2.6:Python数据存取-文件、文件夹及目录、数据库
一、Python文件读写
1、文件的打开模式

<class '_io.TextIOWrapper'>和<class '_io.BufferedReader'>。python使用 with as语句来进行文件打开后的自动关闭处理。使用了with as之后,用户可以不用显式调用文件对象的close方法来关闭文件。Python打开文件的函数是open,其核心参数是文件名称和打开模式。默认是“rt”,也就是read和text,读文本文件模式。如果设定rb,即读二进制binary模式,返回的Wrapper对象是不同的,一个是TextIOWrapper类型,一个是BufferedReader类型。
2、文件读取
Demo1.txt的内容为:文本“Beijing Institute Of Technology”分4行显示。
3、文件打开与写入


writelines方法把一个列表内容直接按顺序写入文件deomo2.txt,不会自动为列表元素添加回车换行。如果需要写入文件时各元素换行排列,这应该手工为每个元素的后面加上回车换行。可以采用列表推导式:fo.writelines([line+"\n" for line in s])。
4、批量存入文件

输出结果:Beijing Institute of Technology is a comprehensive university in Beijing(桌面文件Demo3.txt中)。可以使用文件的write方法多次批量写入数据。这种方法在实际中应用很广泛,比如对一个大文件读取切割成大小相同或特定长度的子文件等。检测条件:桌面有文件Demo3.txt,其内容为: Beijing Institute of Technology is a comprehensive university in Beijing
5、移动指针

输出结果:ChinabuildingForbidden city(桌面文件Demo4.txt中)。首先,列表中的元素没有回车换行,所以会把“GreatbuildingForbidden city”写入文件。但seek(0)把指针重新移到文件头部,然后写入“China”。因此,“China”会覆盖“Great”。seek的参数为:0:文件开头; 1: 当前位置; 2: 文件结尾。
6、把模拟数据写入文件

输出结果:桌面有Demo5.txt文件,内容为十行文本(内容为随机生成)。faker是一个模拟数据生成的python库,可以设定模拟生成的语言,如中文:zh_cn,默认为英语。Faker类提供很多方法,如name返回姓名,address返回地址,email返回电子邮件等。
二、文件和文件夹处理
1、获取当前目录

输出结果:”.”和一个绝对路径。curdir属性返回current directory(当前目录),而getcwd方法则返回当前工作目录(current work directory)。chdir(newd)方法改变当前目录到指定的newd目录。
2、路径分解

输出结果:('c:\\temp\\test', 'file.txt')。split方法返回一个元组(头,尾),其中尾部是最后一个斜杠后面的内容,其他部分归头部。
3、扩展名分解

输出结果:('c:\\temp\\test\\file', '.txt')。spletext函数返回一个二元组(根,扩展),其中扩展部分是从最后一个“逗点”到最后的所有文字,忽略其中的“逗点”。扩展部分可以为空。这个方法可以获取一个文件的扩展名。
4、获取目录列表
输出结果:True,True。Mkdir方法在当前目录下生成一个text目录。然后通过isdir方法判定是否为目录。通过listdir方法可以列出某个目录下所有的文件和目录。通过使用in判定text目录是否在当前目录下。
5、目录树遍历
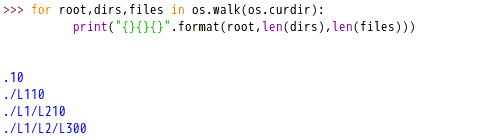
在当前文件夹下,执行os的walk方法。这个方法是一个迭代方法,对于每一级目录,返回一个三元组(root,dirs,files),分别表示当前目录的根目录,子目录和文件。迭代输出每一级目录下的根目录,文件夹数和文件数量。
6、使用GLOB库进行文件查找
import osimport glob
if "text" not in os.listdir(os.curdir):
os.mkdir("text")
os.chdir("text")
os.makedirs("L1/L2/L3")
for root,dirs,files in os.walk(os.curdir):
with open(str(root)+".txt","w+") as f:
pass
files=glob.glob("*/*.txt")
print(files)

输出结果:['L1/L2.txt']。在当前目录下生产text目录。然后切换到text目录,使用walk方法,在每个目录下生成txt文件。然后查找后缀为txt的所有文件。星号表示全匹配,问号表示匹配单字,[0-9]表示匹配0-9个数字。
7、文件拷贝
输出结果:success。在当前目录下新建一个文件from.txt,然后判定当前文件创建成功之后,使用shutil的拷贝命令,将文件拷贝到同级目录下,并改名为to.txt。确认to.txt文件存在之后,打印出成功的信息:拷贝成功。
8、文件打包

输出结果:压缩成功。在上述目录中,执行压缩代码,可以将text目录下的所有内容压缩为一个zip包,名字为textpack.zip,并存放在当前目录下。通过in判断是否压缩生成所需压缩包,然后输出成功信息。
三、SQLite3数据库存取
1、新建数据库
import os
import sqlite3

输出结果:数据创建成功。连接对象可以是硬盘上面的数据库文件,也可以是建立在内存中的。创建在硬盘: conn = sqlite3.connect(‘test.db');创建在内存: conn = sqlite3.connect(‘:memory:’)。
2、新建数据库表与数据插入与查询
import os
import sqlite3
from faker import Faker
f=Faker("zh_cn")
conn =sqlite3.connect("test.db")
c = conn.cursor()
c.execute("create table if not exists user (id varchar(20) primary key, name varchar(20))")
for i in range(0,100):
c.execute("insert into user (id, name) values ('{}','{}')".format(i,f.name()))

输出结果:共有100条数据,类型是<class 'list'>。创建游标之后,执行数据库建表的SQL命令,生成主键为id的user表。然后插入100条模拟数据。最后执行select查询命令,获取数据,并通过fetchall函数,返回一个python的列表,以便进一步的处理。
3、修改数据
import os
import sqlite3
from faker import Faker
f=Faker("zh_cn")
conn =sqlite3.connect("test.db")
c = conn.cursor()
c.execute("create table if not exists user (id varchar(20) primary key, name varchar(20))")
for i in range(0,100):
c.execute("insert into user (id, name) values ('{}','{}')".format(i,f.name()))
c.execute("update user set name='Caocao' where id==0")
c.execute("select * from user where id==0")
r2=c.fetchone()
print("{}".format(r2))

输出结果:('0', '曹操')。通过SQL命令:update进行更新,并输出更新后的数据。
4、删除数据
conn =sqlite3.connect("test.db")
c = conn.cursor()
c.execute("create table if not exists user (id varchar(20) primary key, name varchar(20))")
for i in range(0,100):
c.execute("insert into user (id, name) values ('{}','{}')".format(i,f.name()))
c.execute("select * from user")
r1=c.fetchall()
c.execute("delete from user where id==3")
c.execute("select * from user")
r2=c.fetchall()
print("{}:{}".format(len(r1),len(r2)))

结果输出:99:99。通过SQL语句delete from 删除了第3条记录,然后对删除前后的记录总数,判定删除成功。
2.6:Python数据存取-文件、文件夹及目录、数据库的更多相关文章
- Python数据生成pdf文件
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- python 数据写入json文件时中文显示Unicode编码问题
一.问题描述 import json dir = { '春晓':'asfffa', '春眠不觉晓' : '处处闻啼鸟', '夜来风雨声' : 56789, 'asdga':'asdasda' } fp ...
- Python——数据交换格式简要
简单数据交换格式 CSV: 一般用 open() 函数和字符串拆分 split() 方法,但python有内置的csv模块 读: import csv with open(r"C:\ ...
- Python数据抓取技术与实战 pdf
Python数据抓取技术与实战 目录 D11章Python基础1.1Python安装1.2安装pip1.3如何查看帮助1.4D1一个实例1.5文件操作1.6循环1.7异常1.8元组1.9列表1.10字 ...
- python数据储存
python数据储存 csv文件的操作 安装csv包打开cmd 执行 pip install csv引入的模块名为csv 读取文件 with open("xx.csv"," ...
- python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 python操作txt文件中 ...
- Python数据写入csv格式文件
(只是传递,基础知识也是根基) Python读取数据,并存入Excel打开的CSV格式文件内! 这里需要用到bs4,csv,codecs,os模块. 废话不多说,直接写代码!该重要的内容都已经注释了, ...
- python批量处理excel文件数据
https://www.zhihu.com/question/39299070?sort=created 作者:水中柳影链接:https://www.zhihu.com/question/392990 ...
- Python模糊查询本地文件夹去除文件后缀(7行代码)
Python模糊查询本地文件夹去除文件后缀 import os,re def fuzzy_search(path): word= input('请输入要查询的内容:') for filename in ...
- Python 学习 第十三篇:数据的读写-文件、DataFrame、json
Python的文件是一个重要的对象,使用open()函数来打开文件,创建文件对象,进行文件的读写操作.当数据用于交换信息时,通常需要把数据保存为有格式的文本数据,可以保存为有特定的行分隔符和列分隔符的 ...
随机推荐
- Django ORM 事务和查询优化
一.事务操作 模块 from django.db import transaction 1 开启事务:with transaction.atomic() from django.db import t ...
- 怎样编写正确、高效的 Dockerfile
基础镜像 FROM 基础镜像 基础镜像的选择非常关键: 如果关注的是镜像的安全和大小,那么一般会选择 Alpine: 如果关注的是应用的运行稳定性,那么可能会选择 Ubuntu.Debian.Cent ...
- Kibana:在Kibana 中定制 time picker 及 指标可视化显示格式
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/107066779
- centos7使用yum方式安装node_exporter
官网下载地址:https://prometheus.io/download/ 选择对应的系统版本 官网提供的是压缩包,点击旁边的github地址 github页面显示的有yum安装和docker安装, ...
- ExceptionHandler配合RestControllerAdvice全局处理异常
Java全局处理异常 引言 对于controller中的代码,为了保证其稳定性,我们总会对每一个controller中的代码进行try-catch,但是由于接口太多,try-catch会显得太冗杂,s ...
- 一天五道Java面试题----第十天(简述Redis事务实现--------->负载均衡算法、类型)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1.简述Redis事务实现 2.redis集群方案 3.redis主从复制的核心原理 4.CAP理论,BASE理论 5.负 ...
- 齐博x1如何调试查找全站的表单提交接口参数
H5.PC.WAP端的所有提交POST表单操作都是可以当作接口来用的. 比如我们通过PC或WAP浏览器打开相应要修改的界面,然后浏览器进入开发者模式,就可以追踪到所提交的变量参数.你在APP里边只要指 ...
- 二进制安装Dokcer
写在前边 考虑到很多生产环境是内网,不允许外网访问的.恰好我司正是这种场景,写一篇二进制方式安装Docker的教程,用来帮助实施同事解决容器部署的第一个难关. 本文将以二进制安装方式,在CentOS7 ...
- 11.pygame飞机大战游戏整体代码
主程序 # -*- coding: utf-8 -*- # @Time: 2022/5/20 22:26 # @Author: LiQi # @Describe: 主程序 import pygame ...
- 死磕面试系列,Java到底是值传递还是引用传递?
Java到底是值传递还是引用传递? 这虽然是一个老生常谈的问题,但是对于没有深入研究过这块,或者Java基础不牢的同学,还是很难回答得让人满意. 可能很多同学能够很轻松的背出JVM.分布式事务.高并发 ...