx老师合集.txt')
# 2.制作真实数据的字典数据
data_dict = {
'file_name': '有你好看.txt',
'file_size': file_size,
'file_desc': '内容很长 准备好吃喝 我觉得营养快线挺好喝',
'file_info': '这是我的私人珍藏'
}
# 3.制作字典报头
data_dict_bytes = json.dumps(data_dict).encode('utf8')
data_dict_len = struct.pack('i', len(data_dict_bytes))
# 4.发送字典报头
client.send(data_dict_len) # 报头本身也是bytes类型 我们在看的时候用len长度是4
# 5.发送字典
client.send(data_dict_bytes)
# 6.最后发送真实数据
with open(r'/Users/jiboyuan/PycharmProjects/day36/xx老师合集.txt', 'rb') as f:
for line in f: # 一行行发送 和直接一起发效果一样 因为TCP流式协议的特性
client.send(line)
import time
time.sleep(10)
四、UDP协议(了解)
1.UDP服务端和客户端'各自玩各自的'
2.UDP不会出现多个消息发送合并
五、并发编程理论
研究网络编程其实就是在研究计算机的底层原理及发展史
在学习计算机基础知识的时候我们了解到计算机中真正干活的是CPU
操作系统发展史
1、手工操作 —— 穿孔卡片
1946年第一台计算机诞生--20世纪50年代中期,计算机工作还在采用手工操作方式。此时还没有操作系统的概念。


程序员将对应于程序和数据的已穿孔的纸带(或卡片)装入输入机,然后启动输入机把程序和数据输入计算机内存,接着通过控制台开关启动程序针对数据运行;计算完毕,打印机输出计算结果;用户取走结果并卸下纸带(或卡片)后,才让下一个用户上机。
手工操作方式两个特点:
(1)用户独占全机。不会出现因资源已被其他用户占用而等待的现象,但资源的利用率低。
(2)CPU 等待手工操作。CPU的利用不充分。
20世纪50年代后期,出现人机矛盾:手工操作的慢速度和计算机的高速度之间形成了尖锐矛盾,手工操作方式已严重损害了系统资源的利用率(使资源利用率降为百分之几,甚至更低),不能容忍。唯一的解决办法:只有摆脱人的手工操作,实现作业的自动过渡。这样就出现了成批处理。
2、批处理 —— 磁带存储
批处理系统:加载在计算机上的一个系统软件,在它的控制下,计算机能够自动地、成批地处理一个或多个用户的作业(这作业包括程序、数据和命令)。
提前使用磁带一次性录入多个程序员编写的程序 然后交给计算机执行
CPU工作效率有所提升 不用反复等待程序录入
1.联机批处理系统
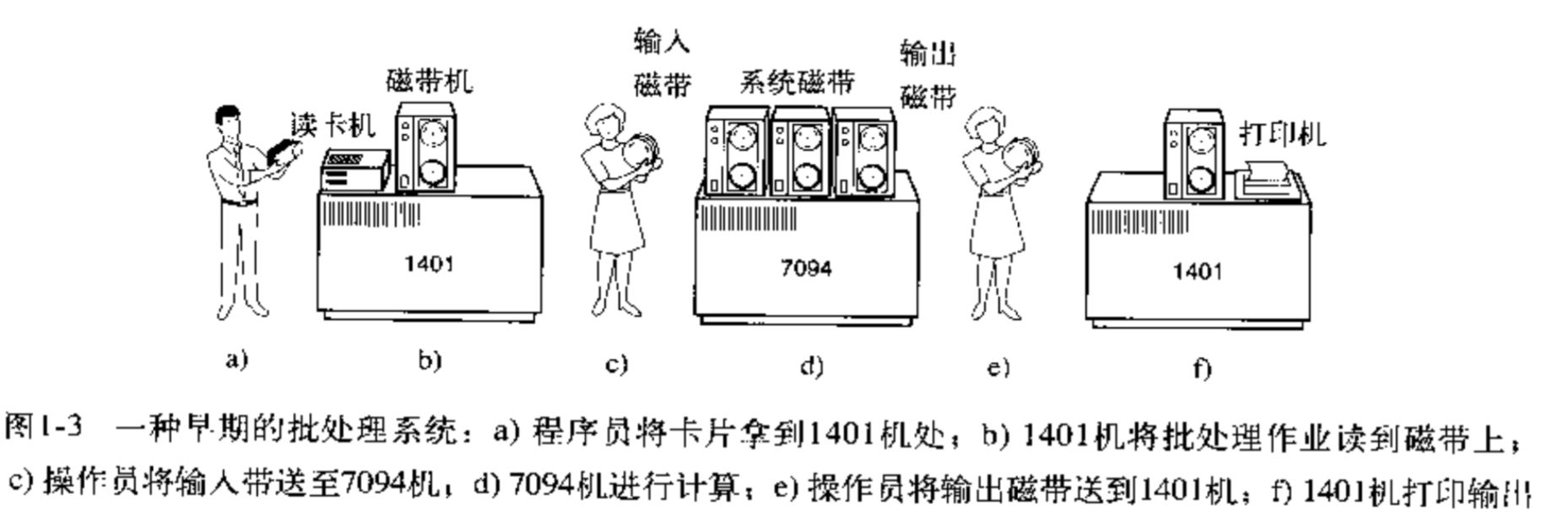
首先出现的是联机批处理系统,即作业的输入/输出由CPU来处理。
主机与输入机之间增加一个存储设备——磁带,在运行于主机上的监督程序的自动控制下,计算机可自动完成:成批地把输入机上的用户作业读入磁带,依次把磁带上的用户作业读入主机内存并执行并把计算结果向输出机输出。完成了上一批作业后,监督程序又从输入机上输入另一批作业,保存在磁带上,并按上述步骤重复处理。
监督程序不停地处理各个作业,从而实现了作业到作业的自动转接,减少了作业建立时间和手工操作时间,有效克服了人机矛盾,提高了计算机的利用率。
但是,在作业输入和结果输出时,主机的高速CPU仍处于空闲状态,等待慢速的输入/输出设备完成工作: 主机处于“忙等”状态。
2.脱机批处理系统
为克服与缓解:高速主机与慢速外设的矛盾,提高CPU的利用率,又引入了脱机批处理系统,即输入/输出脱离主机控制。
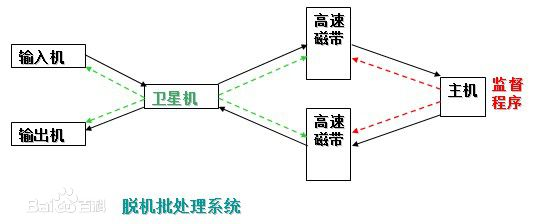
卫星机:一台不与主机直接相连而专门用于与输入/输出设备打交道的。
其功能是:
(1)从输入机上读取用户作业并放到输入磁带上。
(2)从输出磁带上读取执行结果并传给输出机。
这样,主机不是直接与慢速的输入/输出设备打交道,而是与速度相对较快的磁带机发生关系,有效缓解了主机与设备的矛盾。主机与卫星机可并行工作,二者分工明确,可以充分发挥主机的高速计算能力。
脱机批处理系统:20世纪60年代应用十分广泛,它极大缓解了人机矛盾及主机与外设的矛盾。
不足:每次主机内存中仅存放一道作业,每当它运行期间发出输入/输出(I/O)请求后,高速的CPU便处于等待低速的I/O完成状态,致使CPU空闲。
为改善CPU的利用率,又引入了多道程序系统。
六、多道程序设计技术
- 在学习并发编程的过程中 不做刻意提醒的情况下 默认一台计算机就一个CPU(只有一个干活的人)
所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
单道技术
所有的程序排队执行 过程中不能重合
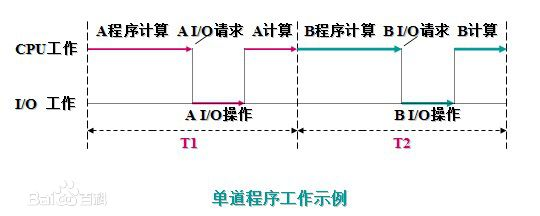
在A程序计算时,I/O空闲, A程序I/O操作时,CPU空闲(B程序也是同样);必须A工作完成后,B才能进入内存中开始工作,两者是串行的,全部完成共需时间=T1+T2。
多道技术
所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
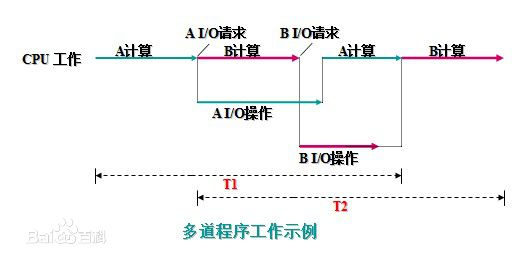
将A、B两道程序同时存放在内存中,它们在系统的控制下,可相互穿插、交替地在CPU上运行:当A程序因请求I/O操作而放弃CPU时,B程序就可占用CPU运行,这样 CPU不再空闲,而正进行A I/O操作的I/O设备也不空闲,显然,CPU和I/O设备都处于“忙”状态,大大提高了资源的利用率,从而也提高了系统的效率,A、B全部完成所需时间小于T1+T2。
多道技术详细
1.切换
计算机的CPU在两种情况下会切换(不让你用 给别人用)
1.程序有IO操作
I/O操作:一般指内存与磁盘间的输入输出流操作
input、time.sleep、read、write
2.程序长时间占用CPU
我们得雨露均沾 让多个程序都能被CPU运行一下
2.保存状态
CPU每次切换走之前都需要保存当前操作的状态 下次切换回来基于上次的进度继续执行
开了一家饭店 只有一个服务员 但是同时来了五桌客人
请问:如何让五桌客人都感觉到服务员在服务他们
让服务员化身为闪电侠 只要客人有停顿 就立刻切换到其他桌 如此往复
总结
多道程序设计技术不仅使CPU得到充分利用,同时改善I/O设备和内存的利用率,从而提高了整个系统的资源利用率和系统吞吐量(单位时间内处理作业(程序)的个数),最终提高了整个系统的效率。
单处理机系统中多道程序运行时的特点:
(1)多道:计算机内存中同时存放几道相互独立的程序;
(2)宏观上并行:同时进入系统的几道程序都处于运行过程中,即它们先后开始了各自的运行,但都未运行完毕;
(3)微观上串行:实际上,各道程序轮流地用CPU,并交替运行。
七、进程理论
进程与程序的区别
程序:一堆死代码(还没有被运行起来)
进程:正在运行的程序(被运行起来了)
进程的调度算法(重要)
1.FCFS(先来先服务)
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。FCFS算法比较有利于长作业(进程),而不利于短作业(进程)。由此可知,本算法适合于CPU繁忙型作业,而不利于I/O繁忙型的作业(进程)。
简单来说就是谁先来,cpu就先给谁服务。但是会导致后面的进程要排队很久。
2.短作业优先调度
短作业(进程)优先调度算法(SJ/PF)是指对短作业或短进程优先调度的算法,该算法既可用于作业调度,也可用于进程调度。但其对长作业不利;不能保证紧迫性作业(进程)被及时处理;作业的长短只是被估算出来的。
这个算法的处理方式可以概括成,优先处理耗时短的进程,但是这种算法在进程很多的时候,会导致耗时很长的进程得不到运行。
3.时间片轮转法+多级反馈队列(目前还在用)
时间片轮转法
时间片轮转(Round Robin,RR)法的基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。在时间片轮转法中,需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。如果一个进程在被调度选中之后用完了系统规定的时间片,但又未完成要求的任务,则它自行释放自己所占有的CPU而排到就绪队列的末尾,等待下一次调度。同时,进程调度程序又去调度当前就绪队列中的第一个进程。
显然,轮转法只能用来调度分配一些可以抢占的资源。这些可以抢占的资源可以随时被剥夺,而且可以将它们再分配给别的进程。CPU是可抢占资源的一种。但打印机等资源是不可抢占的。由于作业调度是对除了CPU之外的所有系统硬件资源的分配,其中包含有不可抢占资源,所以作业调度不使用轮转法。
在轮转法中,时间片长度的选取非常重要。首先,时间片长度的选择会直接影响到系统的开销和响应时间。如果时间片长度过短,则调度程序抢占处理机的次数增多。这将使进程上下文切换次数也大大增加,从而加重系统开销。反过来,如果时间片长度选择过长,例如,一个时间片能保证就绪队列中所需执行时间最长的进程能执行完毕,则轮转法变成了先来先服务法。时间片长度的选择是根据系统对响应时间的要求和就绪队列中所允许最大的进程数来确定的。
在轮转法中,加入到就绪队列的进程有3种情况:
一种是分给它的时间片用完,但进程还未完成,回到就绪队列的末尾等待下次调度去继续执行。
另一种情况是分给该进程的时间片并未用完,只是因为请求I/O或由于进程的互斥与同步关系而被阻塞。当阻塞解除之后再回到就绪队列。
第三种情况就是新创建进程进入就绪队列。
如果对这些进程区别对待,给予不同的优先级和时间片从直观上看,可以进一步改善系统服务质量和效率。例如,我们可把就绪队列按照进程到达就绪队列的类型和进程被阻塞时的阻塞原因分成不同的就绪队列,每个队列按FCFS原则排列,各队列之间的进程享有不同的优先级,但同一队列内优先级相同。这样,当一个进程在执行完它的时间片之后,或从睡眠中被唤醒以及被创建之后,将进入不同的就绪队列。
多级反馈队列
前面介绍的各种用作进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法使用。
而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。在采用多级反馈队列调度算法的系统中,调度算法的实施过程如下所述。
(1) 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权愈高的队列中,为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍,……,第i+1个队列的时间片要比第i个队列的时间片长一倍。
(2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,再同样地按FCFS原则等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,再依次将它放入第三队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第n队列后,在第n 队列便采取按时间片轮转的方式运行。
(3) 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第1~(i-1)队列均空时,才会调度第i队列中的进程运行。如果处理机正在第i队列中为某进程服务时,又有新进程进入优先权较高的队列(第1~(i-1)中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行的进程放回到第i队列的末尾,把处理机分配给新到的高优先权进程。
时间片轮转法+多级反馈队列执行时的情况
将时间均分 然后根据进程时间长短再分多个等级,等级越靠下表示耗时越长,每次分到的时间越多,但是优先级越低。优先级低的会出现被插队的情况。
八、进程的并行与并发
并行 : 并行是指两者同时执行,比如赛跑,两个人都在不停的往前跑。(资源够用,比如三个线程,四核的CPU )
多个进程同时执行,必须要有多个CPU参与,单个CPU无法实现并行。(cpu数量要和进程数量一致或比进程数量多)
并发 : 并发是指资源有限的情况下,两者交替轮流使用资源,比如一段路(单核CPU资源)同时只能过一个人,A走一段后,让给B,B用完继续给A ,交替使用,目的是提高效率。
使用时间片轮转法+多级反馈队列,使多个进程看上去像同时执行。单个CPU可以实现,多个CPU肯定也可以实现。
区别:
并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。
并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个session。
判断下列两句话孰对孰错
我写的程序很牛逼,运行起来之后可以实现14个亿的并行量(错的,哪有程序会用到14个亿的cpu,成本太高了)
并行量必须要有对等的CPU才可以实现
我写的程序很牛逼,运行起来之后可以实现14个亿的并发量
合情合理,完全可以实现,以后我们的项目一般都会追求高并发
ps:目前国内可以说是最牛逼的并发程序>>>:12306
九、进程的三状态
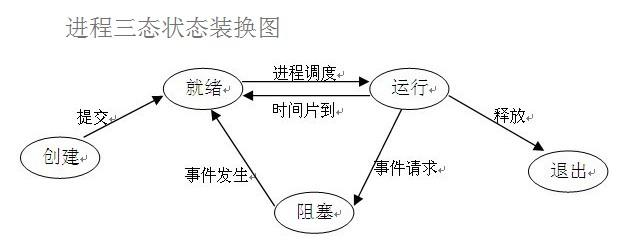
(1)就绪(Ready)状态
当进程已分配到除CPU以外的所有必要的资源,只要获得处理机会便可立即执行,这时的进程状态称为就绪状态。
(2)执行/运行(Running)状态
当进程已获得处理机会,其程序正在处理机上执行,此时的进程状态称为执行状态。
(3)阻塞(Blocked)状态
正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。
十、作业
1.编写电影上传或者下载的功能
可以两个同学合作体验
课外扩展:如何展示某个目录下多个文件内容选择性下载或者上传
扩展版本:
说明:
传数据和收数据的时候,两边的发送方式要一致,如果客户端使用for循环一点一点发送信息,服务端也要使用for循环接收,否则数据接收不全。
服务端
import socket
import struct
import json
import os
server = socket.socket()
server.bind(('192.168.1.186', 8088))
server.listen(5)
while True:
sock, addr = server.accept()
while True: # 通信循环
try:
# 1.接收固定长度的字典报头
data_dict_head = sock.recv(4)
# 2.根据报头解析出字典数据的长度
data_dict_len = struct.unpack('i', data_dict_head)[0]
# 3.接收字典数据
data_dict_bytes = sock.recv(data_dict_len)
data_dict = json.loads(data_dict_bytes) # 自动解码再反序列化
print(data_dict['file_name'])
# 打印文件名称判断是否需要保存
receive_or_not = input('请选择是否需要接收:\n1、接收\n2、不接收\n请输入编号:').strip()
# 需要保存输入1不如要输入2
# 4.获取真实数据的各项信息
# total_size = data_dict.get('file_size')
# with open(data_dict.get('file_name'), 'wb') as f:
# f.write(sock.recv(total_size))
'''接收真实数据的时候 如果数据量非常大 recv括号内直接填写该数据量 不太合适 我们可以每次接收一点点 反正知道总长度'''
total_size = data_dict.get('file_size')
recv_size = 0
with open(data_dict.get('file_name'), 'wb') as f:
while recv_size < total_size:
data = sock.recv(1024)
f.write(data)
recv_size += len(data)
# print(recv_size)
print('成功保存')
if receive_or_not == '2':
# 如果输入了2,就把保存下来的文件删了
now_path = os.path.dirname(__file__)
del_path = os.path.join(now_path,data_dict['file_name'])
os.remove(del_path)
print('成功删除')
except BaseException:
# 当客户端直接退出的时候服务端这边会报错,我们用异常处理让程序跳过这些会报错的代码,继续运行
break
客户端
import socket
import os
import struct
import json
client = socket.socket()
client.connect(('192.168.1.186', 8088))
'''任何文件都是下列思路 图片 视频 文本 ...'''
doc_path = r'D:\file'
file_list = os.listdir(doc_path)
is_file = True
print(file_list)
if not file_list:
print('文件夹中当前没有文件')
is_file = False
# 如果文件夹中没有文件就不传文件给服务端
while is_file:
# 如果文件夹中有文件就输出
for i, j in enumerate(file_list):
print(f'''
编号:{i}
文件名称:{j}
''')
# 根据文件的编号选择需要传输的文件
file_number = input('请输入需要传输的文件的编号:').strip()
# 这里对编号做一些判断
if file_number == '':
print('编号不能为空')
continue
if int(file_number) not in range(0,len(file_list)):
print('编号不在范围内')
continue
if not file_number.isdigit():
print('编号需要是数字')
continue
# 获取文件的名称和路径
file_name = file_list[int(file_number)]
file_path = os.path.join(doc_path, file_name)
# 1.获取真实数据大小
file_size = os.path.getsize(file_path)
# 2.制作真实数据的字典数据
data_dict = {
'file_name': file_name,
'file_size': file_size,
'file_desc': '内容很长 准备好吃喝 我觉得营养快线挺好喝',
'file_info': '这是我的私人珍藏'
}
# 3.制作字典报头
data_dict_bytes = json.dumps(data_dict).encode('utf8')
data_dict_len = struct.pack('i', len(data_dict_bytes))
# 4.发送字典报头
client.send(data_dict_len) # 报头本身也是bytes类型 我们在看的时候用len长度是4
# 5.发送字典
client.send(data_dict_bytes)
# 6.最后发送真实数据
with open(file_path, 'rb') as f:
for line in f: # 一行行发送 和直接一起发效果一样 因为TCP流式协议的特性
client.send(line)
import time
time.sleep(10)
11月17日内容总结——黏包现象、struct模块和解决黏包问题的流程、UDP协议、并发编程理论、多道程序设计技术及进程理论的更多相关文章
- 2016年11月17日 星期四 --出埃及记 Exodus 20:8
2016年11月17日 星期四 --出埃及记 Exodus 20:8 "Remember the Sabbath day by keeping it holy.当记念安息日,守为圣日.
- python笔记8 socket(TCP) subprocess模块 粘包现象 struct模块 基于UDP的套接字协议
socket 基于tcp协议socket 服务端 import socket phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 买 ...
- 2016年11月17日--SQL主、外键,子查询
主键 数据库主键是指表中一个列或列的组合,其值能唯一地标识表中的每一行.这样的一列或多列称为表的主键,通过它可强制表的实体完整性.当创建或更改表时可通过定义 PRIMARY KEY约束来创建主键.一个 ...
- 2016年11月26日 星期六 --出埃及记 Exodus 20:17
2016年11月26日 星期六 --出埃及记 Exodus 20:17 "You shall not covet your neighbor's house. You shall not c ...
- 2016年11月1日 星期二 --出埃及记 Exodus 19:17
2016年11月1日 星期二 --出埃及记 Exodus 19:17 Then Moses led the people out of the camp to meet with God, and t ...
- 西安Uber优步司机奖励政策(1月11日~1月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 2014年11月17~11月18日,杨学明老师《企业IT需求收集和实施》内训在湖南长沙某酒店成功举办!
2014年11月17至18日,受湖南某软件企业的邀请,杨学明老师<企业IT需求收集和实施>内训在某长沙某五星级酒店成功举办!来自全国各地的IT高管和企业负责人参加了此次培训.杨学明老师分别 ...
- 优步UBER司机全国各地奖励政策汇总 (4月11日-4月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 全国Uber优步司机奖励政策 (1月11日-1月17日)
本周已经公开奖励整的城市有:北 京.成 都.重 庆.上 海.深 圳.长 沙.佛 山.广 州.苏 州.杭 州.南 京.宁 波.青 岛.天 津.西 安.武 汉.厦 门,可按CTRL+F,搜城市名快速查找. ...
- 武汉Uber优步司机奖励政策(1月11日~1月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
随机推荐
- Java8新特性:函数式编程
1. 概述 函数式编程学习目的: 能够看懂公司里的代码 大数据量下处理集合效率更高 代码可读性高 消灭嵌套地狱 函数式编程思想: 面向对象思想需要关注用什么对象完成什么事情.而函数式编程思想就类似于我 ...
- ElasticSearch 常见问题
ElasticSearch 常见问题 丈夫有泪不轻弹,只因未到伤心处. 1.说说 es 的一些调优手段. 仅索引层面调优手段: 1.1.设计阶段调优 (1)根据业务增量需求,采取基于日期模板创建索引, ...
- Json web token(JWT)攻防
免责声明: 本文章仅供学习和研究使用,严禁使用该文章内容对互联网其他应用进行非法操作,若将其用于非法目的,所造成的后果由您自行承担,产生的一切风险与本文作者无关,如继续阅读该文章即表明您默认遵守该内容 ...
- scrapy框架命令
scrapy startproject #创建scrapy项目 scrapy genspider test www.baidu.com #在项目下的spider目录下生成爬虫文件 test爬虫名称 w ...
- 初学RNN
FNN 定义 FNN(Feedforward Neural Network),即前馈神经网络,它是网络信息单向传递的一种神经网络,数据由输入层开始输入,依次流入隐藏层各层神经元,最终由输出层输出.其当 ...
- day25 前端
https://www.dcloud.io/hbuilderx.html 下载HbuilderX,直接解压缩双击打开 html5 <!DOCTYPE html><!-- 文档类型,声 ...
- 有来实验室|第一篇:Seata1.5.2版本部署和开源全栈商城订单支付业务实战
在线体验:Seata实验室 一. 前言 相信 youlai-mall 的实验室大家有曾在项目中见到过,但应该都还处于陌生的阶段,毕竟在此之前实验室多是以概念般的形式存在,所以我想借着此次的机会,对其进 ...
- C++面向对象程序设计期末复习笔记[吉林大学](结合历年题速成85)
1.头文件 头文件的作用就是被其他的.cpp包含进去的.它们本身并不参与编译,但实际上,它们的内容却在多个.cpp文件中得到了编译.根据"定义只能一次"原则我们知道,头文件中不能放 ...
- 二阶段目标检测网络-FPN 详解
论文背景 引言(Introduction) 特征金字塔网络 FPN FPN网络建立 Anchor锚框生成规则 实验 代码解读 参考资料 本篇文章是论文阅读笔记和网络理解心得总结而来,部分资料和图参考论 ...
- java逻辑运算中异或^
本文主要阐明逻辑运算符^(异或)的作用 a ^ b,相异为真,相同为假. 注意,异或运算,还能交换两个变量. int a = 1; int b = 2; System.out.println(&quo ...