03初识MapReduce
初识MapReduce
一、什么是MapReduce
MapReduce是一种编程范式,它借助Map将一个大任务分解成多个小任务,再借助Reduce归并Map的结果。MapReduce虽然原理很简单,但是使用MapReduce设计出一个解决问题的应用却不是一件简单的事情。下面通过一个简单的小例子来介绍MapReduce。
二、使用MapReduce寻找销售人员业绩最大值
《Hadoop权威指南》的例子是寻找天气最大值,需要去下载数据。但是我们并不需要完全复刻他的场景,所以这里用了另外一个例子。假设有一批销售日志数据文件,它的一部分是这样的。
66$2021-01-01$5555
67$2021-01-01$5635
每一行代表某一位销售人员某个日期的销售数量,具体格式为
销售用户id$统计日期$销售数量
我们需要寻找每一个销售用户的销售最大值是多少。需要说明的是,这里仅仅是举一个很简单的示例,便于学习MapReduce。
1、数据解析器
我首先写了一个解析器来识别每一行的文本,它的作用是将每一行文本转换为数据实体,数据实体这里偷了个懒,字段全部设置成了public。代码片段如下:
/**
* 销售数据解释器
* 销售数据格式为
* userId$countDate(yyyy-MM-dd)$saleCount
*/
public class SaleDataParse implements TextParse<SaleDataEntity> {
@Override
public SaleDataEntity parse(String text) {
if (text == null) {
return null;
}
text = text.trim();
if (text.isEmpty()) {
return null;
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String[] split = text.split("\\$");
SaleDataEntity data = new SaleDataEntity();
data.userId = Long.valueOf(split[0]);
data.countDate = sdf.parse(split[1], new ParsePosition(0));
data.saleCount = Integer.valueOf(split[2]);
return data;
}
}
/**
* 销售数据实体
*/
public class SaleDataEntity {
/**
* 销售用户id
*/
public Long userId;
/**
* 销售日期
*/
public Date countDate;
/**
* 销售总数
*/
public Integer saleCount;
}
2、Map函数
Mapper是一个泛型类,它需要4个泛型参数,从左到右分别是输入键、输入值、输出键和输出值。也就是这样
Mapper<输入键, 输入值, 输出键, 输出值>
其中输入键和输入值的格式是由InputFormatClass决定的,关于输入格式的讨论之后会展开讨论。MapReduce默认会把文件按行拆分,然后偏移量(输入键)->行文本(输入值)的映射传递给Mapper的map方法。输出键和输出值则由用户进行指定。
这里由于是找每一个用户的最大销售数量,Mapper的功能是接收并解析每行数据。所以输出键我设成了销售人员id->销售数量的映射。所以实际的Mapper实现看起来像这样:
/**
* 解析输入的文本数据
*/
public class MaxSaleMapper extends Mapper<LongWritable, Text, LongWritable, IntWritable> {
protected TextParse<SaleDataEntity> saleDataParse = new SaleDataParse();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
SaleDataEntity data = saleDataParse.parse(s);
if (data != null) {
//写入输出给Reducer
context.write(new LongWritable(data.userId), new IntWritable(data.saleCount));
}
}
}
其中LongWritable相当于java里的long,Text相当于java里的String,IntWritable相当于java里的int。
这里你可能会想到,既然已经解析成了数据实体,为什么不直接把实体设置成输出值?因为map函数和reduce函数不一定运行在同一个进程里,所以会涉及到序列化和反序列化,这里先不展开。
3、Reduce函数
Reducer也是一个泛型类,它也需要4个参数,从左到右分别是输入键、输入值、输出键和输出值。也就是这样
Reducer<输入键, 输入值, 输出键, 输出值>
与Mapper不同的是,输入键和输入值来源于Mapper的输出,也就是Mapper实现中的context.write()。
输出键和输出值也是由用户指定,默认的输出会写到文件中,关于Reducer的输出以后会讨论。
Reducer的功能是寻找每个用户的最大值,所以Reducer的实现看起来像这样:
/**
* 查找每一个用户的最大销售值
*/
public class MaxSaleReducer extends Reducer<LongWritable, IntWritable, LongWritable, IntWritable> {
@Override
protected void reduce(LongWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int max = 0;
for (IntWritable value : values) {
if (value.get() > max) {
max = value.get();
}
}
context.write(key, new IntWritable(max));
}
}
你可能会奇怪,为什么reduce方法的第二个参数是一个迭代器。简单来说,Mapper会把映射的值进行归并,然后再传递给Reducer。
4、驱动程序
我们已经完成了map和reduce函数的实现,现在我们需要把它们组装起来。我们需要写一个Main类,它看起来像这样
public class MaxSale {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance();
job.setJarByClass(MaxSale.class);
job.setJobName("MaxSale");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxSaleMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MaxSaleReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置Reduce任务数
job.setNumReduceTasks(1);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
这里解释一下
- 首先我们创建了一个Job
- 然后设置输入目录和输出目录,它们分别是FileInputFormat.addInputPath和FileOutputFormat.setOutputPath
- 使用setMapperClass设置了map函数,setMapOutputKeyClass设置了map函数的输入键类型,setMapOutputValueClass设置了输出键类型
- 使用setReducerClass设置了reduce函数,setOutputKeyClass设置了输出键类型,setOutputValueClass设置了输出值类型
- 然后使用setNumReduceTasks设置reduce任务个数为1,每个reduce任务都会输出一个文件,这里是为了方便查看
- 最后job.waitForCompletion(true)启动并等待任务结束
5、运行结果
使用maven package打包,会生成一个jar,我生成的名字是maxSaleMapReduce-1.0-SNAPSHOT.jar。如果打包的jar有除了Hadoop的其他依赖,需要设置一下HADOOP_CLASSPATH,然后把依赖放到HADOOP_CLASSPATH目录中。
最后输入启动命令,格式为:hadoop jar 生成的jar.jar 输入数据目录 输出数据目录。这里给出我使用的命令示例:
Windows:
set HADOOP_CLASSPATH=C:\xxxxxxxxx\lib\*
hadoop jar maxSaleMapReduce-1.0-SNAPSHOT.jar input output
然后你会看到程序有如下输出,这里截取的部分:
23/01/18 12:10:29 INFO mapred.MapTask: Starting flush of map output
23/01/18 12:10:29 INFO mapred.MapTask: Spilling map output
23/01/18 12:10:29 INFO mapred.MapTask: bufstart = 0; bufend = 17677320; bufvoid = 104857600
23/01/18 12:10:29 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 20321960(81287840); length = 5892437/6553600
23/01/18 12:10:30 INFO mapred.MapTask: Finished spill 0
23/01/18 12:10:30 INFO mapred.Task: Task:attempt_local1909247000_0001_m_000000_0 is done. And is in the process of committing
23/01/18 12:10:30 INFO mapred.LocalJobRunner: map
23/01/18 12:10:30 INFO mapred.Task: Task 'attempt_local1909247000_0001_m_000000_0' done.
23/01/18 12:10:30 INFO mapred.Task: Final Counters for attempt_local1909247000_0001_m_000000_0: Counters: 17
File System Counters
FILE: Number of bytes read=33569210
FILE: Number of bytes written=21132276
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=1473110
Map output records=1473110
Map output bytes=17677320
Map output materialized bytes=20623546
Input split bytes=122
Combine input records=0
Spilled Records=1473110
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=36
Total committed heap usage (bytes)=268435456
File Input Format Counters
Bytes Read=33558528
23/01/18 12:10:30 INFO mapred.LocalJobRunner: Finishing task: attempt_local1909247000_0001_m_000000_0
23/01/18 12:10:30 INFO mapred.LocalJobRunner: Starting task: attempt_local1909247000_0001_m_000001_0
23/01/18 12:10:30 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
23/01/18 12:10:30 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
等待程序执行结束,output文件夹会有输出part-r-00000,文件里每一行是每一个用户的id和他销售最大值。
0 9994
1 9975
2 9987
3 9985
4 9978
5 9998
三、MapReduce执行流程
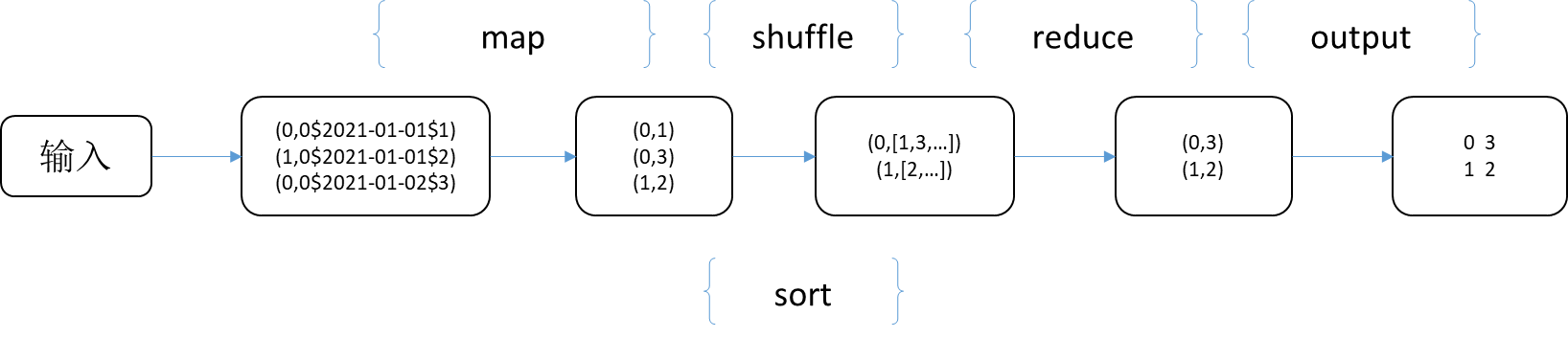
简单分析一下这个示例程度的执行流程:
- 首先输入文件被按行切分,输入到各个maper
- maper的输出按输出键进行分类,经过shuffle操作后输入到reducer
- reducer收到maper的输出后,执行寻找最大值操作,然后输出
- 输出会被默认的输出格式格式化后输出到文件part-r-00000中
四、示例代码说明
本文所有的代码放在我的github上,地址是:https://github.com/xunpengliu/hello-hadoop
下面是项目目录说明:
- maxSaleMapReduce模块是Map函数和Reduce的实现,这个模块依赖common模块。所以运行的时候需要把common模块生成的jar添加到HADOOP_CLASSPATH中
- common模块是公共模块,里面有一个SaleDataGenerator的数据生成器,可以生成本次示例代码使用的生成数据
最后需要说明的是,项目代码主要用于学习,代码风格并非代表本人实际风格,不完善之处请轻喷。
五、常见问题
java.lang.RuntimeException: java.io.FileNotFoundException: Could not locate Hadoop executable: xxxxxxxxxxxx\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
这个是因为没有下载winutils.exe和hadoop.dll,具体可以参考《安装一个最小化的Hadoop》中windows额外说明
运行出现异常java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702) ......
这个和问题1类似,Hadoop在Windows需要winutils.exe和hadoop.dll访问文件,这两个文件通过org.apache.hadoop.util.Shell#getQualifiedBinPath这个方法获取,而这个方法又依赖Hadoop的安装目录。
设置HADOOP_HOME环境变量,或者传入系统参数hadoop.home.dir为Hadoop程序目录,具体参见《安装一个最小化的Hadoop》
03初识MapReduce的更多相关文章
- Hadoop学习笔记—4.初识MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
- 初识MapReduce
MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来说,自己完完全全实现一个并行计算程序难 ...
- Hadoop点滴-初识MapReduce(2)
术语: job(作业):客户端需要执行的一个工作单元,包括输入数据.MP程序.配置信息 Hadoop将job分成若干task(任务)来执行,其中包括两类任务:map任务.reduce任务.这些任务在集 ...
- Linux学习笔记03—初识Linux
命令介绍 忘记root密码的处理方法 系统安装盘的救援模式的使用 一.命令介绍 1.LS命令 ls 查看当前目录下的文件 Ls –l 等同于ll 查看目录的详细信息 Ls –a 查看当前目录下的所有文 ...
- Hadoop点滴-初识MapReduce(1)
分析气候数据,计算出每年全球最高气温(P25页) Map阶段:输入碎片数据,输出一系列“单键单值”键值对 内部处理,将一系列“单键单值”键值对转化成一系列“单键多值”键值对 Reduce阶段,输入“单 ...
- 前端知识(一)03 初识 ECMAScript 6-谷粒学院
目录 一.ECMAScript 6 1.什么是 ECMAScript 6 2.ECMAScript 和 JavaScript 的关系 二.基本语法 1.let声明变量 2.const声明常量(只读变量 ...
- 对于Hadoop的MapReduce编程makefile
根据近期需要hadoop的MapReduce程序集成到一个大的应用C/C++书面框架.在需求make当自己主动MapReduce编译和打包的应用. 在这里,一个简单的WordCount1一个例子详细的 ...
- 指导手册05:MapReduce编程入门
指导手册05:MapReduce编程入门 Part 1:使用Eclipse创建MapReduce工程 操作系统: Centos 6.8, hadoop 2.6.4 情景描述: 因为Hadoop本身 ...
- 如何在maven项目里面编写mapreduce程序以及一个maven项目里面管理多个mapreduce程序
我们平时创建普通的mapreduce项目,在遍代码当你需要导包使用一些工具类的时候, 你需要自己找到对应的架包,再导进项目里面其实这样做非常不方便,我建议我们还是用maven项目来得方便多了 话不多说 ...
- Hadoop Mapreduce 参数 (一)
参考 hadoop权威指南 第六章,6.4节 背景 hadoop,mapreduce就如MVC,spring一样现在已经是烂大街了,虽然用过,但是说看过源码么,没有,调过参数么?调过,调到刚好能跑起来 ...
随机推荐
- Redis 01: 非关系型数据库 + 配置Redis
数据库应用的发展历程 单机数据库时代:一个应用,一个数据库实例 缓存时代:对某些表中的数据访问频繁,则对这些数据设置缓存(此时数据库中总的数据量不是很大) 水平切分时代:将数据库中的表存放到不同数据库 ...
- 三、redis环境安装
三.redis环境安装 3.1.下载和安装 下载地址:https://github.com/tporadowski/redis/releases 使用以下命令启动redis服务端 redis-se ...
- Sublime Text 修改默认语言为Python
Sublime Text 3 修改默认语言为Python 步骤如下 英文:Tools - Developer - New Plugin 中文:工具 - 插件开发 - 新建插件 清空原来内容,用下面的代 ...
- element-plus 消息提示
用来显示「成功.警告.消息.错误」类的操作 <template> <el-button :plain="true" @click="open2" ...
- Java开发学习(四十)----MyBatisPlus入门案例与简介
一.入门案例 MybatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在简化开发.提供效率. SpringBoot它能快速构建Spring开发环境用以整合其他技术,使用起来 ...
- 抓包整理————ip 协议一[十二]
前言 简单介绍一下ip协议. 正文 先来看下ip协议在网络层的哪一层: 应用层 表示层 会话层 传输层 网络层 数据链路层 物理层 ip 层就在网络层: 其实很好想象哈,就是因为每台机器起码有一个ip ...
- Go语言核心36讲25
你好,我是郝林,今天我分享的主题是:测试的基本规则和流程(上). 你很棒,已经学完了本专栏最大的一个模块!这涉及了Go语言的所有内建数据类型,以及非常有特色的那些流程和语句. 你已经完全可以去独立编写 ...
- 核磁共振成像学习笔记——从FID信号到K空间
在理想磁场环境下(没有不存在场不均匀性),对于一个没有梯度场的方块. 此时,RF pulse的两路正交信号(相位差为90°)对此方块进行激发,然后收取信号,我们可以得到由此方块产生的FID信号. 设此 ...
- <三>使用类模板实现STL Vector
使用类模板实现STL Vector,点击查看代码 #include <iostream> using namespace std; template<typename T> c ...
- [排序算法] 直接/折半插入排序 (C++)
插入排序解释 插入排序很好理解,其步骤是 :先将第一个数据元素看作是一个有序序列,后面的 n-1 个数据元素看作是未排序序列.对后面未排序序列中的第一个数据元素在这个有序序列中进行从后往前扫描,找到合 ...